注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
基本的な例
このページでは、Preparations インターフェースでデータをクリーニングして準備するための基本的な変換の例を探ります。
先頭と末尾の空白を削除する
いくつかの値が先頭/末尾に空白を持っている場合、それらは統計エリアの Needs trim の下にカウントされます。
Needs trim の隣にあるピンクの電球をクリックし、次に Trim whitespace をクリックして、その行の値から先頭と末尾の空白を削除します。

空の文字列を null に設定する
いくつかの値が空の文字列である場合、それらは統計エリアの Empty の下にカウントされます。
Empty の隣にあるピンクの電球をクリックし、次に Set to null をクリックして、その行の任意の空の文字列の値を null に設定します。
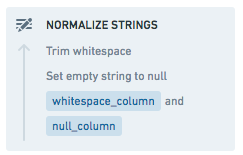
複数の文字列行を一度に正規化する
-
正規化したい文字列の行を選択します(または選択された行がない場合はすべての文字列の行をデフォルトにします)。
-
Normalize strings アクションを選択し、適用したいアクションを選択します。
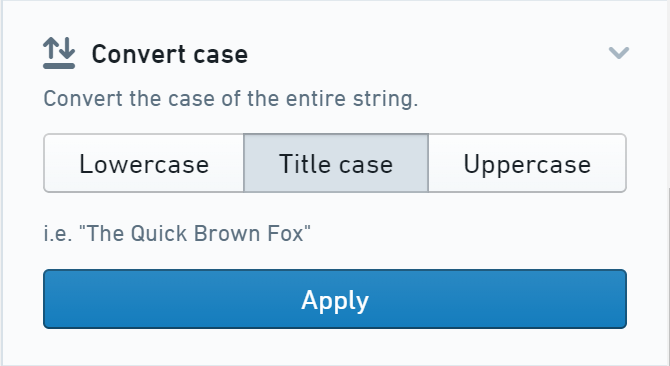
値を大文字に正規化する
左側の統計パネルは、行の値が大文字、小文字、または混合のいずれであるかを表示します。
値を大文字に正規化するには、Change Case アクションを選択し、Uppercase をクリックします(または、適切に Lowercase または Title case を使用することもできます)。
通貨文字列を数値行に解析する
数値が余計な非数値文字(例えば、$1,234.56)を持つ場合、行のタイプは通常、string として検出されます。しかし、数値的に分析するためには、行は数値であるべきです。
統計エリアをチェックして、値が Numeric として表示されていることを確認します。
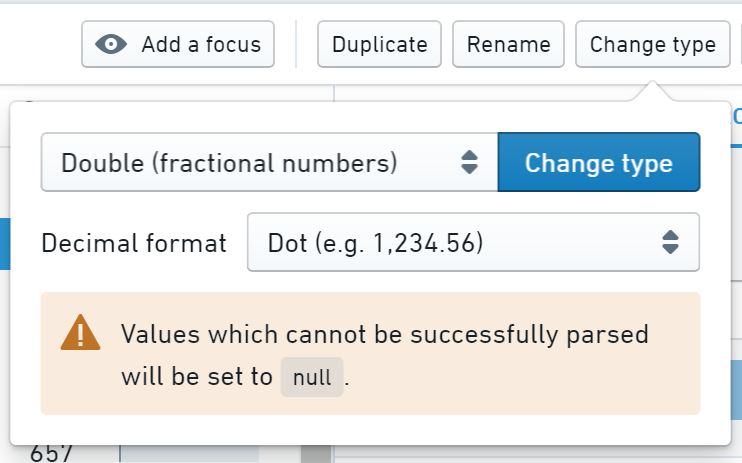
一部の値が非アルファベット、大文字等として表示されている場合、それらを数値として解析できるようにまずクリーニングする必要があります。該当するカテゴリー(例えば、non-alpha)をクリックして、それらの値を探し、クリーニングを開始します。
Change type ボタンをクリックし、ドロップダウンから整数(全体の数値の場合)または Double(小数点がある数値の場合)を選択します。
データが存在しないことを示す値を null にする、例えば N/A
よくあるのは、行がデータが利用できないことを示す値を持つことです(例えば、N/A、Other、None、Unknownなど)。通常、これらの値は、そのセルにデータが利用できないことを適切に示すために null であるべきです。
-
ヒストグラム内の値または値を選択します。
- 値が見えない場合は、Filter... ボックスを使用してそれらを検索してみてください。
-
New value アクションをクリックし、
/NULLを入力し、Apply をクリックします。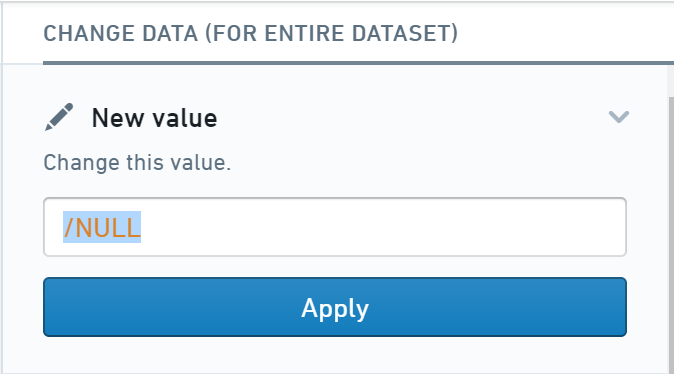
変更を適用する前に1つ以上の値を選択するようにしてください。そうしないと、全体の行が null に設定されます。
ZIPコードを5桁に正規化する
ZIPコードの行は、5桁の (12345) と9桁の (12345-6789) 値の混合であることがあります。通常、ZIPコードはグルーピングや他の準備ワークフローを可能にするために、単一の形式に正規化されるべきです。
Extract アクションを使用して、ZIPコードの行を5桁に正規化します。Extract アクションをクリックし、Type ドロップダウンから Indexed Substring を選択し、開始インデックスに 1 を、終了インデックスに 5 を使用します。
