注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ユニットテスト
このページに記載されている Python リポジトリのユニットテストは、バッチパイプラインにのみ適用され、ストリーミングパイプラインではサポートされていません。
Pythonリポジトリでは、チェックの一部としてテストを実行するオプションがあります。これらのテストは、人気のあるPythonのテストフレームワーク、PyTest ↗を使用して実行されます。
CIタスク: condaPackRun
すべてのCIチェックには、他のタスクと一緒に、condaPackRunが含まれています。
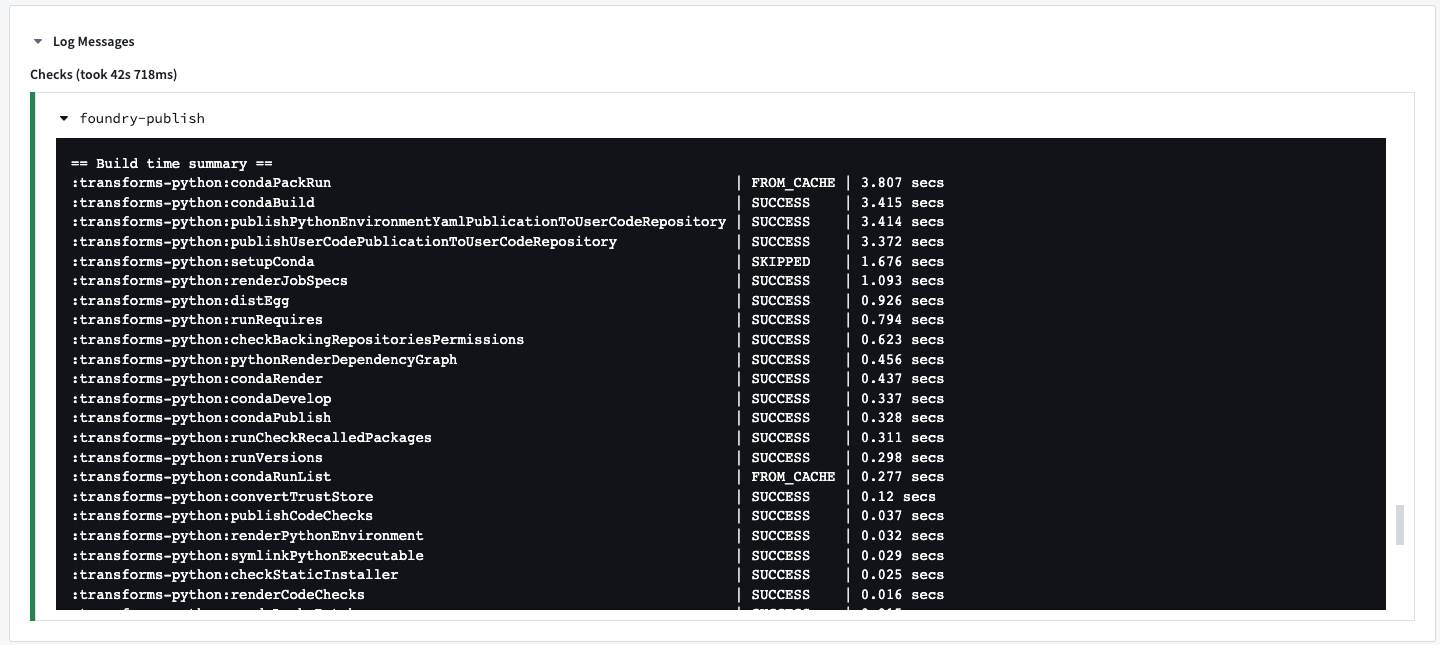
condaPackRunは環境のインストールを担当します。各作成物は適切なチャネルから取得され、Condaはこれらの作成物を使用して環境を構築します。このタスクには3つのステージがあります:
- 解決した環境のすべてのパッケージをダウンロードし、展開します。
- パッケージの内容を確認します。設定により、Condaはチェックサムを使用するか、ファイルサイズが正しいことを確認します。
- パッケージを環境にリンクします。
環境の仕様は、次のビルドのキャッシュとして、以下の隠しファイルに格納されます:
- conda-version-run.linux-64.lock
- conda-version-test.linux-64.lock
キャッシュは7日間保持されます。meta.yamlファイルに何らかの変更があると再キャッシュされます。
このタスクは、リポジトリに追加されるパッケージの数に大きく依存しています。パッケージが多く追加されれば追加されるほど、タスクの実行は遅くなります。
スタイルチェックの有効化
PEP8 / PyLint スタイルチェックは、Pythonプロジェクトのbuild.gradleファイルで com.palantir.conda.pep8 および com.palantir.conda.pylint Gradleプラグインを適用することで有効にできます。トランスフォームリポジトリでは、これはPythonサブプロジェクトに存在します。ライブラリリポジトリでは、これはルートフォルダーに存在します。
トランスフォームのbuild.gradleは次のようになります:
