注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ユーザー定義関数 (UDF)
Pipeline Builder の既存のトランスフォームオプションでデータを操作できない場合、外部の Java ライブラリを組み込みたい場合、またはパイプライン全体で再利用したい複雑なロジックがある場合、独自のユーザー定義関数 (UDF) を作成できます。ユーザー定義関数を使用すると、Pipeline Builder やバージョン管理およびアップグレードが可能な Code Repositories で任意の Java コードを実行できます。
ユーザー定義関数は必要な場合にのみ適用し、可能な限り既存のトランスフォームを Pipeline Builder または Java トランスフォームリポジトリ で使用することをお勧めします。
エンロールメントは、Palantir のクラウドホスト型インフラストラクチャ上にある必要があります。現在、Pipeline Builder では row map および flat map UDF のみがサポートされていますが、他のタイプのサポートも追加される予定です。ユーザー定義関数は高度な機能です。ユーザーのパイプラインでユーザー定義関数を使用する影響を理解するために、以下のドキュメントをよく確認してください。
ユーザー定義関数 (UDF) を作成する
ユーザー定義関数リポジトリを作成するには、まずリポジトリを保存したいプロジェクトに移動します。
次に、New を選択し、Code Repositiory を選択します。Foundry UDF Definitions オプションの下で、Map UDF Definition/Implementation を選択してリポジトリを UDF テンプレートでブートストラップします。最後に、Initialize repository を選択します。
ユーザーのローカル環境 (推奨) または直接 Code Repositories で作業することができます。
ローカル開発環境のセットアップ (推奨)
UDF を作成するにはローカルで作業することをお勧めします。以下の手順に従ってローカル環境をセットアップしてください。
- リポジトリをクローンするには、画面右上の Work locally を選択し、URL をコピーします。
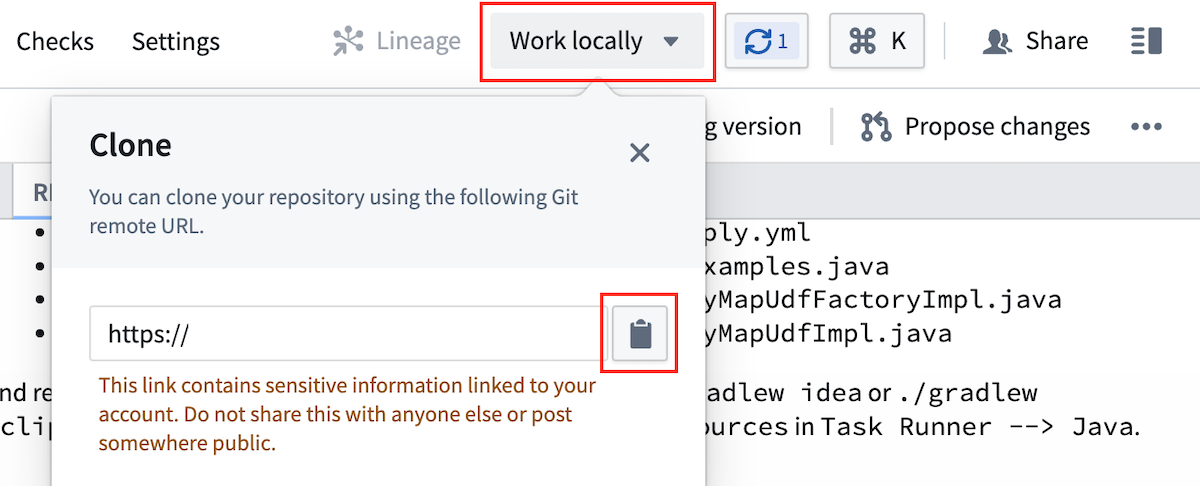
-
コマンドラインインターフェース (CLI) を開き、
git clone <repo url>を実行します。 -
次のコマンドを使用して、開発環境でプロジェクトを開きます:
- IntelliJ IDEA:
./gradlew idea open - Eclipse IDE:
./gradlew eclipse open
主な CLI コマンド:
- UDF 定義または Java 実装ファイルを編集した後にコード生成ファイルを再実行する:
- IntelliJ IDEA:
./gradlew idea - Eclipse IDE:
./gradlew eclipse
- IntelliJ IDEA:
- Pipeline Builder に公開するためのロックファイルを作成する:
./gradlew generateEddieLockfile
- テストを実行する:
- testExamples のみを実行する:
./gradlew test --tests examples.ExamplesTest.testExamples - すべてのテストを実行する:
./gradlew test
- testExamples のみを実行する:
Code Repositories 環境のセットアップ
ローカル IDE で作業できない場合は、Code Repositories でファイルを直接編集し、Task Runner で主要なコマンドを実行できます。
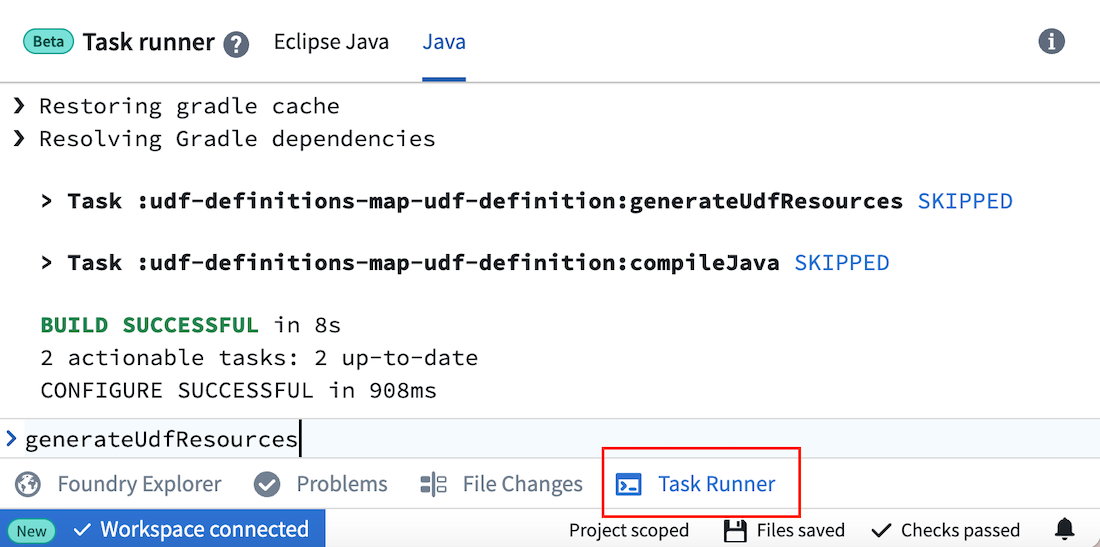
主なコマンド:
- UDF 定義または Java 実装ファイルを編集した後にコード生成ファイルを再実行する:
generateUdfResources
- Pipeline Builder に公開するためのロックファイルを作成する:
generateEddieLockfile
- テストを実行する:
- すべてのテストを実行する:
test
- すべてのテストを実行する:
ユーザー定義関数を定義する
UDF は、その名前、入力スキーマ、出力スキーマ、および引数のタイプを指定するファイルで定義されます。Java クラスはこのファイルに基づいて生成され、ファイル名は公開後に Pipeline Builder で表示されます。
新しい UDF を作成するには、次のフィールドを含む <YourUdfName>.yml というファイルを src/main/resources/udfs/definitions/ に追加します:
