注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Spark の概念
Spark 入門
Spark とは何ですか?
Spark は、Foundry 内で大規模なデータ変換を実行するために使用される分散コンピューティングシステムです。元々は UC バークレーの研究者チームによって作成され、2000年代後半に Apache Foundation に寄贈されました。Foundry では、大量のデータに対して SQL、Python、Java、および Mesa 変換(Mesa は独自の Java ベースの DSL)を実行するために、Spark を基礎的な計算レイヤとして使用することができます。
Spark はどのように動作しますか?
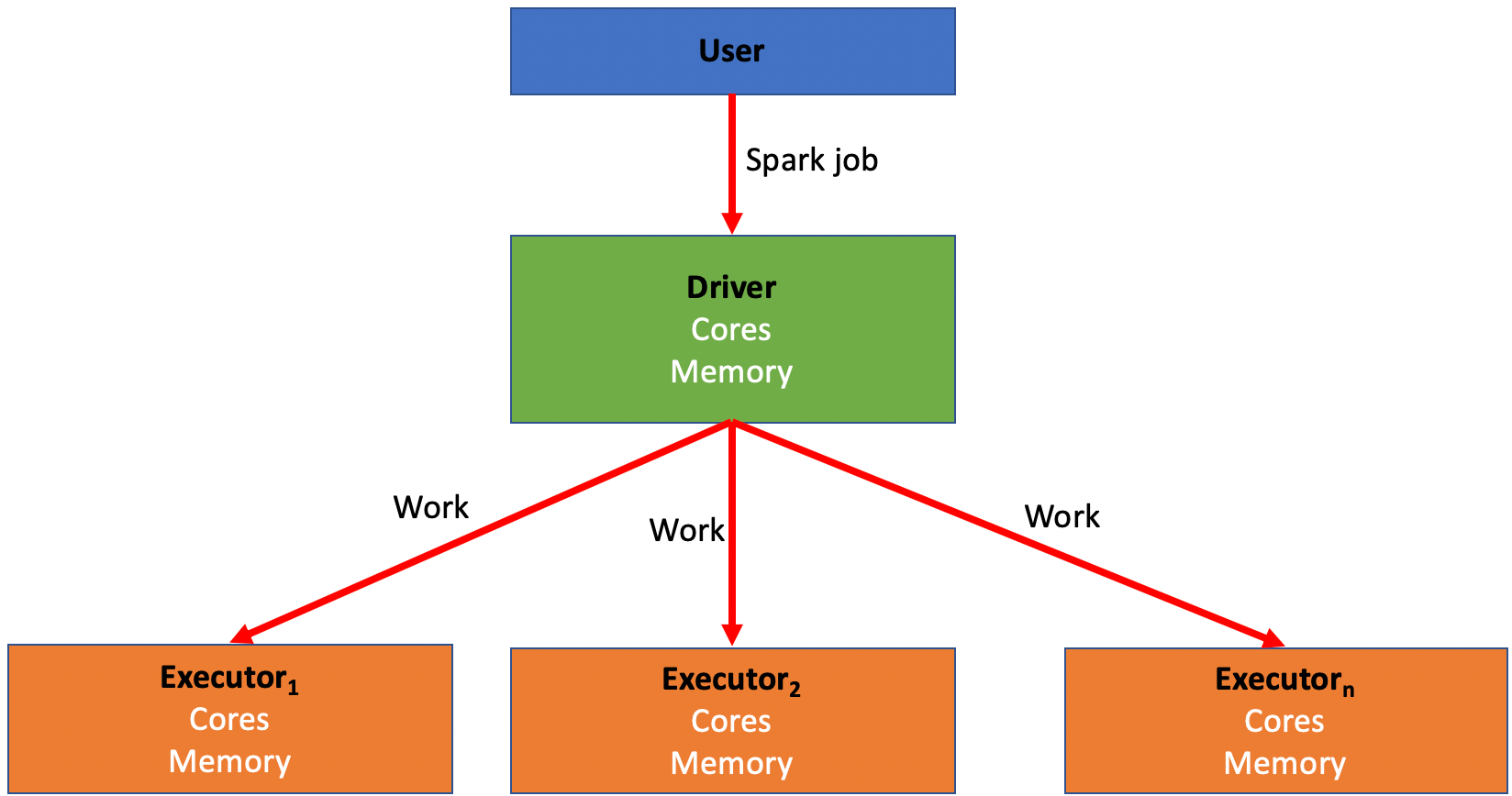
Spark は、データを処理するために多数のコンピュータにジョブを分散させることに依存しています。このプロセスにより、MapReduce と呼ばれる方法を使用して、ユーザーやプロジェクト間で同時にジョブを素早く実行することが可能になります。これらのコンピュータは、ドライバとエクゼキュータに分けられます。
- ドライバは Spark ジョブの「指揮者」のようなものです。ジョブの作業をエクゼキュータに分散する責任があります。
- エクゼキュータは Spark ジョブの「働き蜂」のようなものです。ドライバによって割り当てられたジョブの部分の計算を行う責任があります。この作業は「パーティション」と呼ばれる数に分割され、各エクゼキュータにはコードを実行するための一部のパーティションが与えられます。このタスクが完了すると、エクゼキュータはドライバに戻り、ジョブが完了するまで更なる作業を求めます。
- すべての Spark ジョブには、変換を実行するための最適な Spark プロファイルを作成するために操作できる変数が関連付けられています。
- すべての Spark ジョブでは、ジョブを素早く簡単に実行するという目標と、そのジョブを実行するためのコストとリソースとの間にバランスを取る必要があります。
- 大まかに言って、エクゼキュータとメモリの量を増やすことで実行時間が短縮される一方、コストも増加します。
- ジョブの特性に基づいて、ドライバとエクゼキュータの組み合わせや設定の一部は他のものよりも優れた性能を発揮します。(後で詳しく説明します)
- Spark プロファイルとは、Foundry が分散コンピューティングリソース(ドライバとエクゼキュータ)を適切な CPU コア数とメモリ量で設定するために使用する設定のことです。
- すべての Spark ジョブには 5つの設定可能な変数が関連付けられています:
- Driver Cores: Spark ドライバに割り当てる CPU コア数を制御します
- Driver Memory: Spark ドライバに割り当てるメモリ量を制御します
- JVM のメモリのみが制御されます。これには、Python ライブラリへの呼び出しなどの、外部の非 Spark タスクに必要な「ヒープ外」メモリは含まれません
- Executor Cores: 各 Spark エクゼキュータに割り当てられる CPU コア数を制御します。これにより、各エクゼキュータで同時に実行されるタスク数が制御されます
- Executor Memory: 各 Spark エクゼキュータに割り当てられるメモリ量を制御します
