注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Spark sidecar 変換
Spark sidecar 変換により、Spark と変換が提供する既存のインフラストラクチャを活用しながら、コンテナ化されたコードをデプロイすることができます。
コードをコンテナ化することで、任意のコードとその依存関係を Foundry で実行するためのパッケージを作成できます。コンテナ化のワークフローは変換と統合されており、スケジューリング、ブランチング、データ健全性がすべてシームレスに統合されています。コンテナ化されたロジックは Spark エグゼキューターと並行して実行されるため、入力データに合わせてコンテナ化されたロジックをスケールアップすることができます。
つまり、コンテナで実行できる任意のロジックを用いて、Foundry でデータを処理したり、生成したり、消費したりすることができます。
コンテナ化の概念に慣れている方は、以下のセクションを参照して、Spark sidecar 変換の使用方法について詳しく学びましょう:
アーキテクチャ
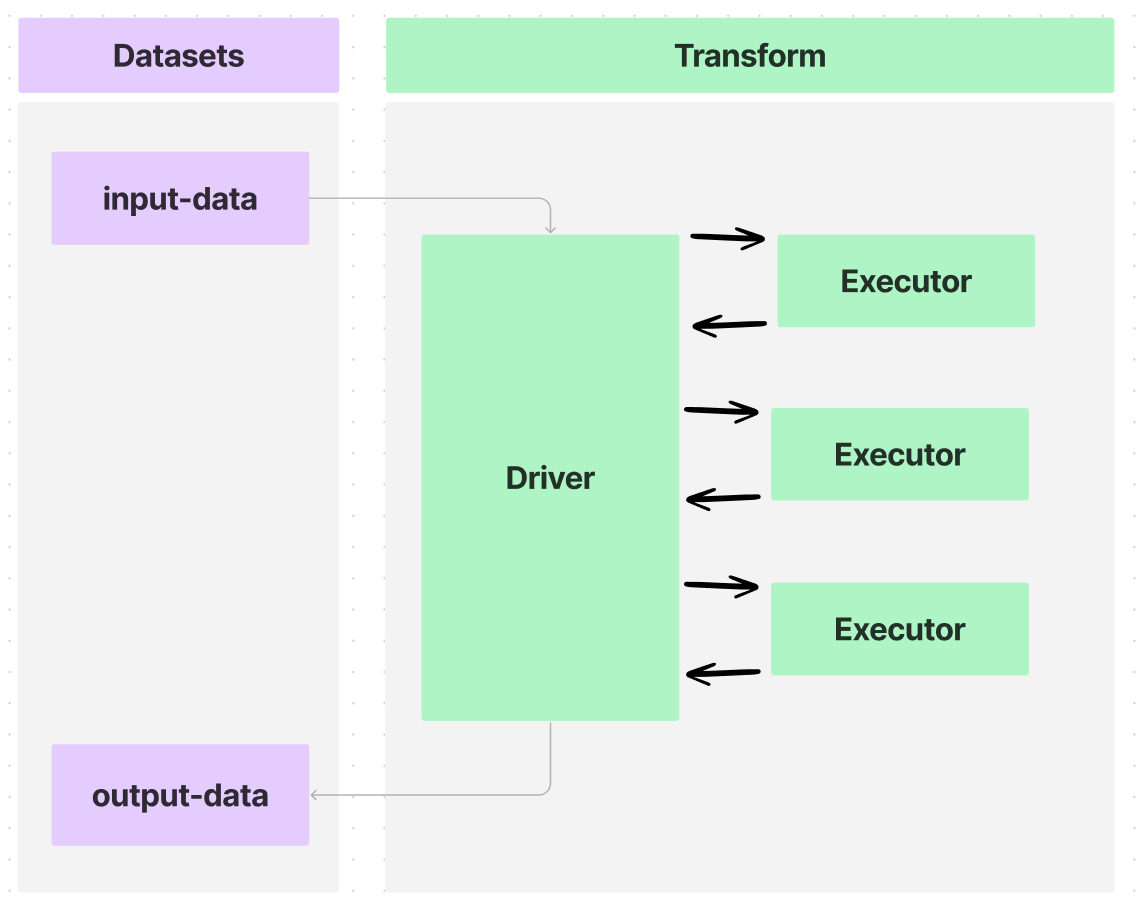
Foundry の変換では、Spark ドライバーを使用してデータをデータセット間で送受信し、処理を複数のエグゼキューターに分散させることができます。下の図に示すように:
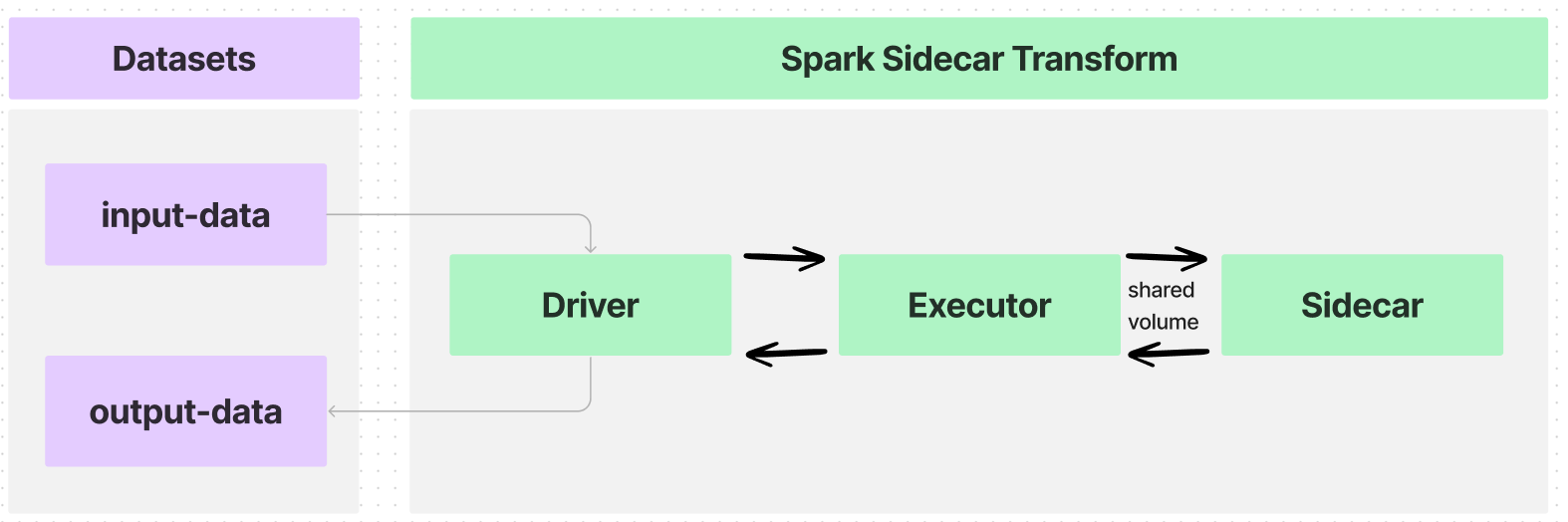
変換に @sidecar デコレーター(transforms-sidecar ライブラリで提供)を注釈付けすると、PySpark 変換の各エグゼキューターと並行して起動する正確に一つのコンテナを指定できます。カスタムロジックを持つユーザー提供のコンテナが各エグゼキューターと並行して実行され、これを sidecar コンテナと呼びます。
一つのエグゼキューターを持つ簡単な使用例では、データフローは次のようになります:
入力データセットを多数のエグゼキューターにパーティション化する変換を作成した場合、データフローは次のようになります:
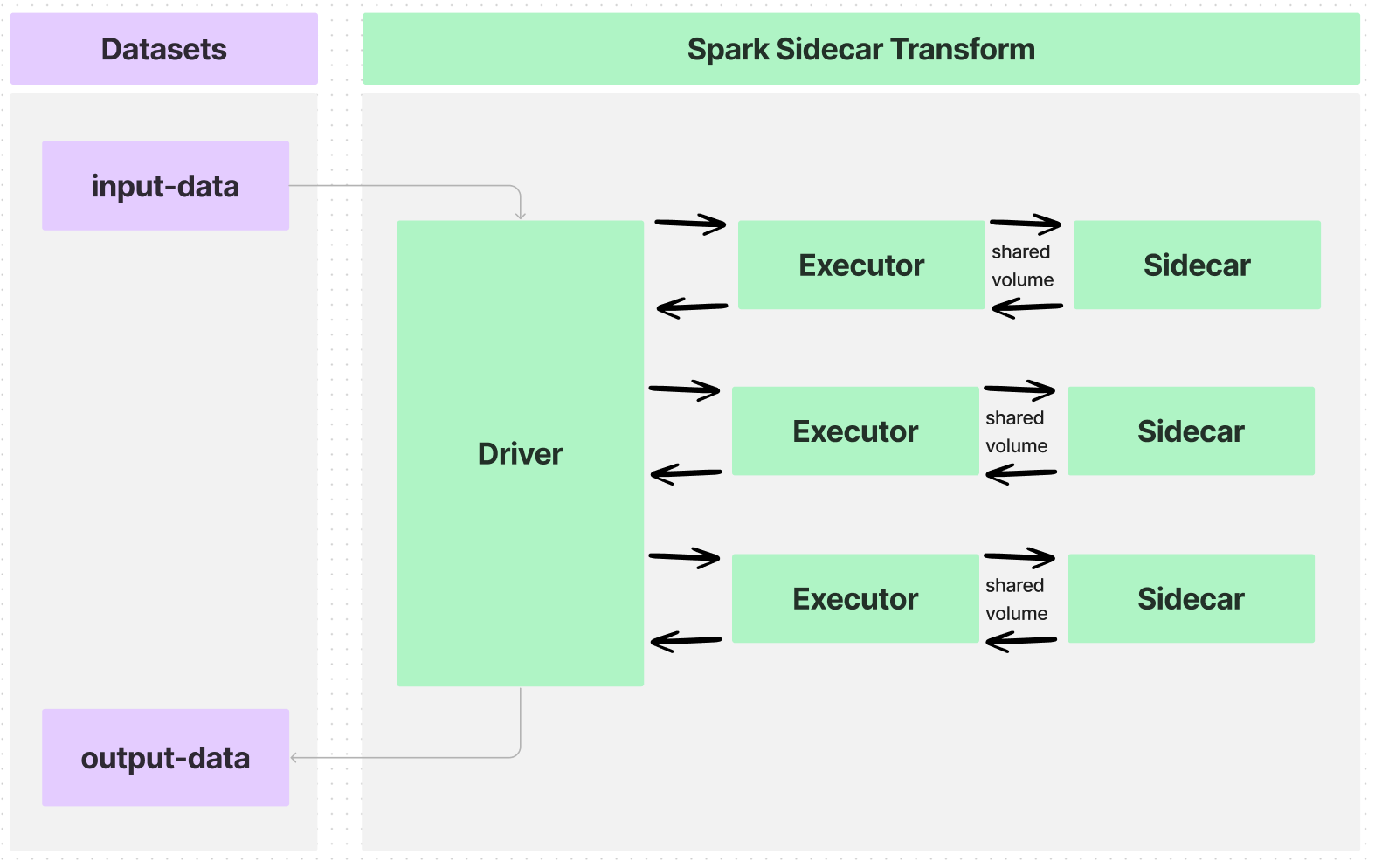
エグゼキューターと sidecar コンテナ間のインターフェースは共有ボリューム、またはディレクトリで、以下のような情報を通信します:
- コンテナ化されたロジックの実行を開始するタイミング。
- コンテナで処理する入力データ。
- コンテナから取り出す出力データ。
- コンテナ化されたロジックの実行を終了するタイミング。
これらの共有ボリュームは、@sidecar デコレーターの Volume 引数を使用して指定され、パス /opt/palantir/sidecars/shared-volumes/ 内のサブフォルダーとなります。
次のセクションでは、Spark sidecar 変換の準備と作成方法について説明します。
イメージのビルド
Spark sidecar 変換と互換性のあるイメージをビルドするためには、イメージは イメージ要件 を満たしていなければなりません。また、イメージは以下で説明する重要なコンポーネントを含んでいる必要があり、これらは例の Docker イメージに含まれています。この例のイメージをビルドするには、Python スクリプト entrypoint.py が必要です。
ローカルのコンピューターに Docker をインストールし、docker CLI コマンド (公式ドキュメンテーション ↗) にアクセスできる必要があります。
Dockerfile
ローカルのコンピューターのフォルダーに、以下の内容を Dockerfile という名前のファイルに入れてください:
カスタマイズした Dockerfile
上記のように、ユーザーの Dockerfile を作成することができますが、以下の点を確認してください:
-
行 10 で数値の非 root ユーザーを指定します。これは イメージ要件 の1つで、コンテナに特権実行が与えられないようにするための適切なセキュリティポジチャーを維持するためのものです。
-
次に、行 6-8 で共有ボリュームの作成を配置します。上記の アーキテクチャセクション で議論されたように、