Copied!1 2 3 4 5 6 7 8 9 10 11 12apply plugin: 'com.palantir.transforms.lang.python-library' apply plugin: 'com.palantir.transforms.lang.python-library-defaults' // Pythonライブラリプラグインを適用 apply plugin: 'com.palantir.transforms.lang.python-library' apply plugin: 'com.palantir.transforms.lang.python-library-defaults' // テストプラグインを適用 apply plugin: 'com.palantir.transforms.lang.pytest-defaults' // タグ付きリリースのみ公開(最後のgitタグからのコミット数が0の場合) condaLibraryPublish.onlyIf { versionDetails().commitDistance == 0 }
meta.yamlで定義されたランタイム要件はユーザーのテストで利用可能です。追加の要件もconda test section ↗で指定できます。
テストの作成
完全なドキュメンテーションはhttps://docs.pytest.org ↗で見つけることができます。
PyTest は、test_で始まるまたは_test.pyで終わる任意の Python ファイルのテストを見つけます。ユーザーのプロジェクトのsrcディレクトリー下のtestパッケージにすべてのテストを配置することを推奨します。テストはtest_プレフィックスで名前付けられた Python 関数であり、アサーションは Python のassertステートメントを使用して作成されます。PyTest は Python の組み込みのunittest ↗モジュールを使用して書かれたテストも実行します。
例えば、transforms-python/src/test/test_increment.pyでの簡単なテストは次のようになります:
PySpark でのテスト
PyTest fixtures ↗ は、同じ名前のパラメーターを追加するだけでテスト関数に値を注入できる強力な機能です。
この機能は、ユーザーのテスト関数で使用するための spark_session フィクスチャを提供するために使用されます。例えば:
最終的なリポジトリの構造は、以下の画像のようになります:
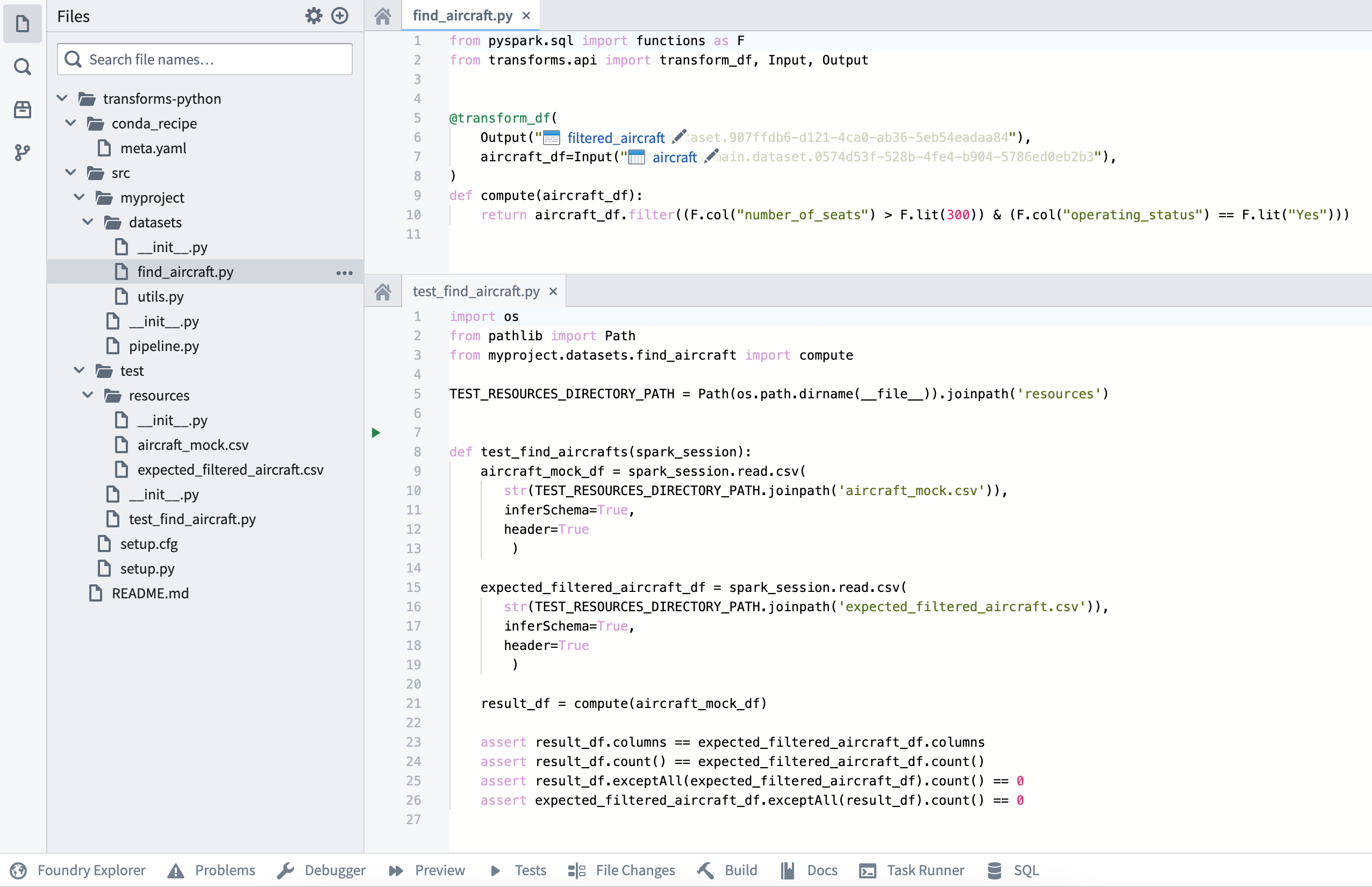
テストは transforms-python/src/test/test_find_aircraft.py に存在します。
入力と予期される出力のCSVリソースは transforms-python/src/test/resources に存在します。
transform() デコレーターで書き込まれたデータフレームのインターセプト
