注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
カスタム関数の作成
カスタム関数を使用すると、一連の変換を単一の変換として保存し、パイプライン全体で再利用することができます。この機能は、パイプライン全体でロジックを繰り返しながら、それを一箇所で管理するのに便利です。
カスタム関数は、名前 (必須)、説明 (オプション)、関数引数 (オプション)、および 関数定義 (必須) で構成されます。
カスタム関数を作成するには、以下の2つの手順が必要です:
- ロジックを一連の変換ボードとして定義します。
- 変換ボードを新しいカスタム関数に変換します。
以下では、各ステップの例を見ていきます。
一連の変換ボードを定義する
users のテーブルがあると仮定し、それぞれのユーザーを一意に識別するプライマリーキーを作成したいとします。各ユーザーの first_name、last_name、および first_login_date が一意の組み合わせであることがわかっています。これら3つの行をハッシュ化したものが String 型の新しい行 primary_key をデータセットに追加したいと考えています。そして、first_name、last_name、および first_login_date を削除します。最後に、重複がある場合はユーザーごとに1行だけ残し、age の値が最も低い行を保持したいと考えています。
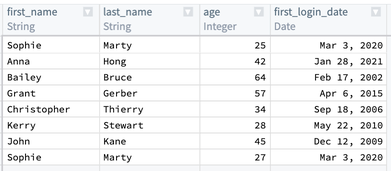
