注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Spark の詳細を理解する
Apache Spark ↗ は、Foundry のデータ統合層で最も一般的に使用される実行エンジンです。パイプラインのパフォーマンス特性を理解し、パイプラインを最適化する方法を見つけるためには、コードが Spark でどのように実行されているかの詳細を理解することが重要です。Foundry は、Spark でのジョブのパフォーマンスを表示および理解するための統合ツールを提供しています。このページでは、利用可能な Spark の詳細について説明し、それらの詳細が意味することについてのガイダンスを提供します。
Spark の詳細へのアクセス方法
Foundry で構築された任意のデータセットについて、以下の手順で Spark の詳細を表示します。
- ビルドレポートを表示。
- データセットプレビュー から、または Data Lineage から 履歴 タブを選択し、リスト内の個々のビルドを選択してから ビルドレポートを表示 を選択します。
- すべてのビルド の表示から、リスト内のビルドを選択するだけです。
- ジョブを選択。ビルドは1つ以上のジョブで構成され、ガントチャートの下に表示されるリストで表示されます。リストからジョブを選択し、Spark の詳細 ボタンを選択します。

Spark の詳細ページでは、Spark でのジョブの実行に関する情報が提供されます。各ジョブについて、Spark の詳細ページは以下のように表示されるさまざまなカテゴリの情報を表示します。

概要タブ
概要タブでは、ジョブに関する以下の情報が提供されます。
高レベルのジョブメトリクス
- すべてのタスクの合計ランタイム: すべてのステージのすべてのタスクのランタイムの合計
- ジョブの期間: Spark の計算の期間(最初のステージの開始から最後のステージの完了までの時間)
これらの2つのメトリックを使用して、並行性比を次のように計算できます。
すべてのタスクの合計ランタイム / ジョブの期間
比が 1 に近いことは、並行性が悪いことを示しています。
-
ディスクスピル: すべてのステージ全体で、エグゼキュータの RAM からディスクに移動されたデータのサイズ。
- これは、データがエグゼキュータのメモリに収まらない場合に発生します。ディスクへの書き込みと読み込みは遅い操作であるため、ジョブがスピルすると、著しく遅くなります。場合によっては、計算の種類によって、スピルがエグゼキュータのメモリ不足を引き起こし、ジョブが失敗することがあります。
- 大規模なデータセットの場合、ディスクスピルが発生することが予想されます。
