注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
パイプラインのデリバリー
Pipeline Builderでパイプラインを記述し、スキーマエラーを解決したら、パイプラインをデリバリーする準備が整います。
デプロイ vs. ビルド
デプロイは、ユーザーのパイプライン出力のロジックを更新し、ビルドはそのロジックを実行してロジックの変更を実現します。
ビルドは時間とリソースを大量に消費する可能性があり、特にデータスケールが大きい場合や、パイプラインの入力全体を再処理する場合にはその傾向が強いです。このような理由から、パイプラインをビルドせずにデプロイすることを選択する場合もあります。デプロイのみを選択することで、ビルドが必要になるまでビルドのコストを先送りすることができます。
変更のデリバリー
最初のエンドツーエンドのパイプラインをデリバリーし、すべての定義済みロジックを含めたい場合は、上部のツールバーの右側にある Deploy を選択します。

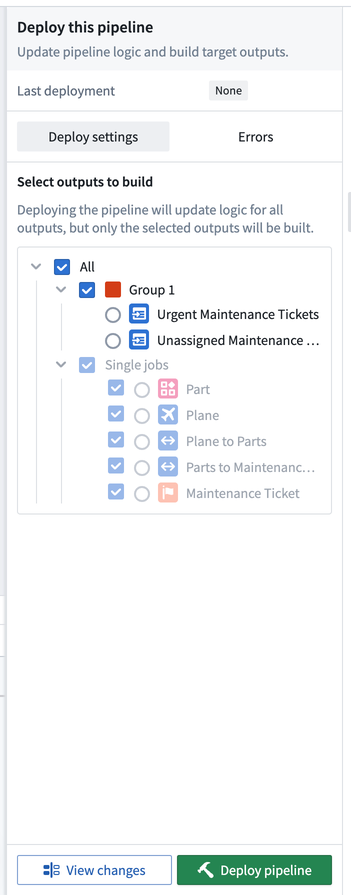
ロジックの変更がデプロイされた後、どの出力をビルドするかを選択できます。ビルドはjob group単位で行われ、任意の job group に含まれるすべての出力またはグループ化されていない個々の出力をビルドすることができます。オントロジータイプの出力は常にビルドされる必要があり、つまり、オントロジータイプの出力を含む任意の job group はビルドされる必要があります。
デプロイの開始に成功すると、グラフの上部に青いバナーが表示されます。View を選択して Build details ビューにアクセスします。

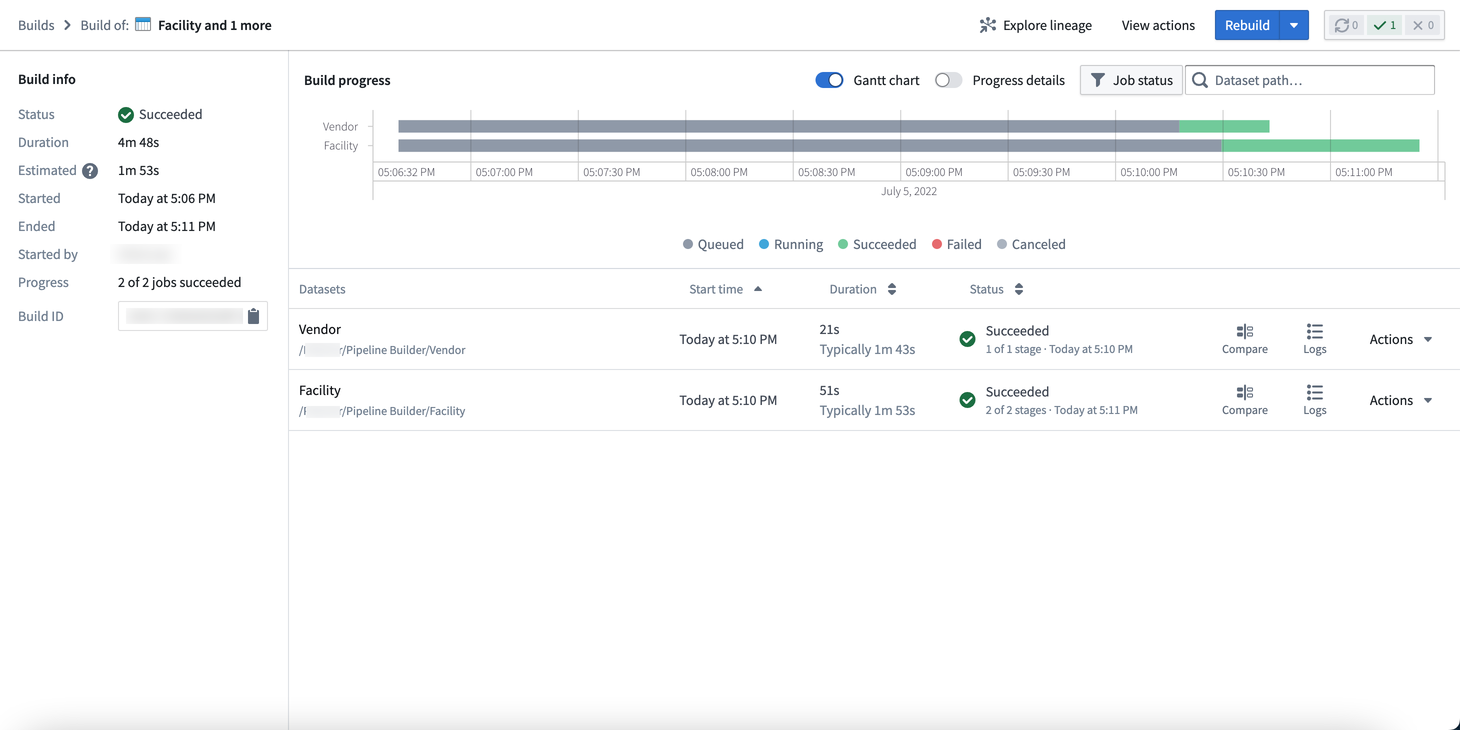
Build details ビューでは、ビルド情報、進行状況メトリクス、ビルドスケジュールの詳細を確認することができます。
-
Build info: パイプラインのステータス、合計所要時間、推定所要時間を表示します。また、開始時間、終了時間、開始ユーザー、ジョブリスト内の進行状況、ビルドIDなど、様々なメタデータを確認することもできます。
-
Build progress: パイプラインのビルドの詳細をガントチャートとして表示します。
-
Build schedule: パイプラインのビルドスケジュールの名前、頻度、ステータス履歴、最終更新日を表示します。
- ビルドスケジュールの作成について詳しくはこちらをご覧ください。
-
Progress details: ビルドが開始されているか、プロジェクトのリソースキューで待機しているか、Sparkアプリケーションを初期化しているか、実行中であるか、終了しているかを切り替えて確認することができます。
ビルド設定
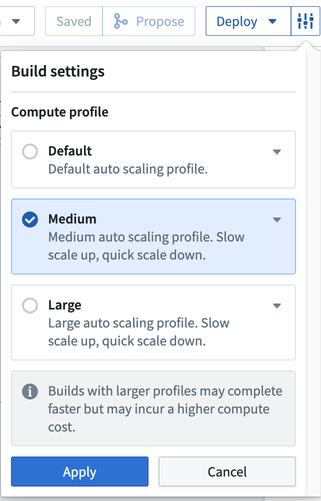
