注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
シンプルな Preparation を作成する
Preparation は Pipeline Builder に取って代わられ、データのクリーニングや準備においてもはや推奨されていません。Pipeline Builder は、パイプライン用のデータをクリーニングおよび準備しやすくし、Marketplace サポートも提供しています。
このチュートリアルでは、Preparation を使って、生のデータが含まれるスプレッドシートを、解析に使用できるクリーニング済みおよび準備済みのデータセットに変換する方法を説明します。
このチュートリアルでは、Meteoritical Society のデータを使用しています。このデータは、NASA Data Portal ↗から入手できます。以下のサンプルデータセットを使用して、ユーザーの Preparation インスタンスで進めることができます。
meteorite_landings_raw をダウンロード
このデータセットには、地球上で見つかった隕石に関する生データが含まれています。
データセットには、各隕石の名前、質量、分類、その他の識別情報が含まれており、発見された年や見つかった場所の座標も記載されています。
Foundry に アップロードする前に、CSV を開いてデータを確認することをお勧めします。
1. Preparation を作成する
まず、新しい Preparation を作成します。
-
まず、
meteorite_landings_raw.csvファイルを Foundry にアップロードします。 -
次に、
meteorite_landings_rawデータセットに移動し、右クリックして Preparation でクリーンアップ を選択します。
これにより、新しい Preparation が作成されます。ファイル内で再度見つけやすくするために、意味のある名前で Preparation を保存することができます。
- 最後に、保存 をクリックし、Preparation の名前と保存場所を選択します。
作成した Preparation は、明示的に保存しない限り、デフォルトで ファイル > .auto-save に保存されます。
2. データをクリーニングする
次に、データセットを確認し、見つかったデータ品質の問題を修正します。
空白をトリムする
- まず、テーブルの name 行をクリックします。
下のパネルには、行内のデータに関する情報が表示されます。統計、グラフなどです。