-
シャッフルの書き込み: ジョブ全体でシャッフルされたデータの量。
- シャッフルは、データが Spark ステージ間やパーティション間で移動するプロセスです。例えば、ジョインを計算する場合(テーブルのいずれもブロードキャストされない場合)、集約を行う場合、または再パーティションを適用する場合です。
- シャッフルは、ネットワーク IO とディスク IO の両方を引き起こすため、ジョブのランタイムの大部分を占めることがあります。
- したがって、パフォーマンスの高い Spark ジョブを作成する主要な目標は、シャッフルを最小限に抑えることです。例えば、ブロードキャストできるジョインが実際にブロードキャストされるようにすることや、同じキーで下流のジョブで頻繁にジョインまたは集約されるデータセットのバケット化を利用することで(このデータセットの下流シャッフルを回避する)、不要な再パーティションステップを回避することです。
ステージ実行タイムラインとステージ間の依存関係
ジョブの開始時に、Spark はトランスフォームのコードを解釈して実行計画を作成し、それを相互依存関係を持つ一連のステージとして表現できます。以下のグラフは、ステージの実行タイムラインを示しています。
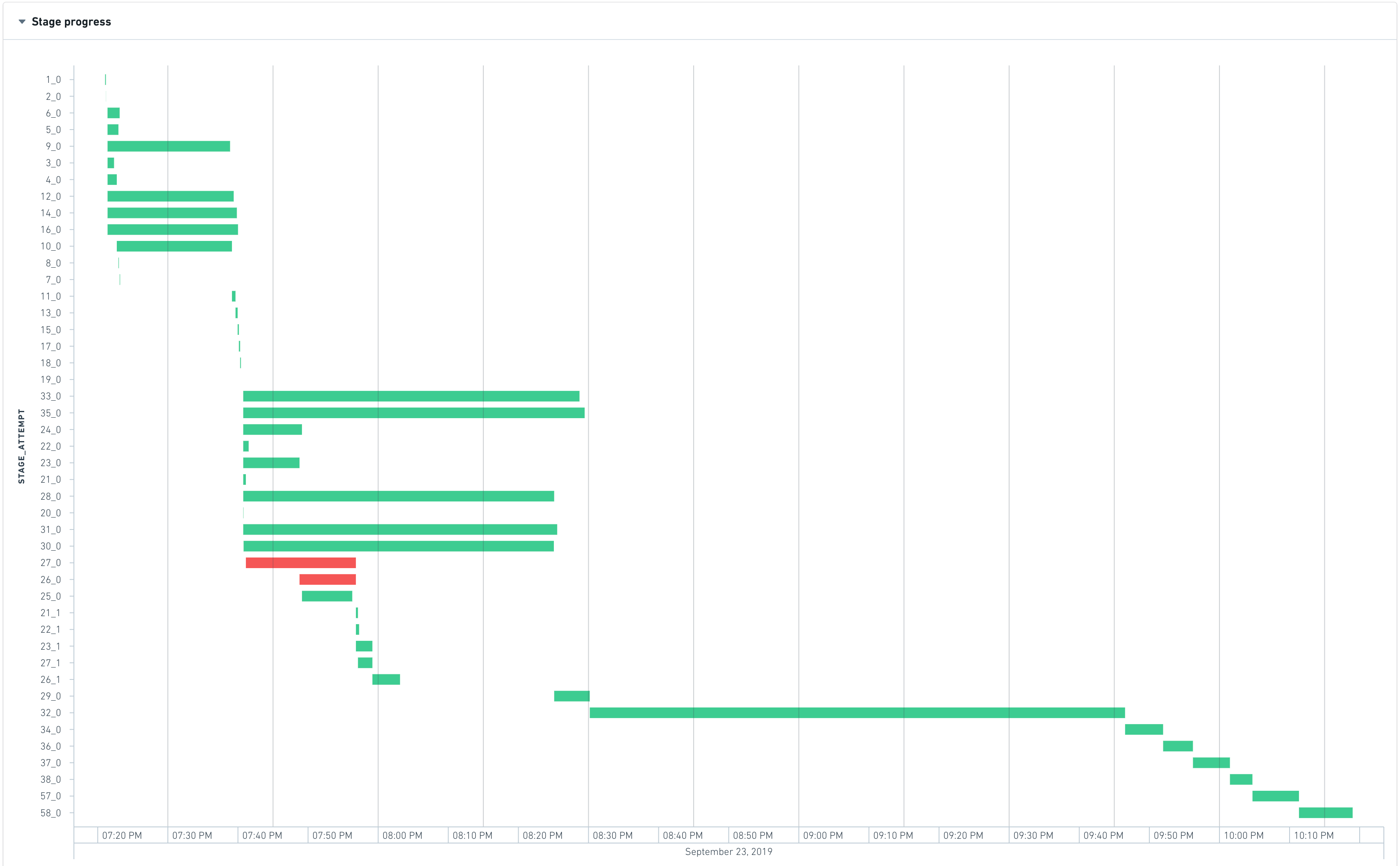
最も左側のステージは通常、入力のロードを表し、最も右側のステージは通常、出力の書き込みを表します。 上記の例では、ステージ28、30、31、32、33、35 の実行に時間がかかるため、このジョブのランタイムを最適化するための良い候補です。
ステージ 28、30、31、33、35 は並行して実行できるため、相互依存関係はありません。しかし、ステージ 32 は、前のすべてのステージが終了したときにのみ開始されるため、以下のことが意味されます。
- ステージ 35 のランタイムを短縮しても、待ち時間は max_runtime(28, 30, 31, 33, 35) によって支配されるため、大幅な改善は得られません。目に見える改善を得るためには、これらのステージすべてが加速されなければなりません。
- ステージ 32 はジョブのボトルネックであり、ジョブの総期間の約 35% を占めています。
タスク並行性チャート
タスク並行性チャートは、リソースの使用状況を理解するのに役立ちます。ステージの並行性を時間とともにプロットします。ジョブの並行性と同様に、ステージの並行性は次のように計算できます。
ステージ内のタスクの合計ランタイム / ステージの期間
タスク並行性チャートの時間軸は、上のガントチャートのステージと共有されているため、相関関係を特定しやすくなっています。

