注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Pipeline Builder で一意の ID を作成する
Pipeline Builder では、一意の ID によってデータの追跡、処理、および分析が容易になり、各レコードが個別に識別され適切に処理されることを保証します。このため、レコードに一意の識別子 (ID) を作成する必要があることがよくあります。このセクションでは、単調増加する ID を使用することが最適ではない理由と、一意の ID を生成するための推奨方法が文字列列の連結とその後の SHA256 ハッシュである理由を説明します。
文字列列の連結と SHA256 ハッシュの使用
一意の ID を生成する最良の方法は、入力データから文字列列を連結し、連結された文字列の SHA256 ハッシュを作成することです。
Pipeline Builder のトランスフォームパス内でこの方法を使用して一意の ID を生成するには、次の手順に従います。
- データセット内の各レコードを一意に識別できるようにする文字列列を特定します。
- 選択した文字列列を連結して、各レコードの単一の文字列を形成します。
- 「Hash sha256」を使用して、連結された文字列の SHA256 ハッシュを計算します。結果として得られる 256 ビットのハッシュは 64 文字の 16 進数文字列として表され、各レコードの一意の ID として機能します。

この方法にはいくつかの利点があります。
- 一貫性: 同じ入力データは常に同じ一意の ID を生成し、データパイプラインの異なる実行間で一貫性を確保します。これにより、レコードの追跡、重複の識別、およびデータの照合が容易になります。特に、ID がオブジェクトの主キーとして使用される場合、パイプラインの再構築の結果としてこれらの主キーが変更されないことが重要です。また、データの下流で作業する誰かが ID の安定性に依存する可能性があるかどうかも考慮してください。
- 分散生成: 一意の ID はデータ自体から導出されるため、複数のプロセスが同期や集中管理なしに一意の ID を同時に生成できます。これにより、分散データ処理環境でのスケーラビリティとパフォーマンスが向上します。
文字列列の連結とその後の SHA256 ハッシュを使用することで、スケーラブルで安全かつ一貫性のある一意の ID を生成でき、データパイプラインアプリケーションに最適な選択肢となります。
単調増加する ID の欠点
単調増加する ID は Pipeline Builder ではサポートされていませんが、Spark に精通しているデータエンジニアがよく使用します。単調増加する ID は、1、2、3 などのように順次生成されます。このアプローチには固有のシンプルさがありますが、いくつかの欠点があります。
- ビルド間の不一致: Spark で単調増加する ID を使用する場合、同じアプリケーションの異なる実行間で生成される ID が変わる可能性があります。これは、Spark がタスクをエグゼキュータに割り当てる方法が異なるためであり、異なる ID 割り当て順序が生じる可能性があります。その結果、この不一致により結果の再現、異なる実行の比較、または増分更新が困難になり、オントロジーオブジェクトの ID 列として使用する場合は、毎回フルインデックスの再構築を強制されることになります。
- 状態依存: 単調増加する ID を生成するには、行間で状態を維持する必要があります。
これらの欠点は、データパイプラインアプリケーションで一意の識別子を生成するための最適なアプローチではないことを示しています。代わりに、前のセクションで詳述したように、文字列列の連結とその後の SHA256 ハッシュを使用することをお勧めします。
ハッシュする一意の列セットが利用できない場合
ビルドやプレビュー間で一貫性がないことに注意してください。この方法は、一意の列セットを特定できない場合の最後の手段としてのみ使用するべきです。
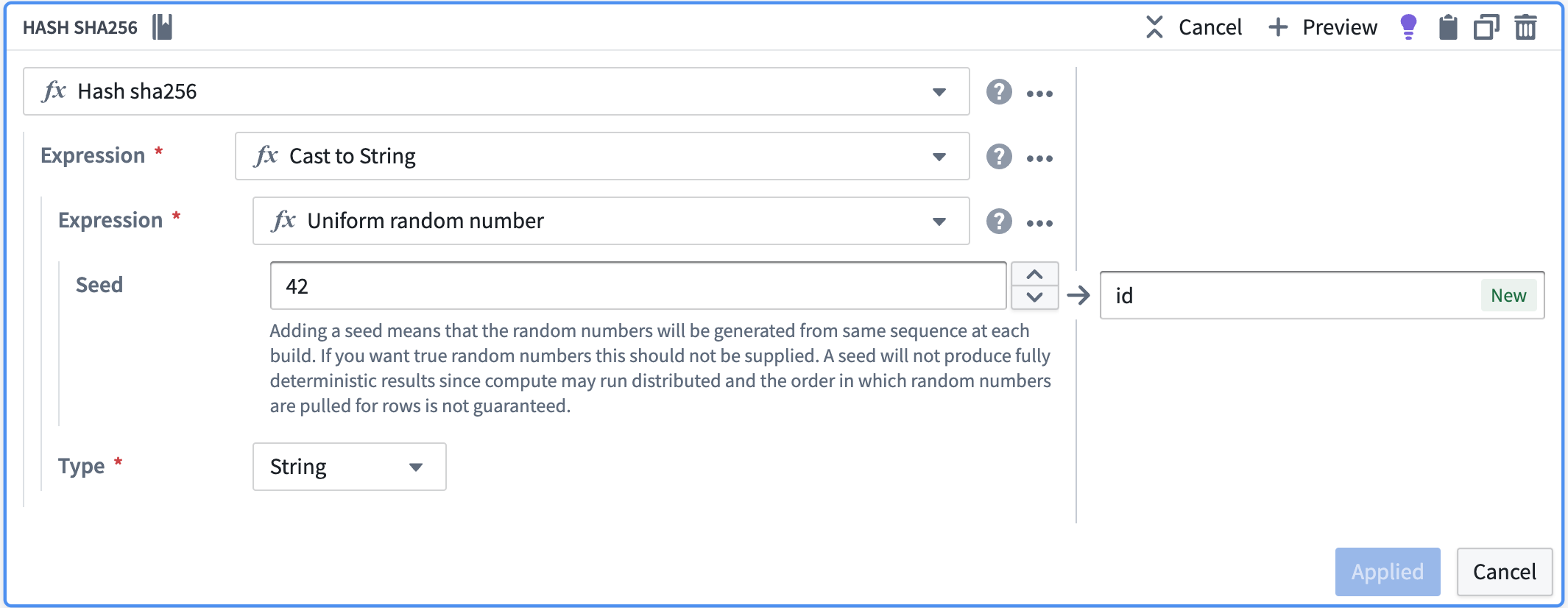
データ内の一意の行を定義する列セットがない場合、ランダム数のハッシュを使用して ID を作成できます。この方法で ID を作成するには、Pipeline Builder のトランスフォームパス内で以下の手順に従います。
- 「Uniform random number」を使用してランダム数を作成します。
- 列を文字列にキャストします。
- 「Hash sha256」を使用して、その列をハッシュします。