name: UDF の名前。コード生成により、入力、出力、および引数を説明するクラスを作成するために使用されます。この名前は、デプロイメントリポジトリのdeployment.ymlファイルでこの UDF を参照するためにも使用され、Pipeline Builder ではトランスフォームとして表示されます。customTypes(オプション):inputSchemaおよびoutputSchema定義全体で再利用できるカスタムタイプを定義するブロック。詳細は カスタムタイプ セクションを参照してください。inputSchema: UDF に対して実行するために入力行が従わなければならないスキーマ。このスキーマよりも多くの列を持つデータセットは、実行時にこのスキーマに選択できる場合に受け入れられます。コード生成により、このスキーマに対して強く型付けされた入力オブジェクトが作成されます。パラメーターは Pipeline Builder に表示されます。スキーマ定義セクション を参照してください。outputSchema: この UDF によって出力される行のスキーマ。コード生成により、このスキーマに対して強く型付けされた出力オブジェクトが作成されます。スキーマ定義セクション を参照してください。arguments: UDF のパラメーターの説明。これらの引数は、Pipeline Builder または対応するデプロイメントリポジトリのビルド時にユーザーが指定します。コード生成により、この定義に対して強く型付けされた引数オブジェクトが作成されます。
リポジトリテンプレートには、src/main/resources/udfs/definitions/Multiply.yml に例の定義が提供されています。引数の詳細は UDF 定義セクション を参照してください。
このリポジトリに複数の UDF を定義するには、src/main/resources/udfs/definitions に別の定義ファイルを追加します。
ユーザー定義関数を実装する
UDF 定義ファイルを作成または編集したら、以下のコマンドでコード生成を実行します。コード生成により、定義ファイルから強く型付けされたオブジェクトが作成され、udf-definitions-map-udf-definition/build/generated/sources/udf/main/java に配置されます。生成されたクラスには、定義のスキーマに一致する入力および出力オブジェクト、およびトランスフォーム作成およびロジックの実装のためのインターフェースが含まれます。また、YourUdfNameMapUdfFactoryImpl や YourUdfNameMapUdfImpl クラスを変更するたびにコード生成を再実行し、Java パッケージをコンパイルし、チェックが通らない場合にエラーを提供できるようにする必要があります。
ローカル環境:
- IntelliJ IDEA:
./gradlew idea - Eclipse IDE:
./gradlew eclipse
Code Repositories:
- Java Task Runner で
generateUdfResourcesを実行します。生成されたファイルは Code Repositories では表示されませんが、このコマンドはコード補完を提供します。
row map ユーザー定義関数を実装する
Row map UDF は 1 行を入力として受け取り、入力ごとに正確に 1 行を出力します。Row map はデフォルトの UDF タイプです。
UDF の作成およびトランスフォームロジックを実装するには、次のように src/main/resources/java/myproject に 2 つの新しい Java クラスファイルを作成します:
YourUdfNameMapUdfFactoryImpl.java: UDF のインスタンスを作成し、実行のためのパラメーターを提供する役割を担います。- このクラスは生成された
YourUdfNameMapUdfFactoryインターフェースを実装する必要があります。 - すべての UDF 引数は
args.config()パラメーターを通じて利用できます。 createメソッドは実行時に 1 回呼び出され、UDF をインスタンス化します。
- このクラスは生成された
YourUdfNameMapUdfImpl.java: 入力オブジェクトから出力オブジェクトへの実際のトランスフォームロジックを実装します。- このクラスは生成された
YourUdfNameMapUdfインターフェースを実装する必要があります。 - このロジックはトランスフォームを通過するすべての行に対して 1 回呼び出されます。
- 入力および出力クラスのプロパティおよび構成引数は、同じ名前のメソッド (camelCase) を使用してアクセスできます。たとえば、
argument_oneはargumentOne()という一致するメソッドを持ちます。
- このクラスは生成された
リポジトリテンプレートには、以下の Java クラスの例の実装が含まれています。これらの例を使用して独自の実装をモデル化できます。編集後にコード生成を再実行して、問題がないことを確認してください。
src/main/java/myproject/MultiplyMapUdfFactoryImpl.javasrc/main/java/myproject/MultiplyMapUdfImpl.java
flat map ユーザー定義関数を実装する
Flat map UDF は 1 行を入力として受け取り、入力ごとに 0 行、1 行、または複数行を出力できます。
Flat map UDF の作成およびトランスフォームロジックを実装するには、次の例を使用して src/main/resources/java/myproject に 2 つの新しい Java クラスファイルを作成します。
YourUdfNameFlatMapUdfFactoryImpl.java: UDF のインスタンスを作成し、実行のためのパラメーターを提供する役割を担います。
- このクラスは生成された
