注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Checkpoints
パイプラインを構築する際には、複数の出力間で共有されるトランスフォームノードを使用することがよくあります。このロジックは通常、各出力ごとに 1 度再計算されます。Pipeline Builder のチェックポイントを使用すると、次のビルド中に中間結果を保存するためにトランスフォームノードを「チェックポイント」としてマークできます。そのチェックポイントノードの上流にあるロジックは、すべての共有出力に対して 1 度だけ計算され、計算リソースを節約し、ビルド時間を短縮します。
チェックポイントはバッチパイプラインでのみ利用可能です。出力は同じジョブグループ内にある必要があり、チェックポイントノードがパイプラインの効率を向上させます。Pipeline Builder におけるジョブグループについてさらに詳しく知る。
チェックポイントノードを追加する
以下は 2 つの出力(Attachment と Request)を生成するパイプラインの例です。トランスフォームノード Checkpoint は 2 つの出力間で共有されています。この現在の状態では、ロジックノード Clean と Checkpoint は各出力ごとに 2 度計算されます。
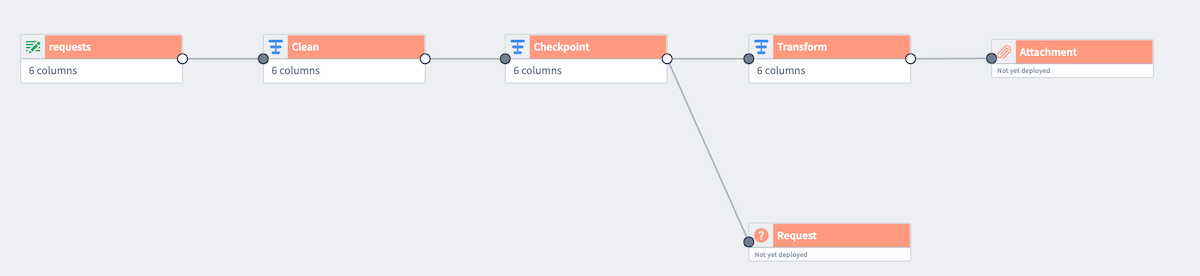
しかし、Clean と Checkpoint を 2 つの出力に対して 1 度だけ計算したいと考えています。これを行うには、Checkpoint を右クリックし、Mark as checkpoint を選択します。