全ての行名をスネークケースに変更する
スネークケース (lowercase_with_underscores) は、多くのデプロイメントで一般的な行命名の標準です。
Normalize column names アクションをクリックします。アクションが表示されない場合は、行が選択されていないことを確認します。Standard を選択し、Apply をクリックします。
すべての行は即座にスネークケースに名前が変更され、行の値は特殊文字の代わりにアンダースコアを含む小文字の形式になります。
多数の行名を変更する
Columns ビューは多数の行名を変更する最も簡単な方法です。画面上部の Columns をクリックして Columns ビューに切り替えます。
一括行の変更は、Apply をクリックするまで保存されません。
名前を変更する必要がある任意の行に対して、行名をクリックして必要に応じて編集します。行名が緑色に変わります。これは、変更がステージングされているがまだ適用されていないことを示します。
すべての行名が修正されたら、右側の changelog の上部にある Apply ボタンをクリックして、すべての行名の変更を保存します。
null の行を削除する
時々、行は null の値のみを含むことがあります。行全体を削除することで、データセットをクリーニングできます。
統計パネルをチェックして、行が完全に null の値を含んでいることを確認します。統計は Null に対して 100% と表示するべきです。
次に、Delete column ボタンをクリックして行を削除します。
null 値を持つ行を削除する
時々、特定の行で null 値を持つ行は無関係で、削除できます。
行を選択し、統計パネルの Null セクションをチェックして、その行の null 値を持つ行がいくつあるかを確認します。
次に、統計パネルで Null をクリックし、Focus in ボタンをクリックして、null 値を持つ行のみにフォーカスします。これらの行が無関係で削除できることを確認します。
これらの行を削除するには、画面上部の Remove rows ボタンをクリックします。
元のデータの行順を記録する
初期ビューから、以下の式で Add new column アクションを使用します:
Copied!1monotonically_increasing_id()
この関数は、各行に一意でモノトニックに増加するIDを生成します。スパークデータフレームに対して使用すると、各行に一意のIDが割り当てられます。 これにより、行の順序に基づいて増加することが保証されている数字の行が追加されますが、連続性と決定性は必ずしもありません。
行の値は各計算ごとに変更することができます。これにより、準備から保存されたデータセットが複数回構築されたときに行に関連付けられた数字が異なったり、行番号の行のヒストグラムがテーブルデータと一致しないなど、予期しない挙動が生じる可能性があります。
行番号の追加 (小規模データセットのみ)
初期ビューから、以下の表現で 新しい行を追加 アクションを使用してください:
Copied!1 2-- monotonically_increasing_id()によって順序付けられた上で、行番号を取得します。 row_number() over (order by monotonically_increasing_id())
この行番号の式は計算に非常にコストがかかり、大規模なデータセットを使用して準備を行う際のパフォーマンスを大幅に低下させる可能性があります。
変更ログの途中に変更を挿入する
初期表示から、変更を挿入したい変更を選択します。その後、変更をクリックするか、変更のドロップダウンメニューで Preview data を選択してプレビューモードに入ります。
準備に変更を加えます。変更はプレビューされている変更の上、未来の変更の下に表示されます。
プレビュー警告バーで Cancel をクリックすると、プレビューモードを終了します。