YourUdfNameFlatMapUdfFactoryインターフェースを実装する必要があります。 - すべての UDF 引数は
args.config()パラメーターを通じて利用できます。 createメソッドは実行時に 1 回呼び出され、UDF をインスタンス化します。
例: DuplicateRowsFlatMapUdfFactoryImpl.java
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30package myproject; import com.google.auto.service.AutoService; import com.palantir.foundry.duplicaterows.config.DuplicateRowsConfiguration; import com.palantir.foundry.duplicaterows.DuplicateRowsFlatMapUdf; import com.palantir.foundry.duplicaterows.DuplicateRowsFlatMapUdfAdapter; import com.palantir.foundry.duplicaterows.DuplicateRowsFlatMapUdfFactory; import com.palantir.foundry.udf.api.flatmap.FoundryRowFlatMapUdf; import com.palantir.foundry.udf.api.flatmap.FoundryRowFlatMapUdfFactory; /** * "ChangeMe" UDFを作成するためのファクトリークラス。 */ @AutoService(FoundryRowFlatMapUdfFactory.class) public final class DuplicateRowsFlatMapUdfFactoryImpl implements DuplicateRowsFlatMapUdfFactory { /** * サービスローディングのためにパブリックで引数なしのコンストラクタが必要です。 */ public DuplicateRowsFlatMapUdfFactoryImpl() {} /** * 実行時に使用するUDF実装を作成します。作成者は自分のUDF実装をラップするアダプターを返すべきです。 */ @Override public final FoundryRowFlatMapUdf create(FoundryRowFlatMapUdfFactory.Arguments<DuplicateRowsConfiguration> args) { DuplicateRowsFlatMapUdf impl = new DuplicateRowsFlatMapUdfImpl(args.config()); return new DuplicateRowsFlatMapUdfAdapter(impl); } }
YourUdfNameFlatMapUdfImpl.java: 入力オブジェクトから出力オブジェクトへの実際のトランスフォームロジックを実装します。
- このクラスは生成された
YourUdfNameFlatMapUdfインターフェースを実装する必要があります。 - このロジックはトランスフォームを通過するすべての行に対して 1 回呼び出されます。
- 入力および出力クラスのプロパティと構成引数は、同じ名前のメソッド(キャメルケース)でアクセスできます。たとえば、
argument_oneはargumentOne()というメソッドが対応します。
例: DuplicateRowsFlatMapUdfImpl.java
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30package myproject; import com.palantir.foundry.duplicaterows.config.DuplicateRowsConfiguration; import com.palantir.foundry.duplicaterows.DuplicateRowsFlatMapUdf; import com.palantir.foundry.duplicaterows.input.InputRow; import com.palantir.foundry.duplicaterows.output.OutputRow; import com.palantir.foundry.udf.api.flatmap.Collector; /** * Implementation for the "DuplicateRows" UDF logic. * "DuplicateRows" UDFロジックの実装。 */ public final class DuplicateRowsFlatMapUdfImpl implements DuplicateRowsFlatMapUdf { private final DuplicateRowsConfiguration config; public DuplicateRowsFlatMapUdfImpl(DuplicateRowsConfiguration config) { this.config = config; } @Override public void flatMap(Context ctx, InputRow input, Collector<OutputRow> out) throws Exception { OutputRow outputRow = OutputRow.create(ctx.getRowBuilderFactory()) .key(input.key()) .value(input.value()); // Duplicate all input rows by collecting twice // 全ての入力行を2回収集して複製する out.collect(outputRow); out.collect(outputRow); } }