- このメモリは、エクゼキュータで実行されているすべてのタスク間で共有されます
- Number of Executors: ジョブを実行するために要求されるエクゼキュータの数を制御します
- すべての組み込み Spark プロファイルのリストは、Spark Profile Reference で見つけることができます。
Spark プロファイルのチューニング
- 変換を実行する際に問題が発生し、特定のジョブを有効にするためにカスタムの非デフォルト設定を作成するために Spark プロファイルを調整する必要がある場合があります。例えば:
- ジョブにはより多くのメモリが必要かもしれません。
- ジョブが使用ケースに必要なものよりも遅く実行されるかもしれません。
- ジョブが完全に失敗する原因となるエラーが発生するかもしれません。
- デフォルトでない Spark プロファイルを使用するためには、まず変換を含む Code リポジトリにインポートする必要があります。このプロセスは、Spark Profile Usage のドキュメンテーションで説明されています。
- インポートされたら、Spark プロファイルは Apply Transforms Profiles ドキュメンテーションの指導に従って特定の変換に割り当てることができます。
デフォルトから Spark プロファイルを変更するタイミング
- Spark プロファイルを編集する際の大まかなルールとして、一度に一つの変数だけを増やし、それも一度に一段階ずつ上げることをお勧めします。
- 例えば、まずエクゼキュータのメモリを調整し、
EXECUTOR_MEMORY_SMALLからEXECUTOR_MEMORY_MEDIUMに上げてから、他の何も調整せずにジョブを再度実行します。これにより、ジョブに過剰なリソースを割り当てることで不必要なコストが発生することを防ぎます。
- 例えば、まずエクゼキュータのメモリを調整し、
- バックエンドのデフォルト設定は常に特定の Spark プロファイルにマッピングされるわけではありませんが、通常は SMALL とラベル付けされた組み込みプロファイルによって近似されます。
- 非 Python 変換に適したデフォルト設定は
EXECUTOR_CORES_SMALL、EXECUTOR_MEMORY_SMALL、DRIVER_CORES_SMALL、DRIVER_MEMORY_SMALL、NUM_EXECUTORS_2 です。 - Python は JVM 外部で動作する Python ライブラリへの呼び出しを行うときに、より多くの非 JVM オーバーヘッドメモリが必要になる可能性があります。
- 非 Python 変換に適したデフォルト設定は
- Spark ジョブで問題が発生している場合、最初のステップはコードの最適化です。
- 可能な限り最適化したにもかかわらずまだ問題がある場合は、特定の推奨事項については以下を読み進めてください。
- ジョブが成功するものの、使用ケースに必要な速度よりも遅く実行されている場合:
- エクゼキュータの数を増やすことを試してみてください - エクゼキュータの数を増やすことで、並行して実行できるタスクの数が増え、したがってパフォーマンスが向上します(提供されたジョブが十分に並列である場合)。ただし、これはより多くのリソースを使用するためコストも増加します。