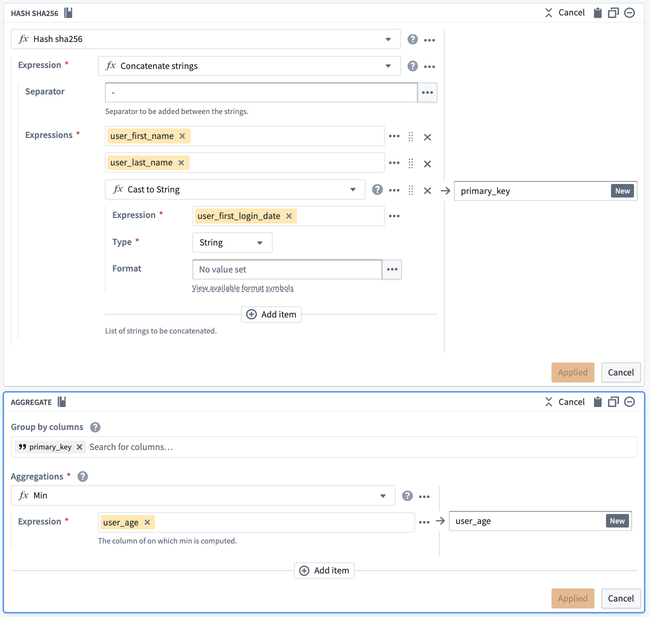
まず、first_name、last_name、および first_login_date を1つの行に結合します。これら3つの行を一緒に加えるために Concatenate strings 変換を使用できます。

Separator フィールドには - を入力します。次に、Expressions ドロップダウンから各行を選択します。最初の2つの行では first_name と last_name を選択します。しかし、first_login_date 行は、第三のフィールドとして選択するオプションにはなりません。これは、Date 型であり、Concatenate strings 関数は String 型のみを受け付けるためです。
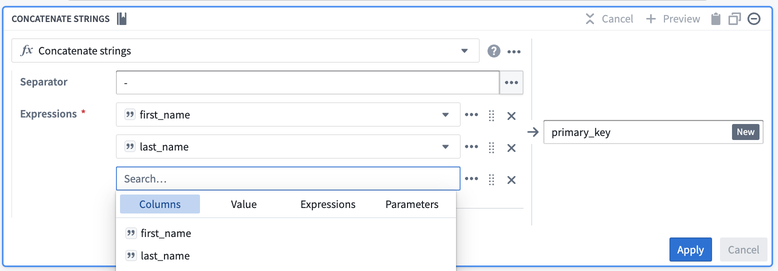
これを解決するためには、Expressions タブから Cast 式を挿入します。パラメーターは Expression に first_login_date を、Type に String を設定します。これにより、first_login_date を全体的に変更する必要がなくなり、これによりすべての下流変換ボードが影響を受けることを防ぎます。

Apply を選択すると、出力テーブルは以下のようになります:
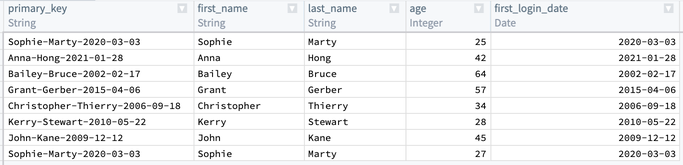