/opt/palantir/sidecars/shared-volumes/内のサブディレクトリである共有ボリュームは、入力データと出力データが PySpark 変換からサイドカーコンテナに共有される主要な方法です。- 行 6 でディレクトリを作成します。
- 行 7 は、ディレクトリが作成されたユーザーにパーミッションを付与することを確認します。
- 行 8 では、この共有ディレクトリへのパスを、他の場所で参照するための環境変数として保存します。
-
最後に、行 3 でコンテナに単純な
entrypointスクリプトを追加し、行 12 でENTRYPOINTとして設定します。このステップは重要で、Spark のサイドカートランスフォームは、コンテナが起動する前に入力データが利用可能になるのを待つように、ネイティブにサイドカーコンテナに指示しないからです。さらに、サイドカートランスフォームは、出力データがコピーされるのを待つためにコンテナをアライブ状態に保つようには指示しません。提供されたentrypointスクリプトは Python を使用して、指定されたロジックが実行される前に、start_flagファイルが共有ボリュームに書き込まれるのを待つようにコンテナに指示します。指定されたロジックが終了すると、done_flagを同じディレクトリに書き込みます。コンテナは、close_flagが共有ボリュームに書き込まれるのを待つと、自己停止し自動的にクリーンアップされます。
上記の例では、コンテナ化されたロジックはPOSIX Disk Dump (dd) ユーティリティを使用して、共有ディレクトリから入力CSVファイルを同じディレクトリに保存された出力ファイルにコピーします。この「コマンド」は、コンテナで実行できる任意のロジックである可能性があり、entrypoint スクリプトに渡されます。
Entrypoint
Dockerfile と同じローカルフォルダーに、以下のコードスニペットを entrypoint.py という名前のファイルにコピーします。