注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Foundry SAP 同期
Foundry への抽出を行う各 SAP オブジェクト(テーブル、ビューなど)ごとに新しい同期設定を作成する必要があります。
Data Connection ドキュメンテーションには、新しい同期を作成する方法の手順が詳しく記載されています。
Palantir Foundry Connector 2.0 for SAP Applications(「コネクター」)の同期を設定するには:
-
他の任意の同期と同様に、標準設定(名前、ターゲットデータセット、スケジュール)を設定します。
-
Transaction type をインクリメンタル更新の場合は APPEND、フルロードの場合は SNAPSHOT に設定します。インクリメンタル更新の詳細については、Incremental Updatesを参照してください。
-
次のオプションから SAP Object Type を選択します:
- ERP Table – 標準の SAP ERP テーブル用
- BW InfoProvider – BW InfoProvider 用(InfoCubes、DataStore objects、InfoObjects をカバー)
- BW BEx Query – BW BEx クエリ用
- SLT – SAP Landscape Transformation Replication Server からデータを抽出するため
- BW Content Extractor – ERP Business Content extractor 用
- Function – BAPI 関数を実行するため
- ERP Table Data Model – テーブル間の関係の詳細用
- Remote ERP Table – リモートシステムの標準 SAP テーブル用
- Remote BW InfoProvider – リモートシステムの BW InfoProvider 用
- Remote BW BEx Query – リモートシステムの BW BEx クエリ用
- Remote Function – リモートシステムで BAPI 関数を実行するため
SAP Object Typesで詳細情報をご覧いただけます。
-
SLT を使用している場合やリモートシステムに接続している場合は、Context を選択するように求められます。context の詳細については、Install a Remote Agentを参照してください。
-
次に、Object Name を入力します。このフィールドに入力を開始すると、SAP Object Type(および使用している場合は Context)に基づいて提案のリストが表示されます。
-
インクリメンタル更新を設定している場合は、Incremental Field を提供する必要があります。この設定についての詳細は以下のセクションを参照してください。
-
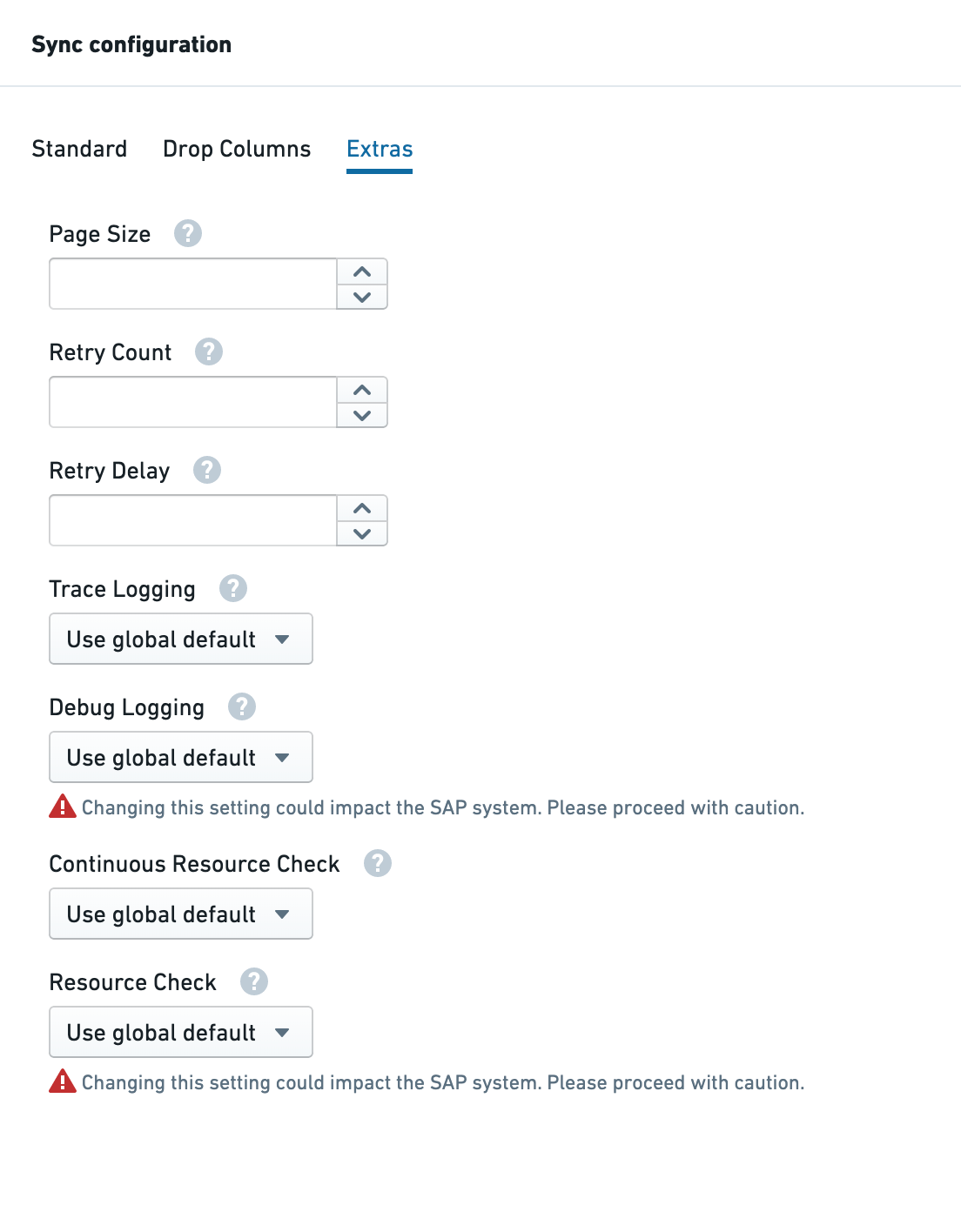
必要に応じて、追加のパラメーター(下記の詳細を参照)を指定することができます。これを行うには、Extras タブをクリックします。
SLT との同期設定の詳細については、Configure SAP SLTを参照してください。
インクリメンタルタイプ
インクリメンタル更新について詳しく学びましょう。
フィルター処理
フィルター設定は、SAP から抽出されるデータをフィルター処理するために使用されます。
フィルター構文では以下のオペレーターがサポートされています:
- Comma (
,) は "or" を意味します - Semicolon (