変換関数が transform_df の代わりに transform() で装飾されると、変換関数は結果のデータフレームを返すのではなく、関数に送られた Output オブジェクトの一つを使用して結果をデータセットに具体化します。ロジックをテストするためには、具体化される値をインターセプトするために Output 引数のモックを使用する必要があります。
上記のデータ変換が transform() デコレーターを使用するように変更されたと仮定します:
find_aircraft_transform_decorator.py
検証のテスト中、変換関数は今、aircraft_input 引数に対して Input() を期待しており、result_df の値を results_output に送る必要があります。
MagicMock ↗ は、両方のインスタンスに必要なラッパーを作成するために使用できます。
test_find_aircraft_transform_decorator.py
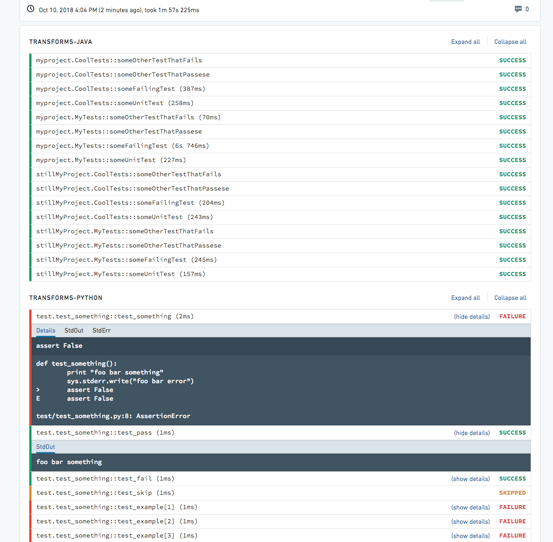
テスト出力の表示
設定されたテストの出力は、Checks タブにそれぞれのテストに対する別々の出力として表示されます。デフォルトでは、テスト結果はステータス:PASSED、FAILED、または SKIPPED で折りたたまれて表示されます。各テストを展開する(またはすべてのテストを展開する)と、テスト出力と StdOut および StdErr ログが表示されます。
テストカバレッジ
PyTest coverage ↗ は、リポジトリのカバレッジを計算し、最小パーセンテージを適用するために使用できます。
リポジトリの meta.yml に以下を追加してください:
テストの並列化は、テストプラグイン pytest-xdist ↗ を使用して実行されます。
テストを並列化すると、保留中のテストが利用可能なワーカーに送信されますが、順序は保証されません。グローバル/共有状態を必要とし、先行する他のテストによる変更を予期する任意のテストは、それに応じて調整されるべきです。
ヒント
- これらのテストを有効にした後、コミットするとCIログで
:transforms-python:pytestタスクが実行されることが確認できます。 - テストは、ファイル名と関数名の両方の先頭に
test_があることに基づいて発見されます。これはPyTestの標準的な規約です。 - 例のレコードを素早く取得する方法は、Code Workbook コンソールでデータセットを開き、
.collect()を呼び出すことです。 - Python形式のスキーマを取得するには、データセットのプレビューを開き、その後 行 タブを開き、 コピー をクリックしてから PySparkスキーマをコピー をクリックします。