注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
パイプラインのプレビュー
プレビューパネルでは、パイプライン内の単一の選択されたノードのロジックと行の統計をプレビューすることができます。ノードを選択し、プレビュー をクリックしてパイプラインを実行します。これにより、プレビューパネルが開き、選択されたノードまでの生データセットからロジックが実行されます。
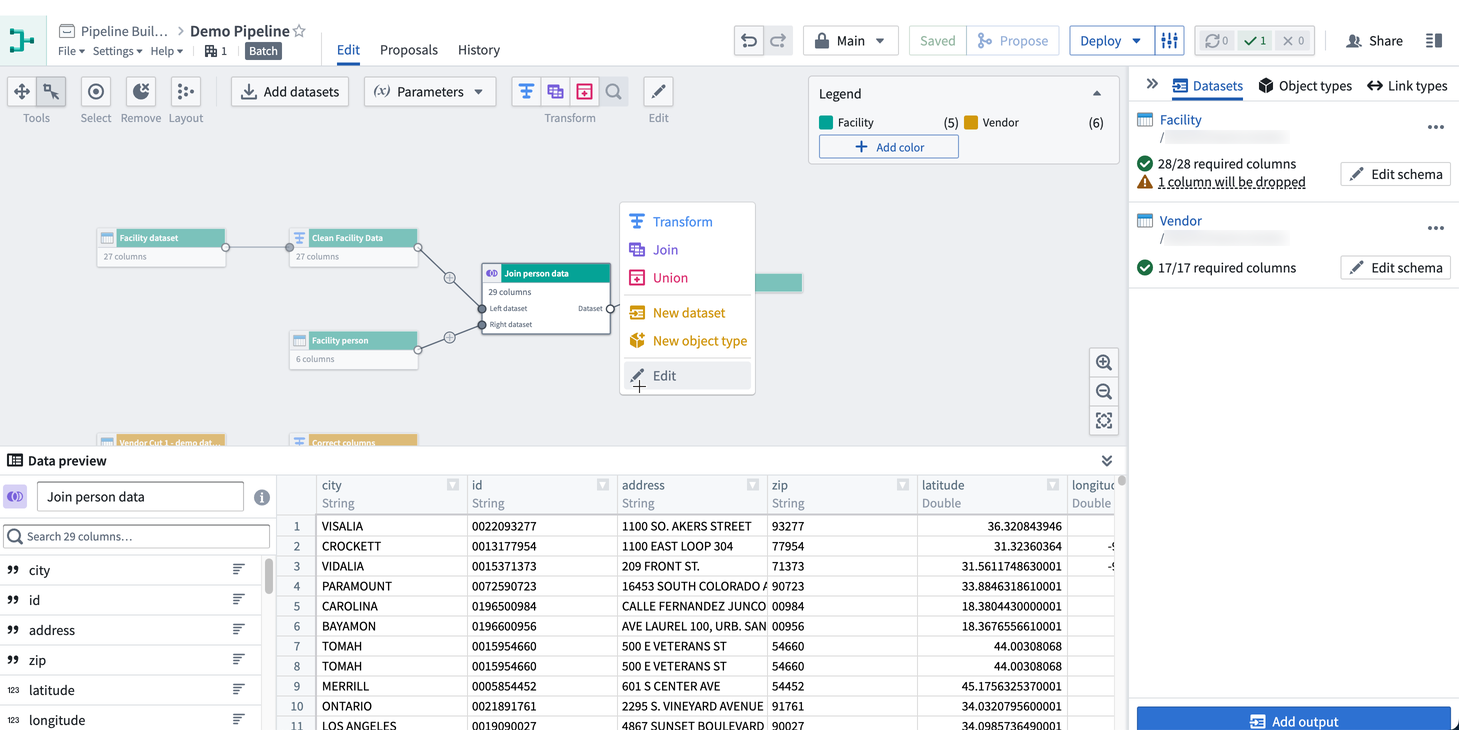
また、グラフの右下にあるアイコンをクリックしてプレビューパネルを展開することもできます。次に、データをプレビューするためにノードをクリックします。
統計情報を表示するには、行を右クリックして統計を表示をクリックします。
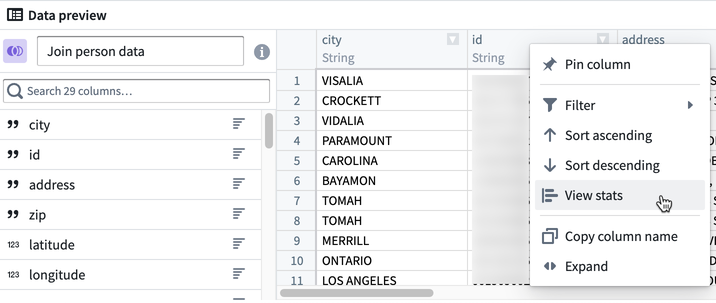
文字列の行の場合、統計表示には値と値の長さのヒストグラム、文字列のケース数、空白、およびnullのインスタンス数が含まれます。数値の行の場合、値の分布が表示され、最小値、最大値、平均値、標準偏差、および異なる値の数などの基本統計情報が表示されます。
行数を表示するには、プレビューパネルの右下で行数を計算を選択します。
プレビュー行数
デフォルトでは、Pipeline Builder はプレビューテーブルで最大 500 行を処理します。この実装では、データセットに 500 行の入力行が必要な場合がありますが、フィルター処理する、結合、重複削除などの多くの操作では、500 行のプレビューを生成するために追加の行が必要になることがあります。
プレビューを高速化するには、入力サンプリング戦略を追加して、プレビューの計算に使用可能な入力行数を制限します。入力サンプリング戦略はプレビューにのみ影響し、ビルドには影響しません。
行数と統計計算は、サンプリングされた入力全体で実行されます。つまり、フルデータセットが使用される場合、行数と統計はフルビルドと一致しますが、サンプル戦略が入力データセットの一部のみを使用するように設定されている場合、行数と統計はこのサンプル全体でのみ計算されます。
例として、600 行の入力データセットがあるとします。
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 600 | row_600 |
プレビューは 500 行に制限されます。これらは必ずしも入力の最初の 500 行ではありません。
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 500 | row_500 |
入力戦略に小さなパーセンテージを設定すると、入力が少量のサンプルに制限され、プレビュー計算が高速化されます。プレビューでわずか 6 行が残されているとしましょう。
| id | value |
|---|---|
| 1 | row_1 |
| 12 | row_12 |
| 33 | row_33 |
| 62 | row_62 |
| 126 | row_126 |
| 527 | row_527 |
次に、定数列 hello に値 world を追加する変換を使用すると、プレビューでは 6 行のサンプル行に対して変換が計算されます。
| id | value | hello |
|---|---|---|
| 1 | row_1 | world |
| 12 | row_12 | world |
| 33 | row_33 | world |
| 62 | row_62 | world |
| 126 | row_126 | world |
| 527 | row_527 | world |
行数を計算すると、6 行が返され、統計はこれら 6 行だけで計算されます。
最終的にパイプラインをビルドすると、サンプリング戦略は影響せず、変換は 600 行の入力行全体で計算されます。