Deploy の隣にある設定アイコンをクリックして、ユーザーのパイプラインの Build settings を編集することができます。以下のコンピューティング設定から選択します:
- Default: デフォルトのオートスケーリングプロファイル。実行コアとメモリの使用量が最小となります。
- Medium: スケールアップは遅く、スケールダウンは速いコンピューティングを提供します。
- Large: スケールアップは遅く、スケールダウンは速いコンピューティングを提供します。
- 注意: 大きなプロファイルのビルドは、コンピューティングコストが高くなる可能性がありますが、完成までの時間が短縮される可能性があります。
保存
Pipeline Builderでは、デプロイを開始せずにパイプラインの変更を保存することができます。この柔軟性により、プロダクションへのロジック変更を確定することなく、ワークフローを編集することが可能になります。
ワークフローに変更を加えた後、上部のツールバーにある Save を選択します。

Propose を最初にクリックすると、現在の状態が自動的に保存されます。
デプロイせずに変更を保存するだけでは、パイプラインのロジックは最新の変更に 更新されません。変換ロジックの変更を反映させるためには、パイプラインをデプロイする必要があります。
出力ノードからのビルド
パイプライングラフの外部に遷移している場合でも、パイプラインのビルドを開始することを選択できます。例えば、出力ノードを右クリックして Open を選択し、データセットプレビューを開くことができます。その後、インターフェースの右上の角にある Build をクリックしてビルドを開始することができます。
パイプライングラフの外部からの Build オプションでは、最後のデプロイ以降に行われた変更はパイプラインロジックに反映されません。ロジックを更新して出力に反映するには、パイプライングラフに戻って Deploy を使用してください。
ストリーミングパイプラインの追加オプション
ストリーミングパイプラインを実行している場合、追加のオプションが利用可能となります。ストリーミングパイプラインは一部のアカウントでのみ利用可能です。詳細については、ユーザーのPalantir代表者にお問い合わせください。
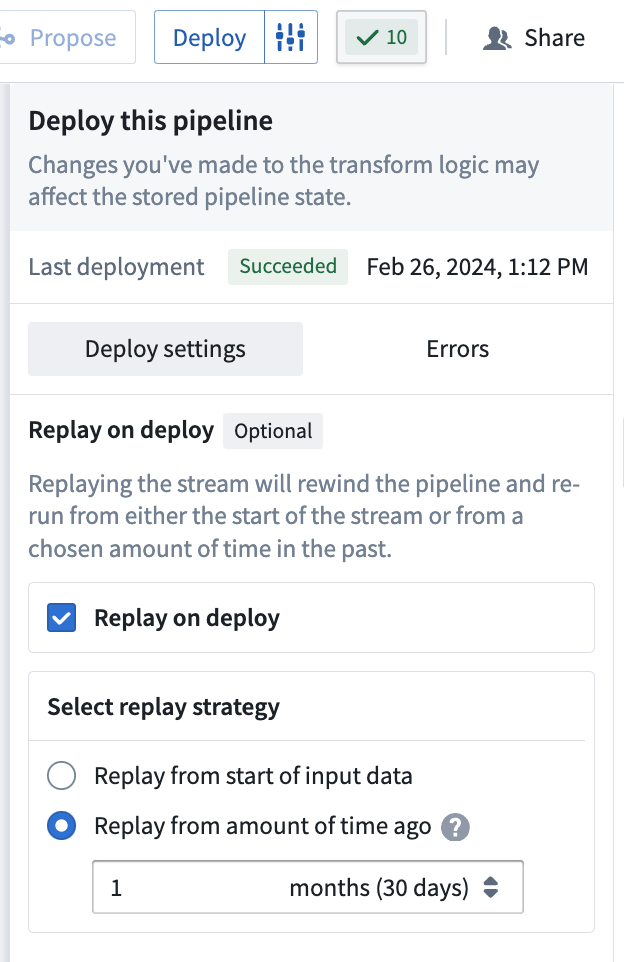
必要に応じて Replay on deploy を使用して、パイプラインの計算を特定の過去の時間点から開始するように指示することができます。
Deploy ウィンドウで、パイプラインデリバリーのデータ処理の開始時間を選択します:
- Start of input data: 入力ストリームの開始からすべてのデータが処理されます。
- From a specified time: 処理を開始したい時間を選択します。この時間より前のデータは処理されません。例えば、最後の2ヶ月間のデータのみを含めたい場合は、
2 monthsagoを選択します。
