注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
概要
Pipeline Builder は Foundry の主要なデータ統合アプリケーションです。Pipeline Builder を使用して、生データソースをクリーンな出力にトランスフォームし、さらに分析に備えるためのデータ統合パイプラインを構築できます。
Pipeline Builder と強力なバックエンドモデルを使用すると、コードを書くユーザーとコードを書かないユーザーがパイプラインワークフローで共同作業できます。Pipeline Builder は Spark と Flink の両方をそのアーキテクチャの一部として活用し、Palantir が開発したカスタムライブラリとサービスによってサポートされるさまざまな高度な機能を組み込んでいます。長時間のヘルスチェックが必要なコードを書く代わりに、Pipeline Builder はユーザーが特定のプログラミング言語の知識を必要とせずに、データトランスフォームを適用するための洗練されたビルダーのポイントアンドクリックインターフェースを通じて、さまざまなプログラミング言語を統合します。
Pipeline Builder は、ロジック作成と実行の間を仲介するように特別に設計された次世代のデータトランスフォームバックエンドを使用しています。ユーザーが構築したいパイプラインを記述すると、バックエンドがトランスフォームコードを書き、パイプラインの整合性をチェックし、リファクタリングエラーを特定して、健全なビルドを確保するための解決策を提供します。バックエンドがロジック作成と実行の間のミドルレイヤーとして機能するため、ビルダーはパイプラインを構築する前にスキーマの問題を解決し、計算やコードチェックに費やす時間を節約できます。
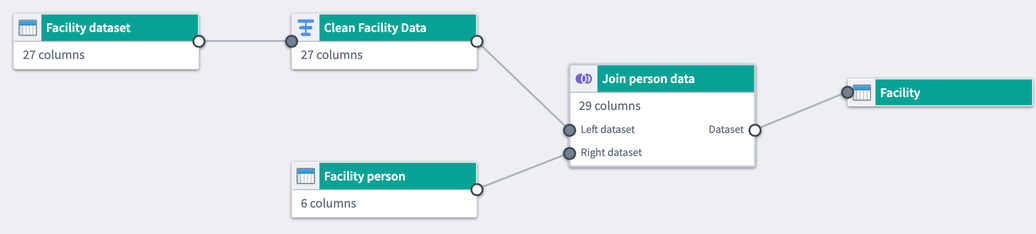
機能
Pipeline Builder には、包括的なパイプラインの作成、保守、および制御に焦点を当てた機能が含まれています。
- 直感的なユーザーインターフェース: ユーザーは、結合キーや列キャスティングの提案などのフィードバックを提供するグラフおよびフォームベースのインターフェースを使用してパイプラインを作成します。
- 型安全関数: 関数は強く型付けされており、ビルド時ではなく即座にエラーをフラグ付けできます。
- 厳格な出力チェック: 期待される出力チェックが満たされない場合、ビルドが防止され、意図しない下流の破損を回避します。
- 自動ビルドパスの剪定: Pipeline Builder は、出力に接続されていないトランスフォームパスを剪定し、ビルドで不必要な計算を避けます。