行マップユーザー定義関数の例を作成する
例は特定のユーザー定義関数に関する情報を提供し、単体テストフレームワークとして使用できます。これらの例は、UDF をパイプラインにインポートする際に Pipeline Builder にも表示され、UDF の機能を理解しやすくします。例フレームワークは行マップユーザー定義関数のみをサポートしており、フラットマップユーザー定義関数については、独自に JUnit テストを書くことをお勧めします。これらは Builder トランスフォームドキュメントには表示されません。
例テストケースの定義は任意ですが、Pipeline Builder のトランスフォームドキュメントの下に表示されるため、UDF の内容を理解しやすくするために強く推奨されます。例を含めたくない場合は、src/test フォルダーを削除し、次のセクションに進んでください。
Map UDF Definition/Implementation リポジトリのデフォルトテンプレートにサンプルの Examples クラスが含まれています。
src/test/java/examples/registry/MultiplyExamples.java
新しい UDF の例を定義するには、examples.registry の下に Examples インターフェースを実装するクラスを作成します。インターフェースの期待事項については MultiplyExamples.java を参照してください。
例の実装の name() メソッドは、テスト対象の UDF と同じ名前を返す必要があります。そうしないと、例が正しく登録されず、Pipeline Builder インターフェースに公開されません。
実際の例は examples() メソッドで定義する必要があります。以下はデフォルトの MultiplyExamples クラスに定義されている examples() メソッドの実装です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27@Override public List<UdfExample<SettableMultiplicand, Product, MultiplyConfiguration>> examples() { return List.of(UdfExample.<SettableMultiplicand, Product, MultiplyConfiguration>builder() // この例の一意のID .id(ExampleId.of("baseCase")) // オプション: この例が何を表しているかの説明 .description("値を2倍にする。") // この例がパイプラインビルダーでPROMINENTかDEFAULTのどちらの可視性を持つべきか .visibility(ExampleVisibility.DEFAULT) // この例が示すケース (基本ケース、nullケース、エッジケース) .category(ExampleCategory.BASE) // この例が示すUDFに渡す引数 .configuration(MultiplyConfiguration.builder().multiplier(2.0d).build()) // UDFへの例の入力行 .input( SettableMultiplicand.create(ctx().getRowBuilderFactory()) .key("key") .value(1.5d), SettableMultiplicand.create(ctx().getRowBuilderFactory()) .key("key") .value(3.0d)) // 例の出力行 (UDFが呼び出された後の入力行がどのようになるべきか) .output( Product.create(ctx().getRowBuilderFactory()).key("key").value(3.0d), Product.create(ctx().getRowBuilderFactory()).key("key").value(6.0d)) .build()); }
定義した例を基に、すべてのテストを実行できます。
- ローカル環境:
- testExamples のみを実行する:
./gradlew test --tests examples.ExamplesTest.testExamples - すべてのテストを実行する:
./gradlew test
- testExamples のみを実行する:
- Code Repositories:
- すべてのテストを実行する: Java Task Runner で
testを実行する。
- すべてのテストを実行する: Java Task Runner で