パイプラインのリプレイは、長時間のダウンタイムを引き起こす可能性があります、最大数日間に及ぶ可能性があります。パイプラインをリプレイすると、ストリームの履歴が失われ、すべての下流パイプラインの消費者はリプレイを行う必要があります。
リプレイに関する詳細は、breaking changesのドキュメンテーションを参照してください。
Redeploy vs. replay
ストリームの再デプロイは、以前に保存されたチェックポイントからストリーミングジョブを再開するプロセスを指します。ストリーミングジョブが一時停止または停止されると、データ内にブックマークが作成され、それまでに読み取られたレコードの位置が示されます。ブックマーク(またはチェックポイントとも呼ばれます)は、ストリームが実行中にも定期的に作成されます。これにより、ストリームが何らかの理由で障害を発生した場合でも復旧が可能となります。
これにより、ストリームが再起動されると、その特定のチェックポイントから処理が再開されます。再デプロイ中には、既存の出力ストリームが保持され、新たなデータが追加されます。
一方、ストリームのリプレイは、出力ストリームの新しいビューを生成することを含みます。データセットに新しいビューを設定することは、新しいデータを含む新しいストリームと見なされますが、以前のビューからのデータへのアクセスは依然として可能です。ストリームのリプレイが必要となる、またはストリームのリプレイが利点を提供する様々な状況があります:
- Pipeline Builder のパイプラインのロジックを変更し、出力データを更新したロジックに準拠させる必要がある場合、ストリームをリプレイして処理を開始または指定した時間点から再開することで、これを実現することができます。これにより、出力ストリームのデータが更新された変換ルールと一致します。
- ブレーキングチェンジの場合、リプレイが強制されます。詳細は breaking changes のドキュメンテーションを参照してください。
- パイプラインの入力ストリームがリプレイされている場合、出力ストリームのデータの一貫性を維持するために、下流のパイプラインもリプレイする必要があります。
パイプラインのリプレイは、リプレイの開始点によっては数日間に及ぶ長時間のダウンタイムを引き起こす可能性があることに注意してください。パイプラインをリプレイすると、出力ストリームのすべてのデータが失われます。以前のストリームのデータを保持したい場合は、出力を新しい宛先に向けることができます。ただし、将来的に元の出力ストリームにレコードをプッシュするつもりであれば、パイプラインをリプレイする必要があります。
ストリームを再デプロイするには、初回のデプロイで使用したのと同じ手順を使用します。Pipeline Builder インターフェースで Deploy を選択します。
ストリームをリプレイするには、追加の設定を加えて Start of input data からリプレイするか、From a specified time からリプレイするかを選択します。