注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Spark UI
Spark には Web UI ↗ があり、Foundry の Spark details ページを補完して以下の追加情報を提供します。
- エグゼキューターのライフサイクル情報(エグゼキューターの起動とシャットダウンなど)。
- タスクとエグゼキューターのメトリクスの大規模なサンプル(ピークメモリ使用量など)。
- 実行中に使用されるすべての Spark 設定。
Spark UI の表示
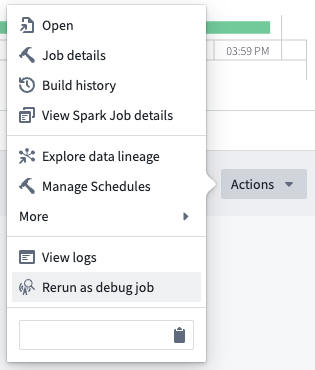
Transforms ジョブの Spark UI を表示するには、ジョブを debug job として再実行します。Spark UI ボタンが表示され、これを選択すると Spark の Web UI が開きます。
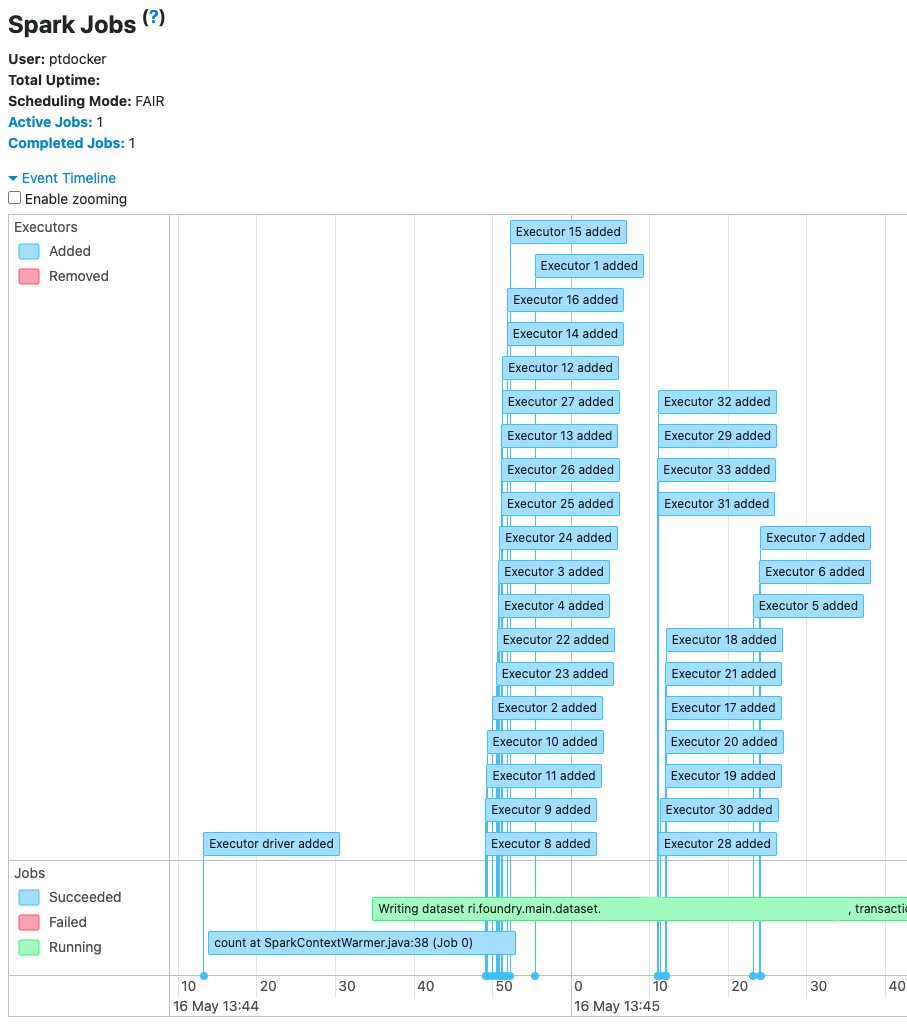
Spark のイベントは 1-2 分の遅延の後に Spark UI に表示されます。
Foundry での Spark UI の使用
Spark の Web UI は詳細が豊富ですが、Foundry に合わせた情報の提示方法ではありません。以下では、Foundry ジョブのための Spark の Web UI のナビゲートに関するアドバイスを提供します。