ExamplesTest.testExamples() を実行すると、examples.registry パッケージ内の Examples の実装を読み込み、有効性を確認します。上記の MultiplyExamples.examples() メソッドの場合、configuration に提供された引数 (multiplier = 2.0d) を使用して、2 つの input 行 (["key", 1.5d] と ["key", 3.0d]) 上で UDF を実行し、指定された出力行 (["key", 3.0d] と ["key", 6.0d]) になることを確認します。
変更を保存する
開発作業が完了したら、必ず変更をコミットしてください。
ローカル環境: 以下のコマンドを順に実行して、Foundry Code Repositories に変更をプッシュします。
git add .git commit -m "<commit message>"git push- Code Repositories に青いポップアップウィンドウが表示され、「このブランチに新しいコミットが作成されました」と表示されます。Update to most recent version を選択して、変更を表示します。
Code Repositories: Commit を選択します。
ユーザー定義関数をデプロイする
UDF は Pipeline Builder (推奨) または標準の UDF デプロイリポジトリを通じてデプロイできます。
Pipeline Builder へ公開する (推奨)
Pipeline Builder への公開は現在、Rubix エンロールメントの row map および flat map UDF のみ利用可能です。他の UDF タイプのサポートは今後追加されます。
以下の手順に従って、UDF を Pipeline Builder に公開してください。
- 下部パネルから Task Runner を開きます。次に、Java タブを選択し、
generateEddieLockfileを入力して、リポジトリ内の各 UDF を登録するための一意識別子を含むファイルを生成します。
generateEddieLockfile コマンドは、UDF 名に基づいてランダムな一意識別子を返します。公開後に UDF の名前を変更すると、コードは前の UDF を上書きするのではなく、新しい UDF として公開されます。同様に、lockfile を削除して再生成すると、UDF は新しい一意識別子を受け取り、新しい UDF として登録されます。Pipeline Builder で UDF をインポートする際に表示されるポップアップウィンドウには、すべての UDF のバージョン(古い名前、新しい名前、新しい lockfile)が表示されます。
- lockfile および変更をコミットします。
- バージョン (
0.0.1など) でリリースにタグを付けます。 - チェックが通過することを確認します。チェックに失敗した場合、UDF は Pipeline Builder に公開されません。
lockfile が存在しない場合、UDF は Pipeline Builder に登録されず、パイプラインにインポートできません。lockfile を生成するには、generateEddieLockfile を実行します。Code Repositories で作業している場合は lockfile は不要です。
- チェックが通過したら、現在のまたは新しい Pipeline Builder パイプラインに移動します。
- Reusables > User-defined functions > Import UDF に移動します。
- リストから UDF を選択し、
Addを選択します。ユーザーの UDF は Pipeline Builder のトランスフォームピッカーに表示され、他のトランスフォームと同様にパイプラインで使用できます。
UDF の最初のバージョン後に新しい変更や修正(定義 YML の編集を含む)をデプロイするには、上記の実装および公開手順を繰り返します。次に、Pipeline Builder パイプラインで以下を行います。
- Reusables > User-defined functions に移動します。
- UDF の Edit version を選択し、更新されたバージョンを選択します。
デプロイリポジトリに公開する
以下の手順に従って、UDF を Code Repositories に公開します。
- 変更を Commit し、リリースのバージョンを設定するために Tag version を選択します。
- タグチェックが通過した後、ストリーミング用の Foundry UDF Definitions > Foundry Streaming UDF Deployment テンプレートまたはバッチ用の Foundry UDF Definitions > Foundry Batch UDF Deployment テンプレートを使用して別のリポジトリを作成します。
- テンプレートの指示に従って UDF をデプロイします。
UDF の最初のバージョン後に新しい変更や修正(定義 YAML の編集を含む)をデプロイするには、上記の実装および公開手順を繰り返します。次に、デプロイリポジトリの build.gradle 依存関係で参照されるタグバージョンを更新します。
ユーザー定義関数定義 YAML