;) は "and" を意味します - Colon (
:) は "between" を意味します - Equals (
=) は "equals" を意味します - Exclamation mark and equals (
!=) は “not equals” を意味します - Greater than (
>)、greater than or equal to (>=)、less than (<)、または Less than or equal to (<=) がサポートされています。
すべてのフィールド名はデータ辞書のものと同じである必要があります。
例:
-
by price between 500 and 650
PRICE=500:650 -
by CUSTOMER A,B or C
CUSTOMER=A,B,C -
by price between 500 and 650 and CUSTOMER A,B or C
PRICE=500:650;CUSTOMER=A,B,C -
by a material starting with
PAL,DISandSAP, use the following filter with wildcardsMATERIAL=PAL*,DIS*,SAP* -
by a date column which is greater than or equal to 09.08.2019
DATE>=20190809
SAP の DB の日付形式は YYYYMMDD です。
列をドロップする
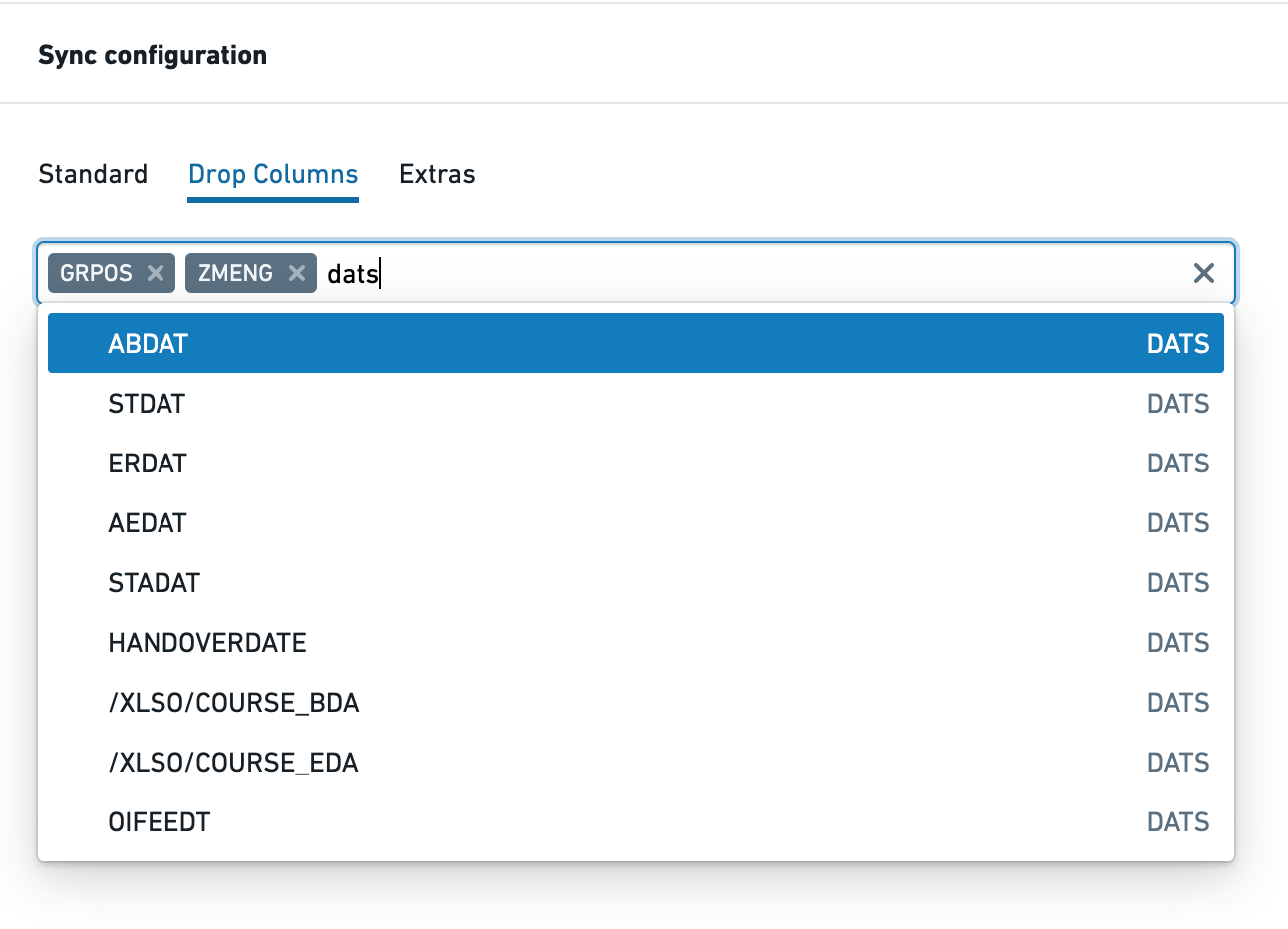
Drop Columns は、Table および Remote Table オブジェクトタイプでのみサポートされており、SAP からデータを抽出する前に列をドロップすることができます。指定したテーブルのスキーマ内のすべてのフィールドが複数選択ボックスにリストされます。フィールド名またはタイプ(この例では "dats")で検索することができます。
SAP 内のフィールドに機密データが含まれている場合や、Foundry で不要なデータをインポートしないようにする場合にこの機能を使用できます。列マスキング/ハッシング/暗号化機能を使用するよりもパフォーマンスが大幅に向上します。
タイムスタンプ
タイムスタンプが On に設定されていると、データにはデータの取得時刻と行順序番号が含まれます。この情報は、必要に応じてパイプラインの後段で SAP のデータを重複排除するために使用できます。
- 任意の主キーについて、
/PALANTIR/TIMESTAMPの最大値の/PALANTIR/ROWNOの最大値は、そのレコードの SAP における最新バージョンであることが保証されています /PALANTIR/TIMESTAMP列は、データ同期が実行された時間を示します(SAP システムで更新が発生した時間ではありません)/PALANTIR/ROWNO列は、特定のデータ同期内で SAP から返されるレコードの順序を追跡します- この値は、トリガーベースの変更データキャプチャ(CDC)のための SLT Replication Server を使用しているか、CDPOS または CDHDR インクリメンタルモードを使用している場合のみ関連します
- これらのケースでは、単一のデータ同期には、最後のデータ同期以降にレコードに対して発生したすべての変更が含まれます。
/PALANTIR/ROWNOの値が大きいほど、変更は新しいものです
Param name
関数は複数のテーブルを返すことができます。このパラメーターは、どのテーブルを選択し、Foundry データセットに書き込むかを決定するために使用されます。