次に、primary_key 内のデータを非識別化する必要があります。これを行う一つの方法は、primary_key の各値に Hash sha256 変換を適用してハッシュを作成することです。これは、Reuse value オプションを選択して Concatenate strings を Hash sha256 で置き換えることで、同じボード内で行うことができます。
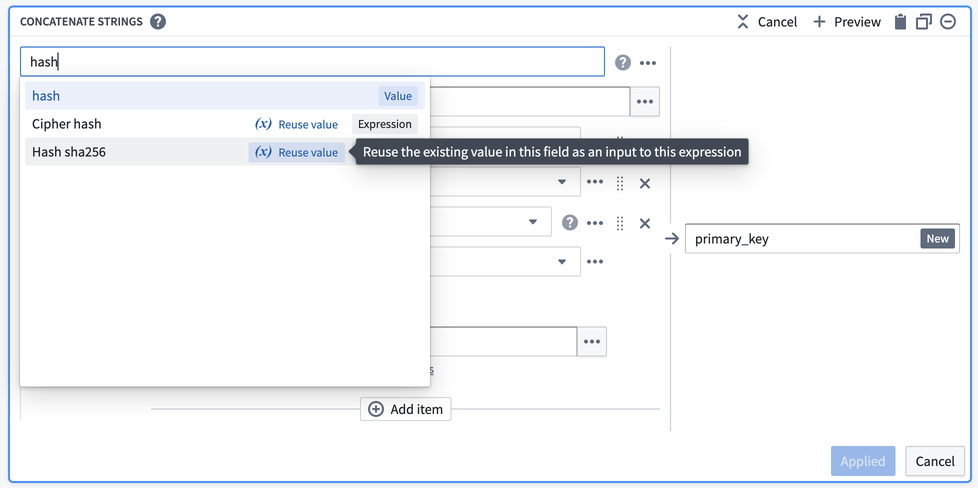
このオプションは、既存の値を保持し、それらを新しい変換の最初の入力にします。
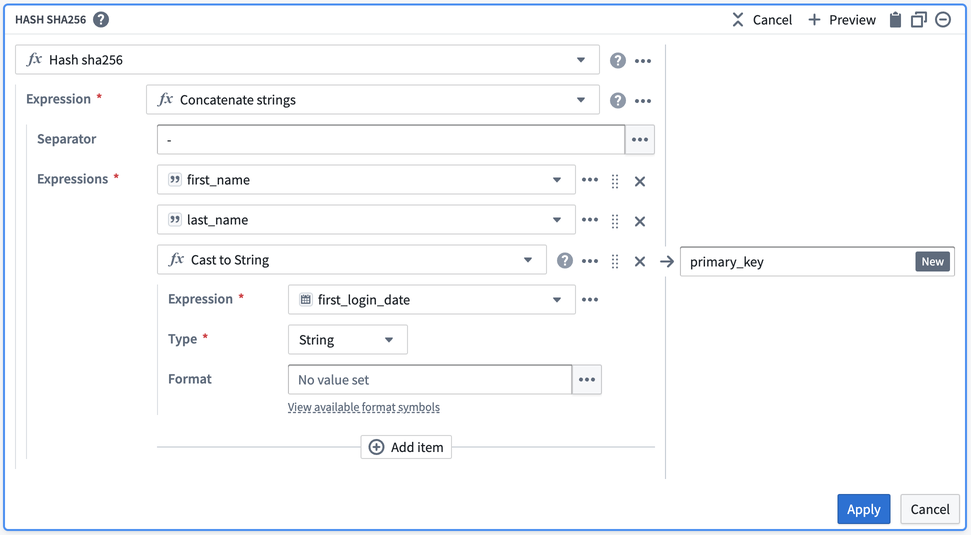
Apply を選択した後、出力が期待通りであることを確認します:各行についての一意のデータを含む primary_key: String 行があります。
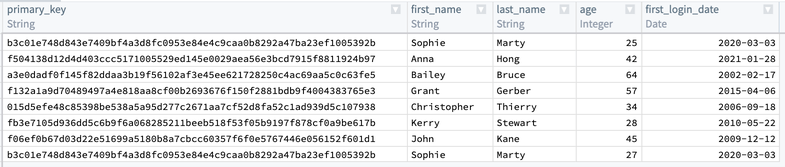
次に、primary_key の最初と最後の行が同じであることに気づくでしょう。age が25の行を保持し、first_name、last_name、および first_login_date を削除したいと考えています。これを行うには、Aggregate 変換を追加します。最初のフィールド Group by columns に primary_key を入力し、二つ目のフィールド Aggregations に age を入力し、Min 式を使用します:
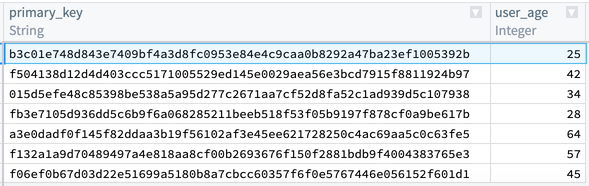
最後に、出力テーブルは以下の画像のようになるはずです。primary_key = b3c01... に対して1行だけがあり、age が25であることを確認できます。
一連の変換ボードをカスタム関数に変換する
次に、このロジックをパイプライン内の3つの異なる場所で再利用したいとします。私たちは、Shift + Down Arrow を使用して両方のボードを選択し、上部のバーで + ボタンを選択することで、ロジックをカスタム関数に変換することができます。
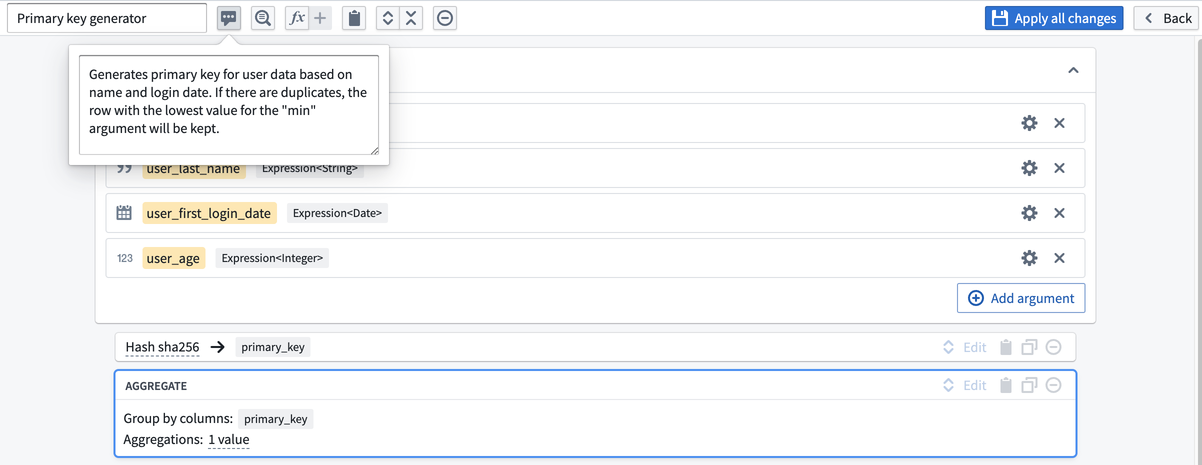
これにより、カスタム関数の作成ページに移動します。行入力 first_name、last_name、first_login_date、および age が取り消されていることに気づくでしょう。これは、作成する関数がパイプライン内の任意の4つの入力(行名に関係なく)に対して一般的であるためです。
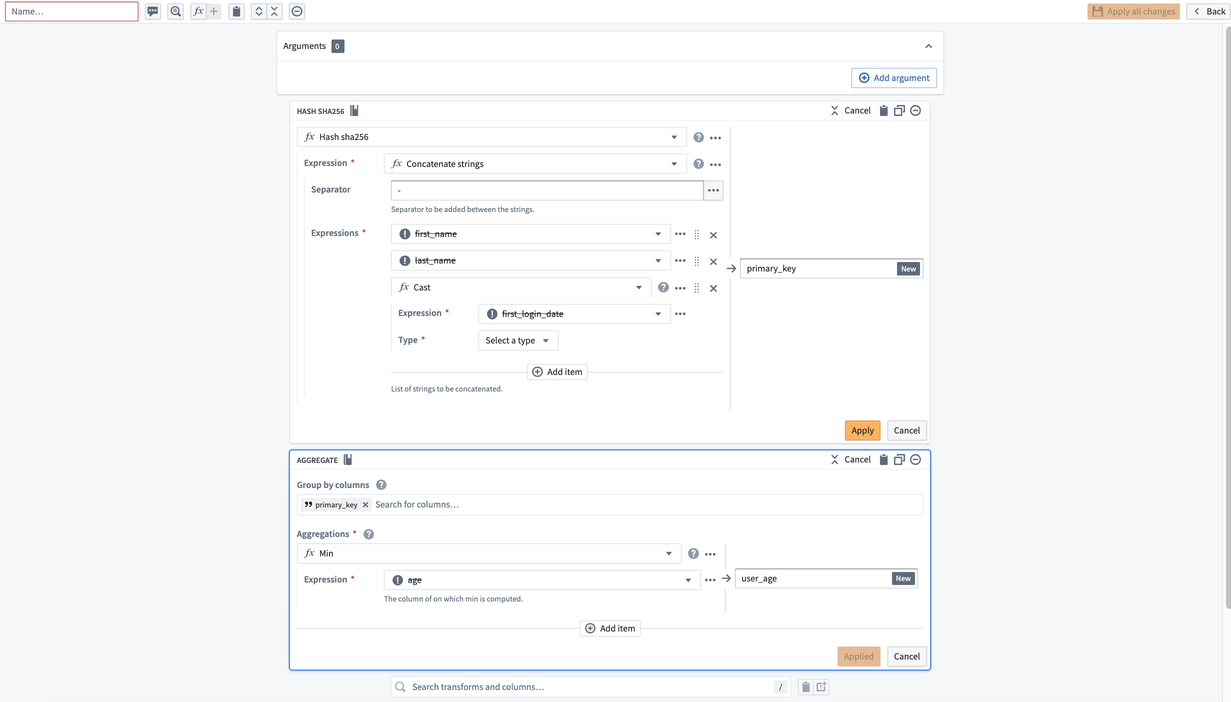
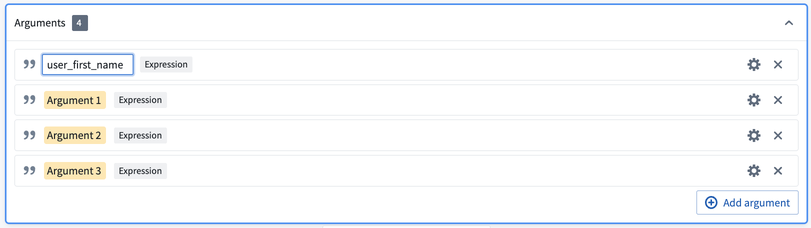
これらの入力を定義するには、Add argument を4回選択します。黄色のボックスをクリックして引数名を設定します。
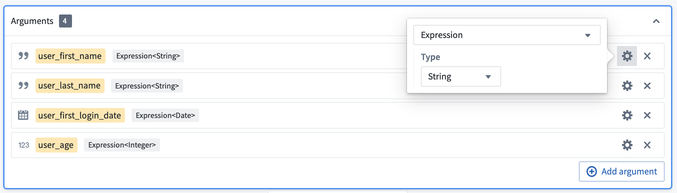