- 指定のビルドの Builds アプリケーションページを見ると、エクゼキュータの数を増やすことでジョブの速度を向上させるのに役立つチャートが表示されます。タスクの並行性がエクゼキュータの数に近づかない場合、エクゼキュータの数を増やすことはおそらく実行時間の改善には役立たないでしょう。

- エクゼキュータの数を2倍にしても実行時間が 1/3 以上短縮されない場合、おそらくコードが非効率的である(例えば、カタログから多くを読み込んだり、カタログに多くを書き込んだりする)ことを意味します。
- 6分間のジョブを生成する変換のエクゼキュータの数を2倍にすると、ジョブは4分以内に実行されるはずです。
- エクゼキュータの数を半分にすると、ジョブの遅延が50%未満になる(例えば、4分から6分になる)場合、ランタイムが重要でない限り、コストを節約するためにエクゼキュータの数を下げるべきです。
- 大きなプロファイル(例えば 128 以上のエクゼキュータ)には制限が課せられ、重要なリソースを使用できるのは承認された使用ケースのみとすることができます。制限に達して更に上に行く必要がある場合は、Palantir の担当者に連絡してください。
- エクゼキュータは、スタートアップ時にドライバに約 10 分ごとに累積する傾向があります。これは、高いエクゼキュータ数を持つ短いジョブは、恐らくシステム内のスラッシングを減らすために、低いエクゼキュータ数を使用するべきであることを意味します。例えば、10分未満で終了する64エクゼキュータのジョブは、おそらく全ての計算リソースを取得する頃にはほぼ終了しているため、32エクゼキュータに下げるべきです。
- エクゼキュータの数を増やすことを試してみてください - エクゼキュータの数を増やすことで、並行して実行できるタスクの数が増え、したがってパフォーマンスが向上します(提供されたジョブが十分に並列である場合)。ただし、これはより多くのリソースを使用するためコストも増加します。
- ジョブが失敗し、OOM(メモリ不足)エラーや「Shuffle stage failed」エラーが発生し、それがコードロジックに基づく失敗原因と関連していない場合:
- エクゼキュータのメモリを SMALL から MEDIUM に増やすことを試してみてください。これは大量のデータを処理している場合に役立つはずです。
- MEDIUM から LARGE に調整する必要があると思われる場合は、専門家に助けを求めてください。可能ならば、troubleshooting guide に記載されているように、変換を単純化することを検討してください。
- エクゼキュータのメモリを SMALL から MEDIUM に増やすことを試してみてください。これは大量のデータを処理している場合に役立つはずです。
- ドライバに大量のデータを回収したり、大規模なブロードキャストジョインを実行したりしている場合:
- ドライバのメモリを増やすことを試してみてください。
- 「Spark モジュールが応答しなくなりました」というようなエラーが発生し、入力データセットに多数のファイルがある場合:
- まずドライバのメモリを増やすことを試してみてください。
- ドライバのメモリを増やした後でもエラーが続く場合は、ドライバのコア数を 2 に増やしてみてください。
- 多くのファイルを読み込む変換を持ち、GC(ガベージコレクション)の問題に遭遇する場合:
- ドライバのコア数を 2 に増やすことを試してみてください。