- 抽象的な実装の詳細: ユーザーはエンドツーエンドのパイプラインと希望する出力を記述することに集中します。ビルド、同期、およびその他のオーケストレーションは、Pipeline Builder のバックエンドによって自動的に処理されます。
- 独立したパイプラインロジック: Pipeline Builder は、Spark、Flink、Azure インスタンスなど、異なるロジック実行エンジンに接続できます。
- 再利用性: パイプラインロジックは簡単に抽出され、異なるパイプラインに再利用できます。
- 完全なバージョン管理: ユーザーはパイプラインを個別にドラフトすることも、1 つのパイプラインで共同作業することも、以前のバージョンに戻ることもできます。
- メディア処理トランスフォーム: ユーザーは、パイプライン内でトランスフォーム入力としてメディアセットを渡すことができます。
- 大規模言語モデル (LLMs): LLMs と AIP の力を活用してデータをトランスフォームします。
- 地理空間トランスフォーム: Pipeline Builder を使用して、さまざまな形式の地理空間データを読み込み、トランスフォームし、生成します。
- ストリーミング機能: Pipeline Builder は、リアルタイムのレイテンシーで実行されるパイプラインを作成する機能を提供します。この機能はすべての Foundry 環境で利用できるわけではありません。ユーザーのワークフローでストリーミングパイプラインの利用が必要な場合は、Palantir の担当者にお問い合わせください。
ワークフロー
Pipeline Builder は、データのインポートから健全なビルドの提供まで、次のステップで構成されるワークフローに従います。
- 入力: 新しいデータソースを追加するか、追加のデータセットを追加します。
- トランスフォーム: 希望する出力に向けてデータをトランスフォーム、結合、またはユニオンします。
- プレビュー: トランスフォームを適用した後、出力をプレビューします。
- 配信: パイプラインが完了したら、パイプラインの出力をビルドします。
- 出力: オブジェクトタイプ、リンクタイプ、またはデータセットの出力をパイプラインに追加します。
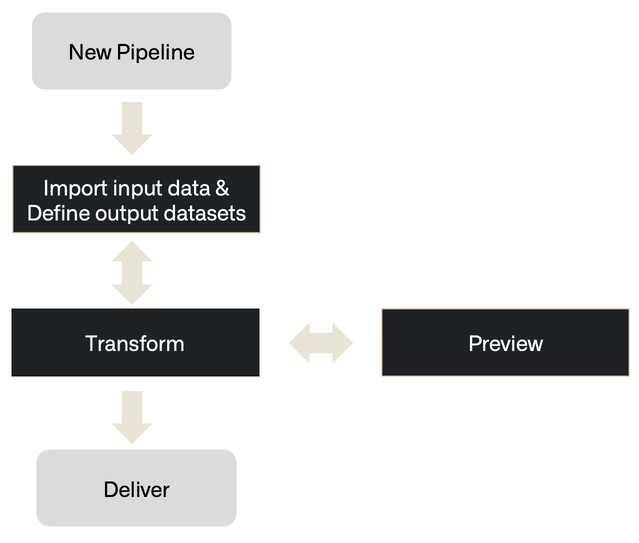
Pipeline Builder のグラフで視覚化すると、ステップが次のように示される場合があります。
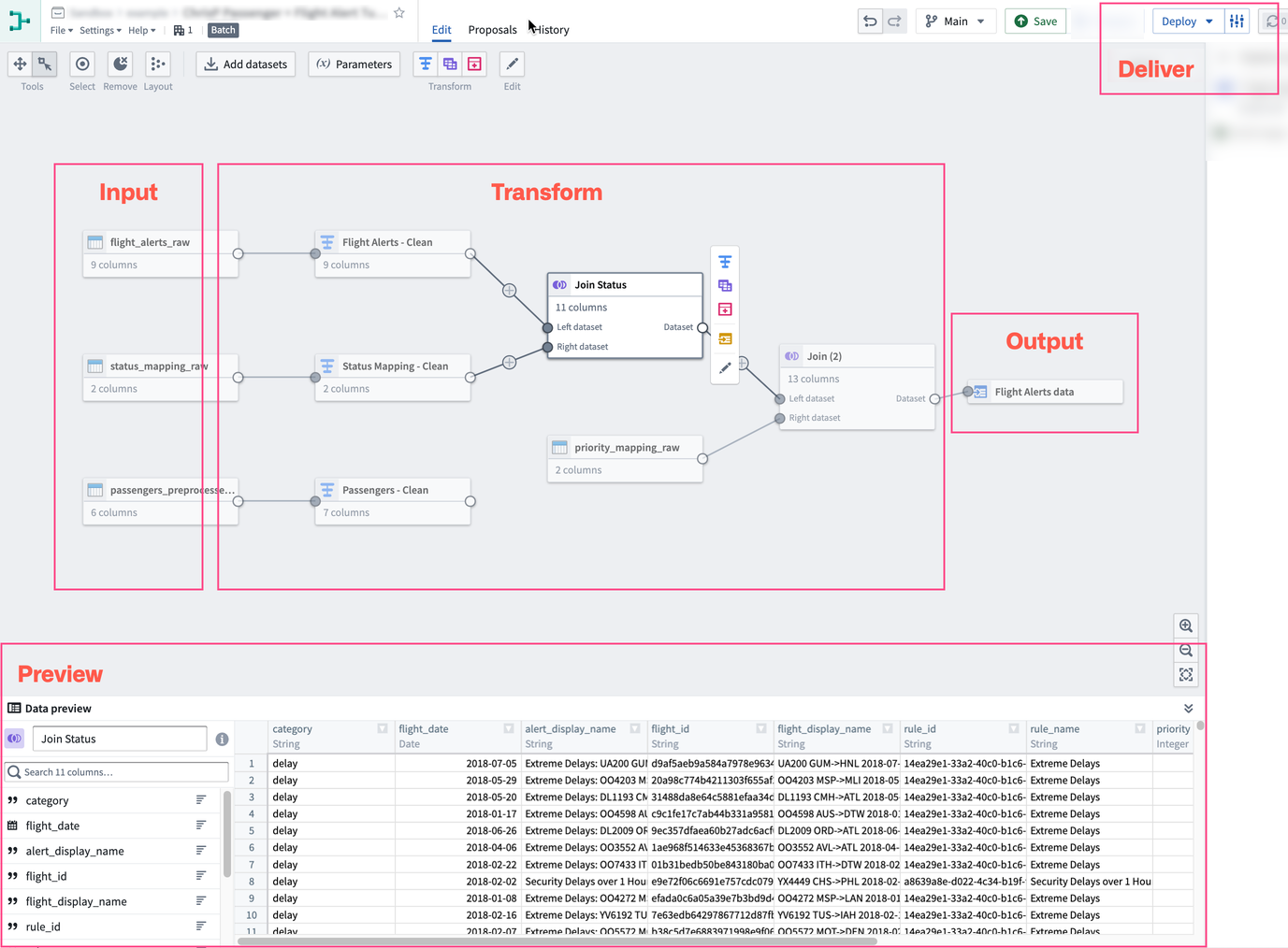
シンプルなバッチパイプラインを作成する方法を学ぶか、Pipeline Builder でパイプラインを構築および管理する基本概念についてさらに学んでください。