注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
頻出パターンのマイニング
Pipeline Builder は、トランスフォームに Frequent Pattern Growth(FP-Growth)アルゴリズムを使用することで、頻出パターンのマイニングプロセスを簡略化します。このアルゴリズムにより、マイニングのワークフローを簡単に構築・管理し、大規模なデータセット内の価値ある頻出パターンを発見することが可能になります。
頻出パターンのマイニングは、大規模なデータセット内の反復的なパターンや関連性を特定するためのデータマイニング手法です。頻出パターンマイニングの主な目的は、偶然よりも頻繁に共起するアイテムやイベント間の関係を発見することです。これらのパターンは、頻出アイテムセットとも呼ばれ、データ内の隠れた関連性や依存性を明らかにし、より良い意思決定と予測を可能にします。
頻出パターンマイニングは、マーケットバスケット分析、推奨システム、バイオインフォマティクス、ネットワークトラフィック分析、顧客属性分析、説明可能な AI(XAI)など、さまざまな領域で数多くの方法で適用されています。頻出パターンを特定することで、組織は価値ある洞察を得ることができ、戦略を強化し、全体的な効率を向上させることができます。
頻出パターンマイニングの例:マーケットバスケット分析
頻出パターンのマイニングが小売業界でよく使用される一般的なアプリケーションは、「マーケットバスケット分析」と呼ばれます。Pipeline Builder の Frequent Pattern Growth トランスフォームを使用して、同じ取引で頻繁に発生する製品の組み合わせを特定することができます。
例えば、スーパーマーケットは、顧客による過去の購入(取引)のデータセットを持っているかもしれません。各取引には、一緒に購入された一連の製品が含まれています。以下は、そのような取引の簡略化された例のデータセットです:
| transaction_id | products_purchased |
|---|---|
| 1 | [Bread, Butter, Milk] |
| 2 | [Bread, Butter] |
| 3 | [Bread, Diapers, Beer] |
| 4 | [Milk, Diapers, Beer, Butter] |
| 5 | [Bread, Butter, Diapers] |
頻出パターン成長トランスフォームは、Items 列と最小支持度の値を入力として受け取ります。この例では、products_purchased 列がアイテム列です。出力には頻出パターンのみが含まれるため、最小支持度は 0.6 に設定されています。つまり、トランスフォームは取引の少なくとも 60% で発生するパターンのみを返します。以下のスクリーンショットは、この例のためのトランスフォームの設定方法を示しています:
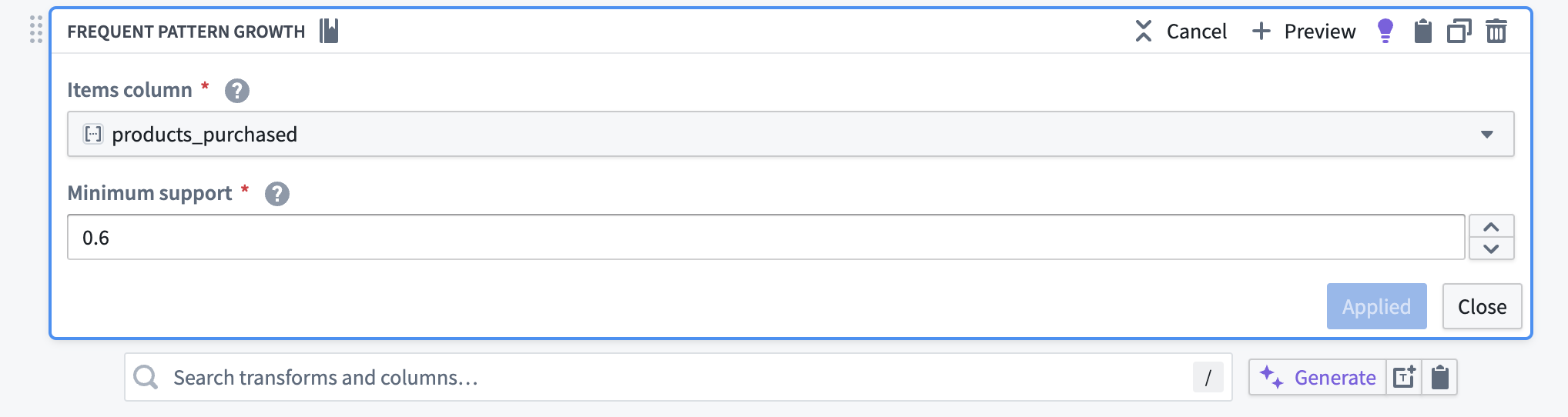
トランスフォームの出力データセットは次のとおりです:
| pattern | pattern_occurence | total_count |
|---|---|---|
| [Bread] | 4 | 5 |
| [Butter] | 4 | 5 |
| [Bread, Butter] | 3 | 5 |
| [Diapers] | 3 | 5 |
この場合、頻出パターンのマイニングは、BreadとButterが取引内で頻繁に一緒に現れる(5つの取引のうち3回発生する頻出アイテムセットである)ことを明らかにします。この情報は、製品の配置(パンとバターを一緒に置くことで売上を増加させる)やプロモーション(パンを購入したときにバターの割引、またはその逆)など、さまざまなビジネス戦略を推進するために使用することができます。
上記は、実際の使用例で見つかるはるかに大規模で複雑なデータセットの簡略化された例です。FP-Growth のような効率的なアルゴリズムの使用は、効果的な頻出パターンマイニングのために重要です。