上記のチャートでは、ステージ 32 の並行性はほぼ 1 です。これは、このステージで行われるほぼすべての作業が1つの(非常に長い)タスクで行われることを意味し、計算が分散されていないことを示しています。
完全に分散されたジョブは次のようになります。

ステージ詳細
特定のステージが失敗したり遅くなったりする理由を理解しようとするとき、より詳細な情報が役立ちます。残念ながら、現在のところ、ステージに変換するコードの元になるものを自動的にトレースすることはできません。これは、Spark がコードをステージに変換する際に、このリファレンスを公開していないためです。
しかし、ステージの概要では、失敗したり実行時間が長かったりするステージの調査が可能です。

タスクの半分が2秒未満で終了しますが、最も興味深いのは最大ランタイムです。1つのタスクがステージの合計ランタイムの約63%を占めています。これは、以前のチャートでこのステージがボトルネックであり、ほぼすべての作業が1つのタスクで行われていることを示す観察と一致しています。
さらに詳細を知るために、ステージの詳細にジャンプすることができます。
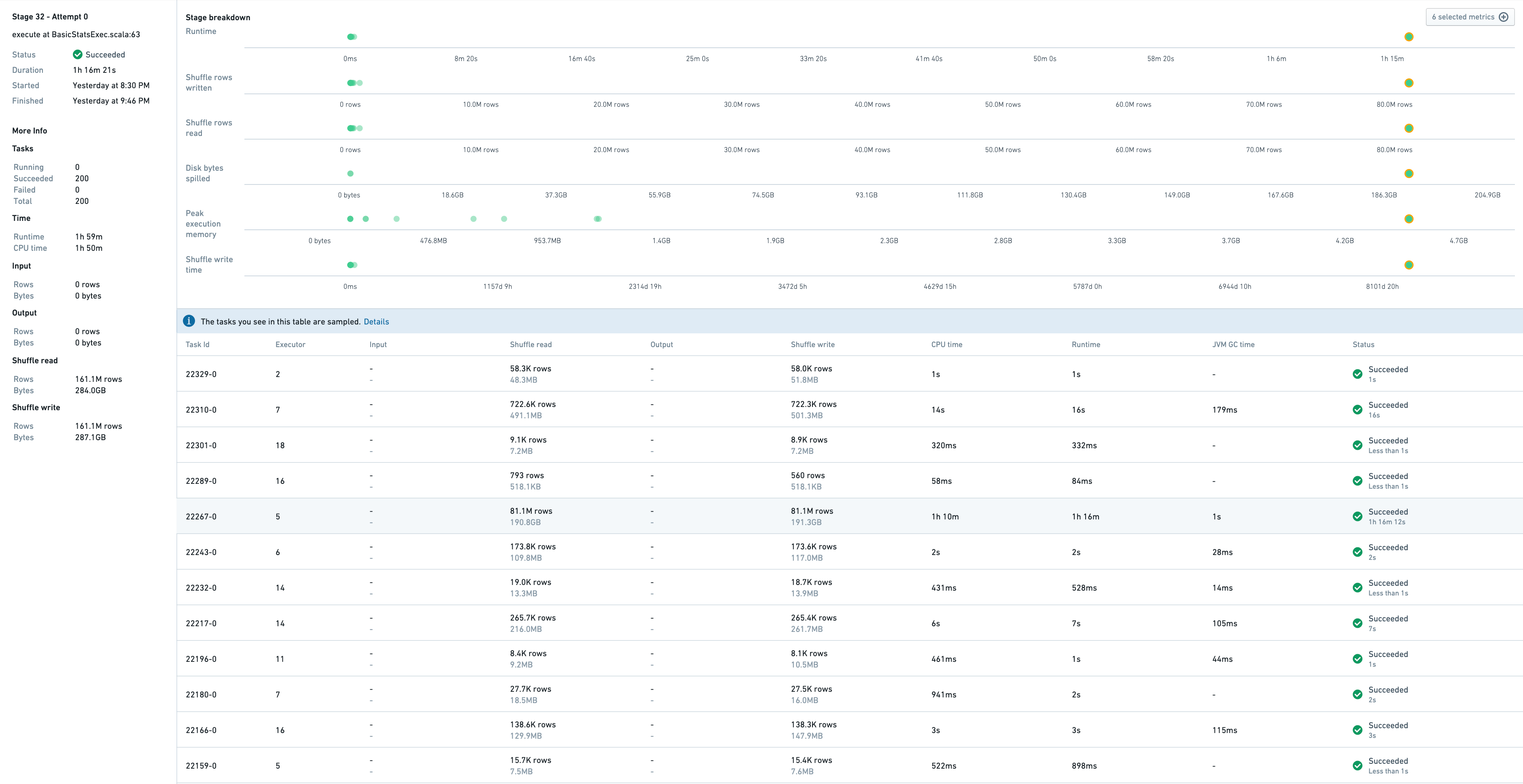
これは、このステージで実行されたタスクのサンプルと、ステージ自体に関連するメトリックを示しています。
タスク 22267-0 は 1 時間 16 分かかるため、最も遅いものです。実際、このタスクは 8100 万行を処理していますが、他のタスクは 1 万~ 70 万行を処理しています。この歪みの症状は以下の通りです。
- 高いディスクスピル: 190 GB 対 他のタスクでは 0
- 高いエグゼキュータのピークメモリ: 4.5 GB 対 他のタスクでは 1 GB
エグゼキュータタブ

エグゼキュータ タブは、Spark ジョブのドライバーやエグゼキュータからの特定のメトリックをキャプチャし、スタックトレースやメモリヒストグラムを含みます。これらのメトリックは、Spark ジョブのパフォーマンスの問題をデバッグする際に役立ちます。
スナップショット ボタンを選択すると、実行中のジョブから Java スタックトレースまたはドライバーのみのメモリヒストグラムがキャプチャされます。ジョブが実行中の状態でなければなりません(ジョブが完了している場合、これらのメトリックはもう収集できません)。
スタックトレースは、Spark ジョブの各スレッドがその時点で実行している内容を確認する方法です。たとえば、ジョブがハングしているように見える場合(つまり、予想される進行がない場合)、スタックトレースを取ることで、その時点で実行されている内容が明らかになります。
メモリヒストグラムは、現在ヒープ上にある Java オブジェクトの数とそのサイズ(バイト単位)を示します。これは、メモリの使用状況を理解し、メモリ関連の問題をデバッグする際に役立ちます。
メトリックを取得することは、実行中のジョブのパフォーマンスに影響を与える場合があります。これらのメトリックを収集するためには、JVM によって追加の作業が必要です。例えば、メモリヒストグラムを取ると、ガーベジコレクションがトリガされます。