UDF 定義 YAML ファイルは次の形を取ります。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21name: # (string) このUDFの名前 customTypes: # (optional<CustomTypes>) 現在のUDF定義内で参照できるカスタム型。詳細は下記の[Custom Types](#custom-types)セクションを参照。 inputSchema: # (Schema) このUDFを実行するために入力行が準拠する必要があるスキーマ。詳細は下記の[Schema YAML definition](#schema-yaml-definition-documentation)セクションを参照。 outputSchema: # (Schema) このUDFの出力行のスキーマ。詳細は下記の[Schema YAML definition](#schema-yaml-definition-documentation)セクションを参照。 arguments: # (map<ArgumentId, Argument>) ビルド時に指定され、デプロイ時にUDF作成者に提供される引数。 # (ArgumentId: string) 引数のローカルに一意な名前 [ArgumentId]: required: # (Boolean) この引数が必須かどうか description: # (optional<string>) この引数の使用方法を理解するための説明をPipeline Builderに表示。 type: # (FieldType) 引数のデータ型 # Keyed Process UDFに特有の設定 keyColumns: # (list<string>) パーティション分割のためのキー列。入力スキーマに存在する必要がある。 eventTimeColumn: # (string) イベント時間を含む列。この列は入力スキーマに存在する必要がある。 # 他のすべてのUDFタイプに特有の設定 description: # (optional<string>) このUDFの説明をPipeline Builderに表示し、ユーザーがこのUDFの内容を理解しやすくする。 type: # (optional<Type>) このUDFのタイプ。UDFのロジックがどのように定義され、実行されるかを決定する。 # Type列挙型の許可される値: # - DEFAULT # - ASYNC_DEPLOYED_APP_UDF # - ASYNC_CUSTOM_UDF # - FLAT_MAP_UDF
UDF とその引数に対するオプションの description フィールドを含めることを強くお勧めします。特に UDF が Pipeline Builder にデプロイされる場合はなおさらです。これらの説明は、UDF の機能と引数の変更が出力にどのように影響するかについてのユーザーの理解を深めることができます。
スキーマ定義 YAML
UDF スキーマは以下の形をとります:
Copied!1 2 3 4 5 6 7 8name: # (文字列) コード生成が生成されたオブジェクトにプレフィックスとして使用するプロジェクト固有のスキーマ名 description: # (任意<文字列>) Pipeline BuilderでこのUDFを使用する際にコンテキストとして表示されるこのスキーマの説明 fields: # (リスト<Field>) このスキーマ内のすべてのフィールド - name: # (文字列) このフィールドのローカルで一意の名前 nullable: # (ブール値) 値がnullである可能性があるかどうか type: # (FieldType) このフィールドのデータ型、および関連するメタデータ。たとえば: type: double double: {}
上述のとおり、Pipeline Builderでユーザーが入力および出力の期待値を理解できるように、各スキーマの説明を含めることを強くお勧めします。
すべてのFoundryデータセットタイプはUDF FieldTypeをサポートしており、以下の形状を取ります。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60# 配列 type: array array: elementType: type: <FieldType> nullable: # (boolean) 配列の値がnullである可能性があるかどうか # バイナリ type: binary binary: {} # ブール値 type: boolean boolean: {} # バイト type: byte byte: {} # カスタム type: custom custom: # (string) `customTypes`ブロックで定義されたカスタムタイプの名前 # 日付 type: date date: {} # 小数 type: decimal decimal: precision: # (integer) 1から38までの整数(両端を含む) scale: # (integer) 0からprecisionまでの整数(両端を含む) # ダブル type: double double: {} # 浮動小数点数 type: float float: {} # 整数 type: integer integer: {} # ロング type: long long: {} # マップ type: map map: keyType: type: <FieldType> nullable: # (boolean) マップのキーがnullである可能性があるかどうか valueType: type: <FieldType> nullable: # (boolean) マップの値がnullである可能性があるかどうか # ショート type: short short: {} # 文字列 type: string string: {} # タイムスタンプ type: timestamp timestamp: {} # 構造体 type: struct struct: fields: [] # (list<Field>)