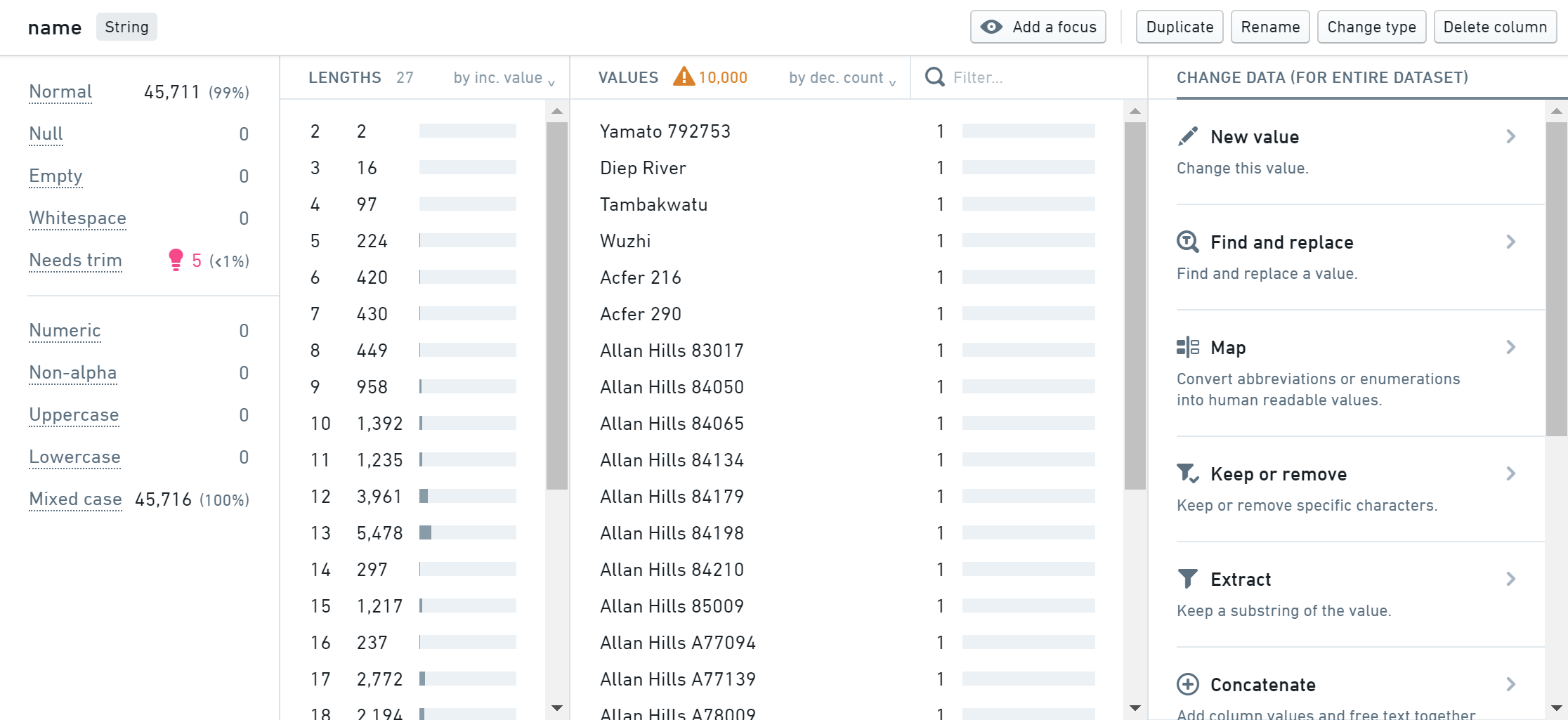
統計パネルから、一部の値が トリムが必要 としてフラグされていることがわかります。これは、値の先頭や末尾に余分な空白があることを意味します。
- ピンク色の電球マークにカーソルを合わせ、空白をトリムするボタンをクリックして、この問題を修正します。

行の統計が更新されると、トリムが必要 のカウントがゼロになり、行が正常にクリーニングされたことがわかります。また、画面の右側にある データセットの変更 リストに 空白をトリムする の変更が追加されます。
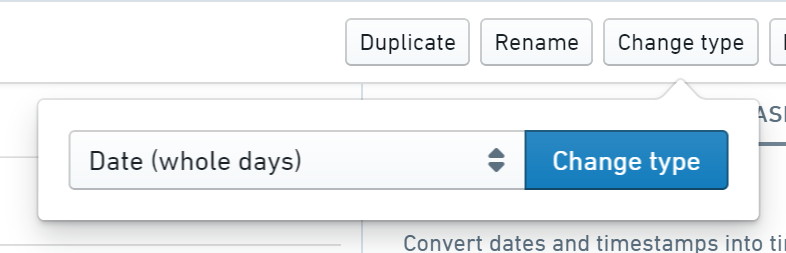
year 行を日付に変換する
次に、year 行に進みましょう。テーブルでは、この行のデータタイプが タイムスタンプ であることがわかります。しかし、私たちはそれを 日付 にしたいだけです。
-
まず、タイプを変更 ボタンをクリックし、ドロップダウンリストから 日付(全日) を選択します。
-
タイプを変更 ボタンをクリックします。
ジオロケーションの値を null に設定する
最後に、ジオロケーション 行を見てみましょう。ヒストグラムでは、多くの行が (0.000000,0.000000) の値を持っており、これは有効なジオロケーションではありません。
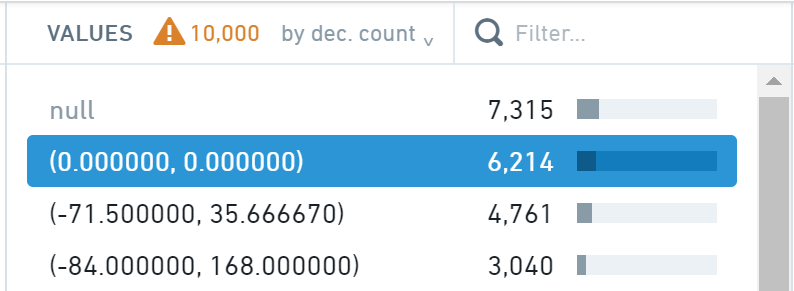
これらの値を null に設定することで修正しましょう。
- まず、ヒストグラムで (0.000000, 0.000000) の値を選択します。
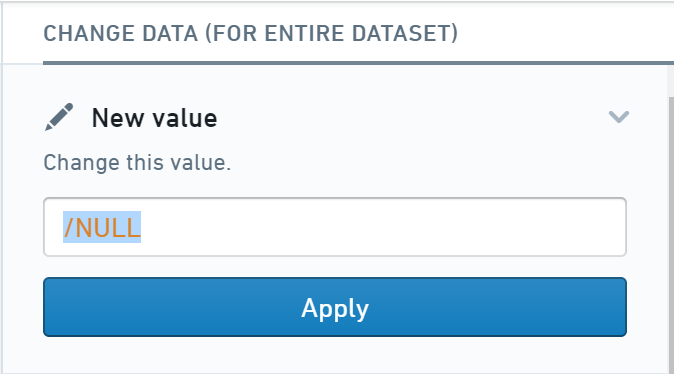
- 次に、選択した行のデータを変更 の下にある 新しい値 アクションをクリックします。
- 最後に、テキストボックスに
/NULLを入力し、適用 をクリックして、これらの値をnullに設定します。
3. クリーニングされたデータセットのバージョンを保存する
データ品質の問題が解決されたので、新しいクリーニング済みのデータセットを保存できます。
- まず、画面上部の データセットとして保存 ボタンをクリックします。
- 次に、新しいクリーニング済みデータセットの名前と場所を選択します。新しいデータセットが作成されていることを示すポップアップが表示されます。

出力: によって新しいデータセットへのリンクが示されます。Preparation に変更を加えると、更新 ボタンを使って出力データセットを更新できます。
新しいデータセットを保存せずに Contour でクリーニングの結果を試すには、画面上部の 解析 ボタンをクリックしてください。