SQL 実行
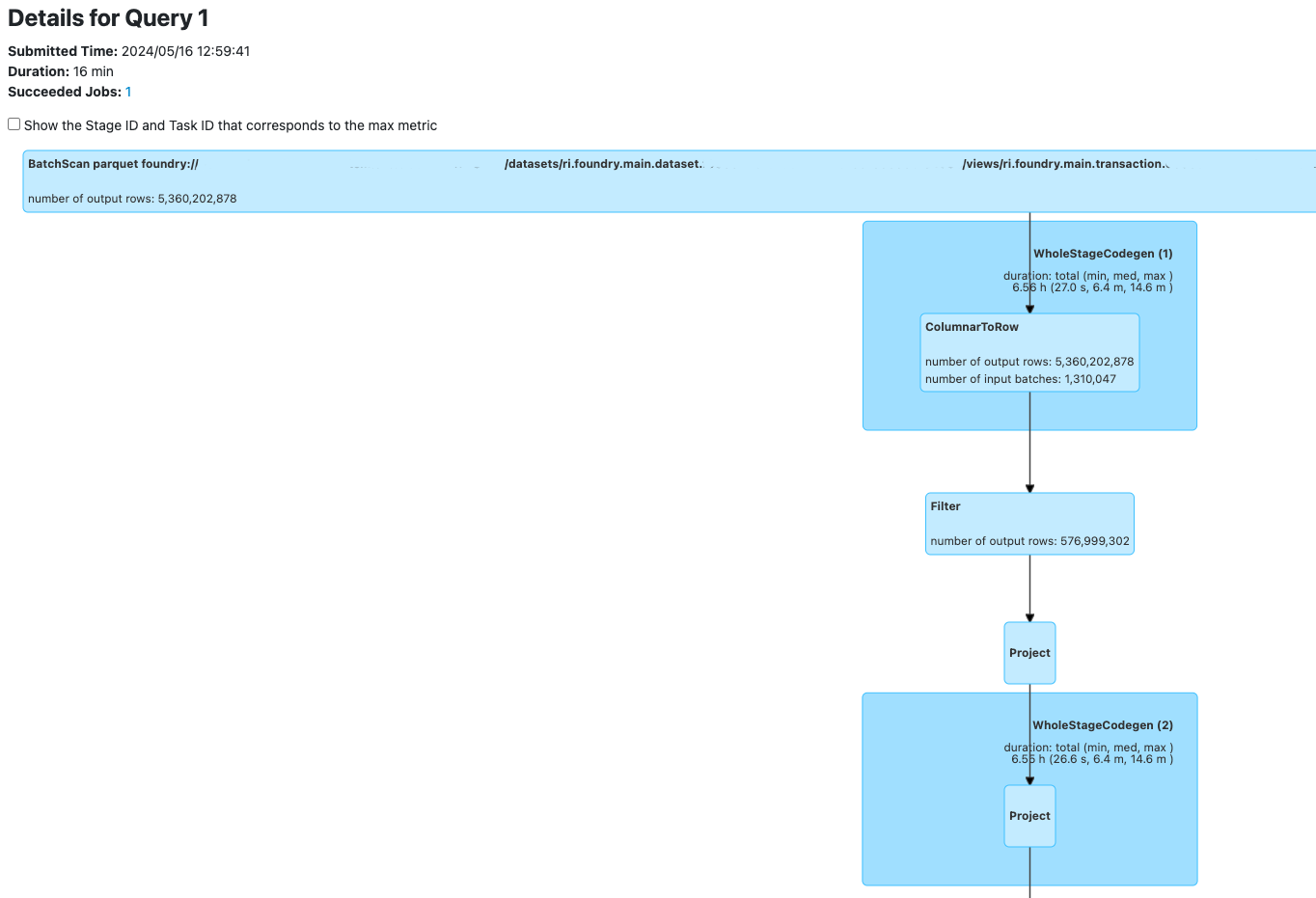
Spark は SQL クエリをメインクエリと 1 つ以上のサブクエリに分割できます。場合によっては、サブクエリがメインクエリよりも興味深いことがあります。これは Foundry での多くのデータセット書き込みに当てはまります。
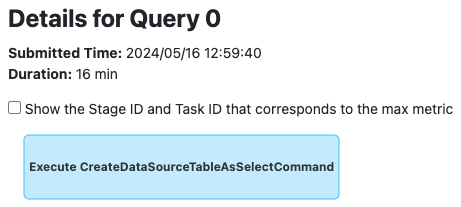
Spark UI で "Writing dataset ..." SQL 実行を表示する際、Sub Execution IDs の下にリンクされた書き込み用のクエリグラフを見つけることができます。

コンテキストウォーミング
Spark UI の Jobs タブでは、Transforms ジョブが最初に count ジョブをトリガーすることを示しています。この count ジョブの目的は、ランタイムが追加のセットアップ(依存関係のインストールを含む)を実行している間にエグゼキューターの割り当てを早期にリクエストすることです。これにより、Transform が実行準備が整ったときにエグゼキューターが利用可能である可能性が高まります。