カスタムタイプ
UDF におけるカスタムタイプを使用すると、スキーマ定義全体で繰り返しリファレンスできるタイプを定義できます。
Copied!1 2 3 4 5 6 7 8 9customTypes: # このブロックは任意です。カスタムタイプを使用しない場合、このブロックを含める必要はありません。 types: # この `types` ブロックを忘れないでください! このブロックは、後で `customTypes` に追加フィールドのサポートを追加する場合に備えています。 customType: # このキーは、このカスタムタイプの一意の名前である必要があります # (FieldType) このカスタムフィールドのデータタイプと、それに関連するメタデータ。たとえば: type: double double: {} anotherCustomType: # カスタムタイプを定義します # ...
カスタム型は、プリミティブ、配列、マップ、構造体など、任意のフィールド型のエイリアスとして定義できます。ただし、一般的に、カスタム型は入力および出力スキーマ全体で繰り返される構造体型を定義する場合に最も有用です。
Copied!1 2 3 4 5 6 7 8 9 10 11customTypes: types: customStruct: type: struct struct: fields: - name: "doubleField" # フィールド名: "doubleField" nullable: false # nullを許容しない type: type: double # フィールドのデータ型: double double: {} # double型の詳細設定が必要な場合に記述
カスタムタイプは、以下のようにスキーマ内でリファレンスできます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16inputSchema: name: "Input" # 入力スキーマの名前 fields: - name: "inputStruct" # フィールドの名前 nullable: false # nullを許可しない type: type: custom # カスタムタイプを使用 custom: customStruct # 上で定義されたカスタムタイプの名前 outputSchema: name: "Output" # 出力スキーマの名前 fields: - name: "outputStruct" # フィールドの名前 nullable: false # nullを許可しない type: type: custom # カスタムタイプを使用 custom: customStruct # 上で定義されたカスタムタイプの名前
カスタム構造体が上記のようにUDFスキーマ内でリファレンスされる場合、コード生成は InputStruct と OutputStruct のために個別のクラスを作成しません。代わりに、入力オブジェクトと出力オブジェクトの両方がリファレンスされているカスタムタイプのコード生成クラス(以下の例では CustomStruct)をリファレンスします。
Copied!1 2 3 4 5 6 7public final Output map(FoundryRowMapUdf.Context ctx, Input input) { // 入力の構造体フィールドを出力の構造体フィールドに渡すだけの何もしないUDF Output output = Output.create(ctx.getRowBuilderFactory()); CustomStruct inputStruct = input.inputStruct(); // `CustomStruct` を返す output.outputStruct(inputStruct); // `CustomStruct` 引数を期待する return output; }
カスタム構造体はカスタム型を使用する大きな利点です。入力コード生成型と出力コード生成型が構造的に同じ場合、追加の作業なしで変換する必要がありません。
トラブルシューティング
このセクションでは、ユーザー定義関数の実装とデプロイに関する一般的な問題と、そのデバッグ手順について説明します。
コード生成が実行されない
通常、これは解析できない UDF 定義 YAML によって引き起こされます。
以下の手順に従って解決してください。
- 赤い
Code Assist task failedポップアップに表示される識別可能なエラーについて Code Assist を確認します。 - すべてのフィールドが提供されていること、そしてタイプミスがないことを確認します。最初の例定義と照らし合わせてクロスチェックします。
- エラーが続く場合、コードエディターの下部にある
Code Assist runningメッセージにカーソルを合わせ、Refresh を選択して Code Assist を更新します。 - リポジトリをローカルにダウンロードし、
./gradlew ideaまたは./gradlew eclipseコマンドを実行してコンソールに出力されるエラーを確認します。
UDF を登録解除できますか?