次に、各引数の右側の歯車アイコンをクリックして引数の型を設定します。ここでは、最初の2つの引数を String 型の列を表す Expression<String> 型に、3つ目の引数を Expression<Date> 型に、最後の列を Expression<Integer> 型にしたいと考えています。
これで、新しい引数を以前と同様に2つのボードに追加できます。ただし、これらは現在 Columns セクションではなく、Parameters セクションで利用可能になります。
設定が完了したら、関数に Primary key generator という名前を付け、オプションで説明を追加し、Apply all changes を選択します。
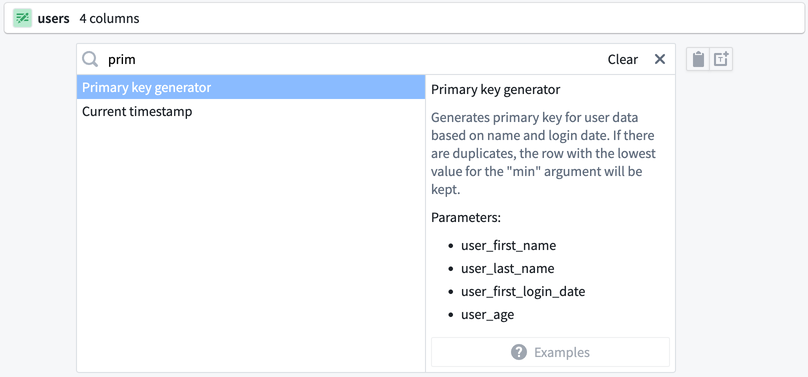
新しい関数は、任意の変換パスで使用できるようになります。次にこのパターンでプライマリーキーを作成する必要がある場合は、変換ドロップダウンで Primary key generator を検索できます。
元の行: first_name、last_name、first_login_date、および age でカスタム関数を設定できます。
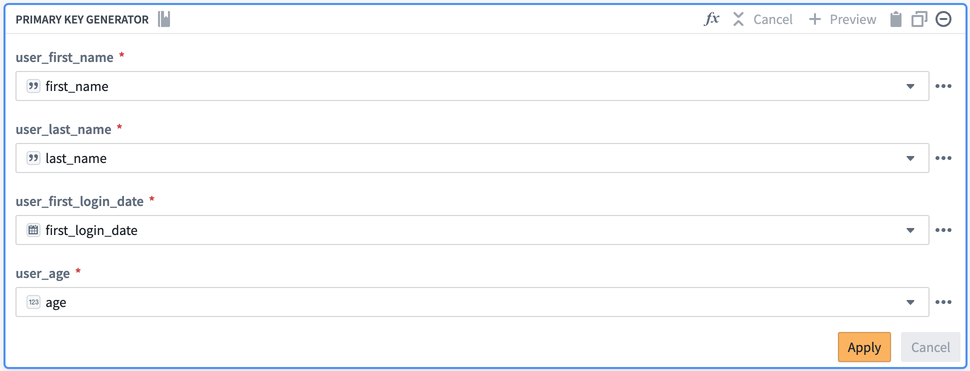
関連する列名をカスタム関数に入力することで、パス内に同じ変換で関数を作成したかのように同じ結果を生成します。ただし、カスタム関数を作成することで、関数ロジックを保存し、別の変換ボードでロジックを再作成するのではなく、パイプライン全体で再利用することができます。