推奨されるベストプラクティス
管理者向け
- ユースケースが終了したら、このユースケースのために作成されたすべてのカスタムプロファイルを削除します。
- これにより clutter が減り、混乱を招くカスタムプロファイルが多すぎる状況を避けることができます。
- リソースを大量に消費するプロファイルが、管理者が明示的に許可を与えた後のみアクセス可能となるように、許可を設定します。
- 例えば、
NUM_EXECUTORS_32とEXECUTOR_MEMORY_LARGE(およびそれ以上)は、リクエストとそのリクエストの承認があった場合にのみ利用可能であるべきです。 EXECUTOR_CORES_SMALL以外のすべてのエクゼキュータコアの値は厳重に制御されるべきです(これはコンピューティングパワーを増加させるステルスな方法であり、ほとんどすべてのケースでユーザーを NUM_EXECUTORS プロファイルに誘導することを好みます)。
- 例えば、
Spark プロファイルの調整について
- デフォルト(つまり、なし)のプロファイルを使用しようと努力してください。
- これにより、コストと clutter を削減することができます。
- デフォルトのプロファイルを使用できない場合でも、組み込みのプロファイルを使用しようと努力してください。
- 新しいプロファイル設定を設定するときは、自分の名前かユースケースの名前で保存してください。
- これにより、組織化が改善され、他のユーザーやプロジェクトが自分の知らずにこのプロファイルを使用することがないことが保証されます。
- そうしないと、どのプロファイルがどの使用目的のために設定されたのかわからない状態で、多すぎるプロファイルのリストを取得することになります。
- メモリを増やすとき、8:1 のリソース(
EXECUTOR_CORES_SMALLとEXECUTOR_MEMORY_MEDIUMの組み合わせによって示されます)を超えるものは、管理者の承認を得るべきです。EXECUTOR_CORES_EXTRA_SMALLとEXECUTOR_MEMORY_LARGEをブロックします。ユーザーがこれらを要求している場合、それは通常、最適化が不十分であるか、または重要なワークフローの兆候です。 - プロファイルは分離可能であるべきです。各プロファイルは、一つの Spark 変数(または一つの論理的な Spark 変数の組み合わせ)のみを影響します。
- 例えば、新しいプロファイルを作成するときは、エクゼキュータの数だけを変更し、それを試してみてから、エクゼキュータのメモリやドライバのメモリなどの他の変数を変更することなく、そのままにします。
- 同じ Spark モジュール内で多数の Spark ジョブが同時に実行されている特殊なケースを除き、ドライバコアのデフォルト設定はオーバーライドされるべきではありません。
- デフォルトのエクゼキュータコア設定は、まれにしかオーバーライドされるべきではありません。
- 15分未満で実行されるジョブは、64エクゼキュータを使用すべきではありません。
- この多くのエクゼキュータは、その時間のほとんどを単に増加させるために費やします。
- カスタムプロファイルを作成して実行するときは、実際のパフォーマンスを Spark details で後からチェックしてください。
- Spark details では、ジョブがどのくらい速く実行され、並行ジョブの詳細を追跡します。