Depth
SAP Type が Data Model の場合、この設定はテーブル関係を見つけるときに何リンクをフォローするかを定義するために使用されます。1次関係のみに対しては 1 を設定し、2次関係に対しては 2 を設定します。
Page size
SAP システムからデータを取得するときにページごとに返す行数を設定します。この設定のシステムデフォルトは 50,000 行で、ここでの変更はその値よりも大きい場合にのみ適用されます。より低いシステムデフォルトを設定したい場合は、システムコールを行う必要があります。
Retry count
リソース不足によりリクエストが失敗した場合に試行するリトライの回数。
Retry delay
二回のリトライ試行の間の遅延(秒)。
Trace logging
この同期のトレースログをオンにするには On に設定します。
Debug logging
デバッグログをオンにすると、SAP システムでバックグラウンドプロセスが起動し、同期の期間中実行されます。これは複雑な問題のライブデバッグに使用されます。このプロセスはリソースを消耗し、システムのユーザーや他のプロセスに影響を与える可能性があるため、注意して進んでください。
この同期のデバッグログをオンにするには On に設定します。
連続的なリソースチェック
On に設定すると、すべてのページングリクエストがリソースチェック(メモリ、CPU など)の対象となります。Off に設定すると、初期ページリクエストのみがリソースチェックの対象となります。詳細は performance parameters を参照してください。
リソースチェック
リソースチェック設定をオフにすると、同期は利用可能なメモリ、CPU、プロセスが設定したしきい値を満たしているかどうかに関係なく実行されます。これは、同期が SAP システムに過剰な負荷をかけ、ユーザーや他のプロセスに影響を与える可能性があることを意味します。注意して進んでください。
この同期のすべてのリソースチェック(メモリ、CPU、プロセス)をオフにするには Off に設定します。詳細は performance parameters を参照してください。
Fetch Option (SLT のみ)
Fetch Option が XML に設定されている場合、コネクターは SLT からデータをZIP 形式で取得します。Direct の場合、文字列として SLT からデータを取得します。XML データ取得オプションは Direct 方法よりも高速です。データ取得時にデータコンテンツに関連するエラーが発生した場合にのみ、XML オプションを使用しないでください。
maxRowsPerSync (SLT のみ)
設定すると、コネクターは Foundry からの各同期実行ごとに、おおよそ maxRowsPerSync(少し上または下)の行を返します。これにより、非常に大きなテーブルの初期同期(またはそれらも多くの行を含む後続のデルタ)を、一連の小さな同期に分割することができます。中断的な問題が長い同期を中断している場合は便利です。なぜなら、全体のテーブルを再取り込むことなく、最後に成功した同期から回復できるからです。
この設定を有効にするには、Sync configuration の Basic view から Advanced に切り替える必要があります。
Copied!1maxRowsPerSync: 500000 # 同期あたりの最大行数
BEx 設定(BEx のみ)
Connector のバージョン SP22 および Magritte Plugin 0.11.0 以降、以下の BEx クエリパラメーターを使用して BEx ページングサポート を有効にできます。
