注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
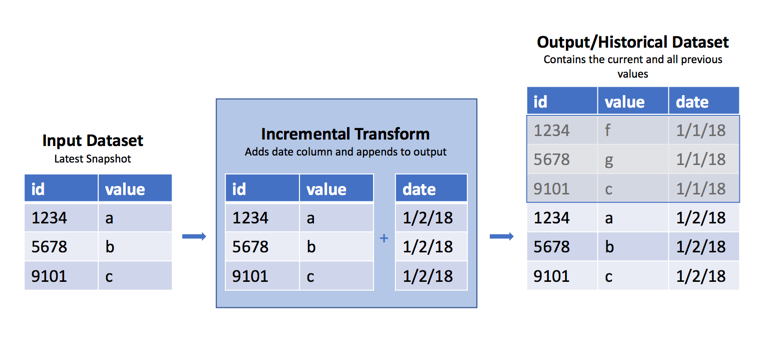
スナップショットから履歴データセットを作成する
可能な限り、このタイプのデータセットは、最初から APPEND トランザクションとして取り込むのがベストプラクティスです。詳細については、以下の警告を参照してください。
ワークフロー概要
たまに、生データセットがあって、毎日/毎週/毎時、新しい SNAPSHOT インポートが前のビューを現在のデータセットのデータで置き換えることがあります。しかし、前のデータも利用できると、前のビューから何が変わったかを判断するのに便利です。上記で述べたように、この場合のベストプラクティスは、取り込みの一部として APPEND トランザクションを使用し、インポート日付の行を追加することです。ただし、これが不可能な場合は、Pythonトランスフォームの incremental() デコレータを使用して、これらの定期的な SNAPSHOT をそのデータセットの 履歴 バージョンに追加できます。このアプローチの脆弱性に関する警告は、以下の 警告 を参照してください。
サンプルコード
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14@incremental(snapshot_inputs=['input_data']) @transform( input_data=Input("/path/to/snapshot/input"), history=Output("/path/to/historical/dataset"), ) def my_compute_function(input_data, history): input_df = input_data.dataframe() # 以下でcurrent_timestamp()も使えることに注意してください # 入力が1日に複数回変更される場合 input_df = input_df.withColumn('date', current_date()) # 履歴データセットにデータフレームを書き込む history.write_dataframe(input_df)
なぜこれが機能するのか
インクリメンタルデコレータは、入力と出力の読み取り/書き込みモードに追加のロジックを適用します。上記の例では、入力と出力のデフォルトの読み取り/書き込みモードを使用しています。
読み取りモード
SNAPSHOT入力を使用する場合、デフォルトの読み取りモードはcurrentであり、最後のトランザクション以降に追加された行ではなく、入力データフレーム全体を取得します。ただし、入力データセットがAPPENDトランザクションから作成されている場合、incremental() デコレータを使用して最後のビルド以降に追加された行のみにアクセスするためにadded読み取りモードを使用できます。
トランスフォームは、current出力からスキーマ情報を取得するため、データフレームのpreviousバージョンを読み取る場合のようにスキーマ情報を渡す必要はありません(例:dataframe('previous', schema=input.schema))。
書き込みモード
トランスフォームがインクリメンタルに実行されるということは、出力のデフォルトの書き込みモードがmodifyに設定されていることを意味します。このモードでは、ビルド中に書き込まれたデータで既存の出力を変更します。例えば、出力がmodifyモードの場合、write_dataframe()を呼び出すと、書き込まれたデータフレームが既存の出力に追加されます。これがこのケースで起こっていることです。
警告
このトランスフォームでは、入力としてSNAPSHOTデータセットを使用しているため、ビルドが失敗したり他の理由でビルドが実行されなかった場合にスナップショットを回復する方法はありません。これが懸念事項である場合は、この方法を使用しないでください。代わりに、入力データセットの所有者に連絡して、APPENDデータセットに変換して以前のトランザクションにアクセスできるかどうか確認してください。これがインクリメンタル計算が設計された方法です。
これは以下の場合に失敗します。
- 入力データセットに行が追加された場合
- 既存のテーブルの行番号が[input]データスキーマと一致しない場合
- 入力データセットの行がデータ型を変更した場合(例:
integerからdecimal) - 入力データセットを変更した場合、そのデータセットのスキーマが同一であっても。この場合、出力を入力で完全に置き換えるのではなく、追加する。
リソース消費の増加
このパターンを使用すると、履歴データセット内に小さなファイルが蓄積されることがあります。ファイルの蓄積は望ましい結果ではなく、この履歴データセットを使用する下流のトランスフォームや分析でビルド時間が増加し、リソース消費が増加することになります。バッチおよび対話型コンピューティング時間が増加する可能性があります。これは、各ファイルを読み込む際にオーバーヘッドが発生するためです。ディスク使用量が増加する可能性があります。これは、データセット内のファイル間で圧縮が行われず、ファイルごとに圧縮が行われるためです。 このような動作が発生しないように、定期的にデータの再スナップショットを作成するロジックを構築することができます。
出力ファイルの数を調べることで、最適なインクリメンタル書き込みモードを決定することができます。このモードでは、前回のトランザクションの出力をデータフレームとして読み取り、それを入力データに結合し、データファイルを一緒に結合して、多くの小さなファイルを1つの大きなファイルに変換することができます。
出力データセットのファイルシステム内のファイル数を調べ、if文を使用してwrite_modeを設定します。次の例のようにしてください:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47from transforms.api import transform, Input, Output, configure, incremental from pyspark.sql import types as T FILE_COUNT_LIMIT = 100 # 必要な出力スキーマをここに挿入してください schema = T.StructType([ T.StructField('Value', T.DoubleType()), T.StructField('Time', T.TimestampType()), T.StructField('DataGroup', T.StringType()) ]) def compute_logic(df): """ これがあなたの変換ロジックです """ return df.filter(True) @configure(profile=["KUBERNETES_NO_EXECUTORS"]) @incremental(semantic_version=1) @transform( output=Output("/Org/Project/Folder1/Output_dataset_incremental"), input_df=Input("/Org/Project/Folder1/Input_dataset_incremental"), ) def compute(input_df, output): df = input_df.dataframe('added') df = compute_logic(df) # データセットにあるファイルのリストを取得します files = list(output.filesystem(mode='previous').ls()) if (len(files) > FILE_COUNT_LIMIT): # インクリメンタルなマージと置換 previous_df = output.dataframe('previous', schema) df = df.unionByName(previous_df) mode = 'replace' else: # 標準的なインクリメンタルモード mode = 'modify' output.set_mode(mode) output.write_dataframe(df.coalesce(1))