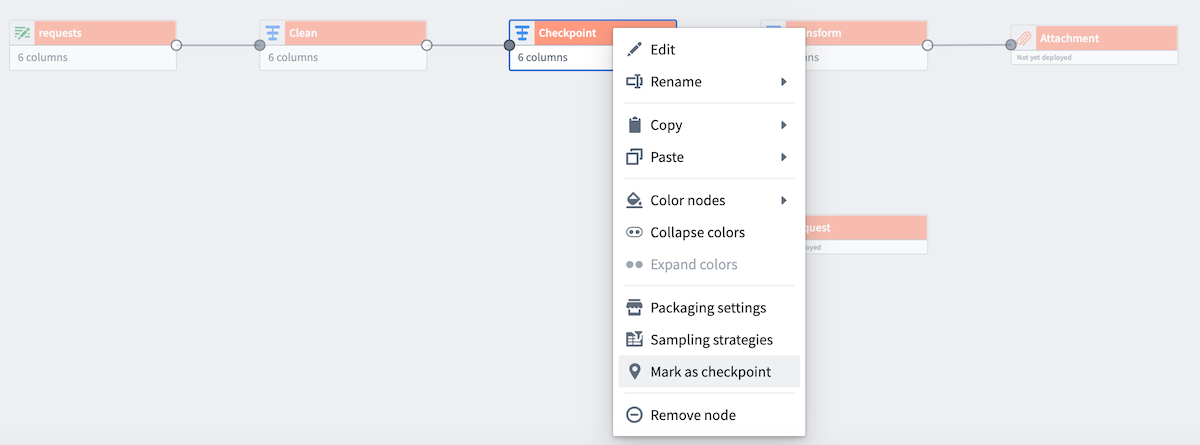
Checkpoint ノードの右上隅に薄い青色のバッジが表示されます。
![]()
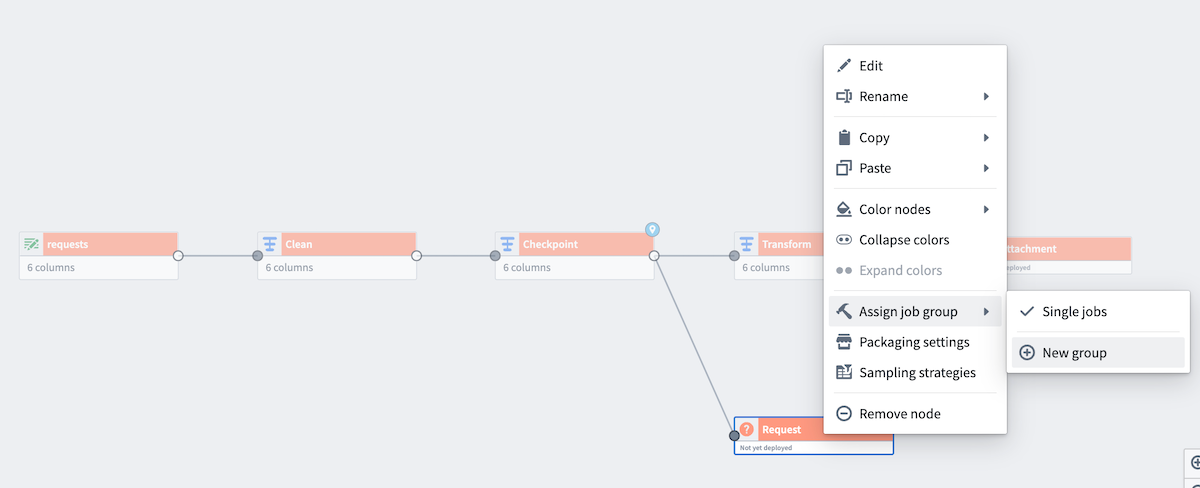
次に、チェックポイントの動作を確認するために、両方の出力を同じジョブグループに追加します。出力の 1 つ(Request)を右クリックして Assign job group を選択します。New group を選択して Build settings パネルを開きます。
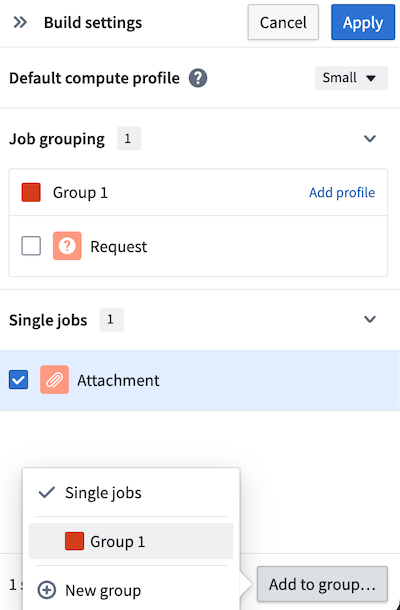
デフォルトではデータセットは異なるジョブグループにあるため、チェックポイントは各出力ごとに再計算され、利益が無効になります。これを修正するために、他の出力(Attachment)を同じジョブグループに追加します。出力を選択し、パネルの下部にある Add to group... を選択します。
カラーグループ および ジョブグループ を使用して Pipeline Builder のノードを構成する方法についてさらに詳しく学びます。
チェックポイントのストレージコスト
チェックポイントはトランスフォームの結果全体を Hadoop Distributed File System (HDFS) などのストレージにプッシュします。たとえば、結合をチェックポイントすると、結合の結果全体がストレージに出力されます。これにより、データセットの出力が小さくても、大量のデータが保存される可能性があります。