Warning
注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
データ期待値
データ期待値は、データセットの出力に適用できる要件です。これらの要件(「期待値」として知られています)は、データパイプラインの安定性を向上させるチェックを作成するために使用できます。
データ期待値は、各パイプラインの出力に設定でき、結果として得られる出力に期待値を定義します。現在、Pipeline Builder は主キーと行数の2つのデータ期待値をサポートしています。
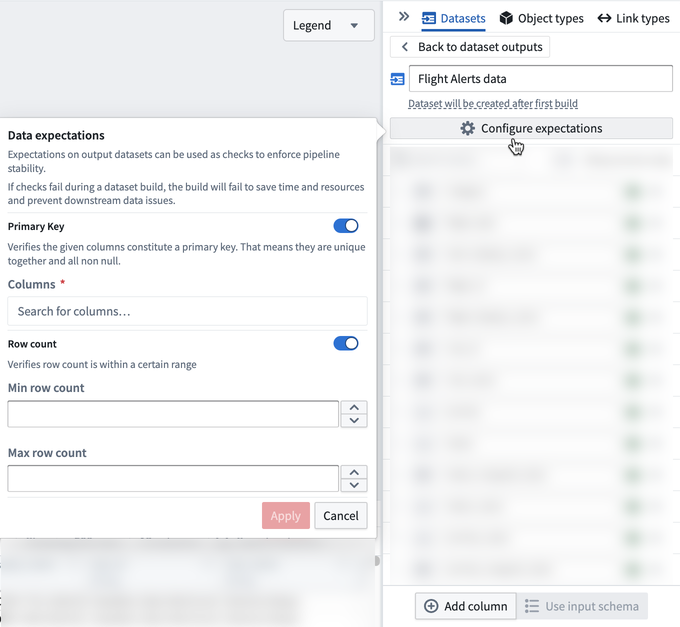
期待値が満たされない場合、ビルドが失敗します。ジョブ期待値ペインには、どのデータ期待値が成功し、どの期待値が失敗したかが表示されます。
主キーのデータ期待値
主キーのデータ期待値は、1つまたは複数の列名が指定され、以下を確認します。
- 各列に null 値がないこと。
- 列の組み合わせが一意であること。
主キーのデータ期待値の例
特定の列が選択されている場合、その下のすべてのエントリが一意であることを確認します。
2つの列が選択されている場合、両方の列の組み合わせが一意であることを確認します。
この例では、データセットに存在する2つの列、idとtimeを使用します。
例のデータセット:
| id | time |
|---|---|
| 1 | 8pm |
| 1 | 9pm |
| 2 | 8pm |
| 3 | 8pm |
上記の例はチェックに合格します。これは、1と8pmが個別に繰り返されていても、idとtimeの組み合わせが一意であるためです。
逆に、次の例では失敗します。
| id | time |
|---|---|
| 1 | 8pm |
| 2 | 9pm |
| 1 | 8pm |
この表は、1 と 8pm の組み合わせが繰り返されているため、チェックに失敗します。
行数のデータ期待値
行数の期待値は、最小および/または最大の行数が指定されます。
最小行数が指定されている場合、期待値は指定された行数以上であることを確認します。
最大行数が指定されている場合、期待値は、最大でこれだけの行数があることを確認します。