一度公開された UDF は Pipeline Builder から未公開にすることはできません。ロックファイルエントリを削除してリポジトリ上で generateEddieLockfile コマンドを再実行すると、新しい ID が UDF に付与され、Pipeline Builder のトランスフォームリストの UDFs セクションに 2 回表示されることになります。
ローカル環境: サポートされていないクラスファイルのメジャーバージョン
./gradlew idea open または ./gradlew eclipse open がエラー Could not open proj generic class cache for build file <build.gradle> ... Unsupported class file major version で失敗する場合、Java バージョンが Gradle と互換性がない可能性があります。
以下の手順に従って解決してください。
./gradlew --versionを実行して Java と Gradle のバージョンを確認します。- Gradle ドキュメント ↗ に記載されている Gradle バージョンと JVM バージョンが互換性があるかクロスチェックします。
- JVM バージョンが互換性がない場合で、すでに互換性のあるバージョンがローカルにない場合、互換性のある Java バージョンをダウンロード ↗ します。
export JAVA_HOME=<jdk install directory>/Contents/Home/として JAVA_HOME を設定します。
これで open コマンドを正常に実行できるはずです。
Task Runner で generateEddieLockfile タスクを実行できない
Failed to start Java server エラーが発生する場合、または Task Runner でコマンドを実行できない場合は、以下を確認してください。
- リポジトリテンプレートがバージョン 0.517.0 以上であること。
- これを確認するには、ファイルエディターに移動し、Display settings > Show hidden files and folders を選択します。templateConfig.json ファイルがファイルリストに表示されます。
- リポジトリが互換性のあるバージョンにない場合、リポジトリビューの右端から ... > Upgrade を選択して最新のテンプレートでプルリクエストを生成します。プルリクエストを承認し、リクエストがマージされてチェックが通過したらワークスペースを再構築します。
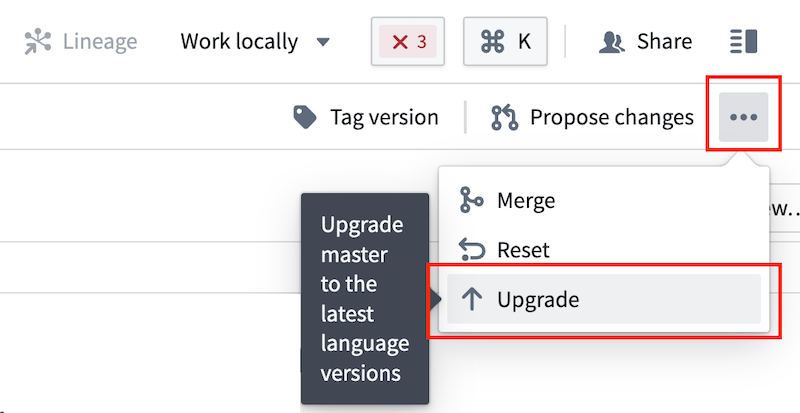
- ワークスペースが接続されていること。
- ワークスペースが接続されていない場合、ワークスペースを再構築します。
- Task Runner で Eclipse Java ではなく、Java タブを選択していること。