注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
データの結合
単一のデータセットを変換することに加えて、Pipeline Builder では、結合やユニオンを使ってデータセットをまとめることができます。
結合は、少なくとも1つの一致する行がある2つのデータセットを組み合わせます。設定する結合のタイプによって、一致する行を組み合わせて、一致しない行を除外する結合出力が作成されます。
データセットの選択
2つのデータセットを結合するには、グラフ内の最初のデータセットノードを選択し、結合をクリックします。
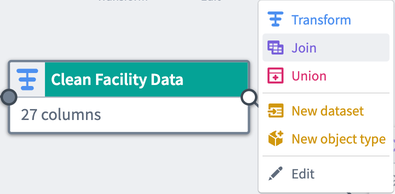
最初に選択されたデータセットは、左側のデータセットです。右側のデータセットになる別のデータセットノードを選択します。結合の設定を開始するには、開始をクリックします。
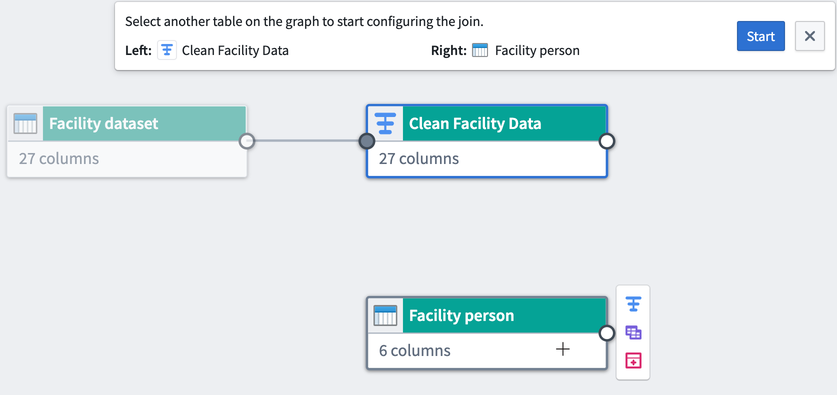
結合の設定
結合フォームでは、結合タイプを編集し、一致条件を選択し、出力テーブルのプレビューを表示できます。
- 結合タイプ: 左結合、右結合、内結合、または外結合を作成するか選択します。
- 左: 左テーブルのすべての行と、右テーブルの一致する行を保持します。
- 右: 右テーブルのすべての行と、左テーブルの一致する行を保持します。
- 内: 両方のテーブル間の一致する行のみを保持します。
- 外: 両方のテーブルのすべての行を保持し、一致しない行の列に
nullを埋め込みます。
- 一致条件: 左データセットから列を選択し、右データセットの列と等しいとマークします。たとえば、左の
Clean Facility Dataデータセットのcity行は、右のFacility PersonデータセットのCITY行と等しいです。 - プレビュー: 右と左の入力データセットからプレビューデータを表示します。結合を適用した後、出力テーブルからプレビューデータを表示します。結合を適用中にエラーが発生した場合は、エラータブで表示します。
上記および以下の例のすべてのデータはランダムに生成され、代表的ではありません。
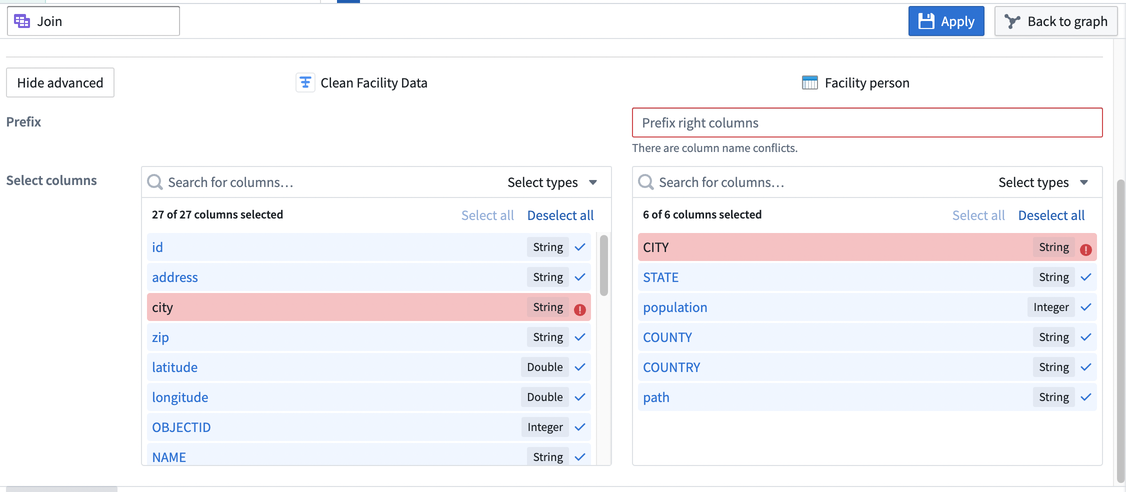
結合に特定の列を含めることを選択し、右テーブルにプレフィックスを追加することができます。プレフィックスと列フィールドを展開するには、詳細を表示を選択し、右テーブルのプレフィックスを入力し、結合に含める列を選択します。以下の例では、左データセットのすべての列を保持し、右データセットから STATE と population の列のみを含めています。
結合の適用
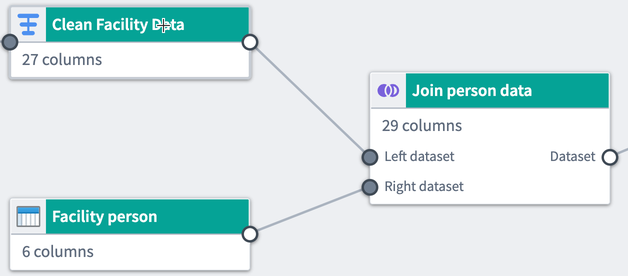
結合の設定が完了したら、適用をクリックして、ワークフローに結合を追加します。グラフ内で、2つの結合されたデータセットに接続された結合ノードが表示されます。新しい結合の名前を Join person data とし、元の Clean Facility Data および Facility person データセットの直接出力としました。
結合ノードをクリックして選択し、編集を選択して結合の名前を変更したり、編集したりできます。
ノード上の白または灰色の円をドラッグして、グラフ上の接続を変更したり、リンクを削除したりします。