bexPaging:BEx クエリのページングを有効にします(フィルターを介したサポート)。SAP アドオンは自動的に各ページに対して別々のフィルターを生成します。これにより、大規模な BEx クエリを手動で同期を分割することなく実行できます。この値が設定されていない場合のデフォルト値(SAP アドオンで定義)は false です。
bexMemberLimit:Connector は、不要な次元がフィルター候補として使用されるのを防ぐためのしきい値を使用します。InfoObject の投稿された値が bexMemberLimit よりも大きい場合、フィルター生成のために細かすぎるとみなされ、破棄されます。この値が設定されていない場合のデフォルト値(SAP アドオンで定義)は 200 です。値は 2 より低くすることはできません。
この設定を有効にするには、同期設定の基本ビューから詳細ビューに切り替える必要があります。
Copied!1 2 3bexSettings: bexPaging: true # bexPagingがtrueの場合、ページングが有効になります bexMemberLimit: 10 # bexMemberLimitは、メンバーの最大数を10に設定します
予期しない値を無視する
同期を実行する際に、次の形式のエラーに遭遇することがあります。
SAPデータで予期しない値が検出されました フィールドYYYの値XXXの解析に失敗しました
これは、日付や数値が不正確で解析できない場合に発生します。理想的には、ソースシステムの問題を解決することでこれを解決すべきです。しかし、この解決策が適用できない場合や、それでも同期を実行したい場合は、予期しない値を無視することができます。
この設定を有効にするには、Sync設定のBasicビューからAdvancedに切り替える必要があります。(一度この設定を追加すると、Basicビューに戻ることはできません。)Advancedビューで、以下の行を同期YAML定義に追加します:
Copied!1 2# 予期しない値を無視する ignoreUnexpectedValues: true
これにより、日付と数値の解析例外が無視されます。解析に失敗した値は null に設定され、同期の終了時に解析例外の概要を含む警告が記録されます。
各 Parquet ファイルの最大サイズを設定する
Foundry データセット内の各 Parquet ファイルの最大ファイルサイズは、すべての同期のためのソース、および特定の同期のための同期で定義できます。
特定の同期の各 Parquet ファイルの最大サイズを変更したい場合は、outputSettingsOverride パラメーターを使用してください。
Copied!1 2 3 4 5outputSettingsOverride: maxFileSize: type: rows # ファイルサイズの制限のタイプを指定します。ここでは行数(rows)による制限を指定しています。 rows: max: 10000 # 最大行数を指定します。ここでは最大行数を10000行に設定しています。
Copied!1 2 3 4 5 6outputSettingsOverride: maxFileSize: type: bytes bytes: # 日本語: 約最大ファイルサイズを400MBに設定 approximateMax: 400MB
- バイト単位での最大サイズは概算です。結果として得られるファイルサイズは、わずかに小さくなったり大きくなったりする場合があります。
- バイト単位で最大サイズを指定する場合、バイト数は、Parquet writer のメモリ内バッファサイズ(デフォルトは 128 MB)の少なくとも 2 倍である必要があります。