注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
パイプラインの故障をデバッグする
パイプラインの問題を迅速にデバッグし、解決する能力は、パイプライン保守作業の中核的な部分です。これにより、重要な組織のワークフローを供給する本番パイプラインが信頼性と意味を保つことが保証されます。
このページでは、パイプライン保守者としてオンコールローテーション中にヘルスチェックの失敗の通知を受けた際に、標準的な運用手順 (SOP) の基盤として使用できるフレームワークを提供します。
必要な知識
このページでは、あなたが Foundry の様々なツールとワークフローに精通していることを前提としています。関連するセクションにリンクが提供されます:
また、ユーザーのパイプライン保守チームがインシデントログやパイプラインの定常的な問題に関する他のドキュメンテーションを記録していることを前提としています。これはベストプラクティスであり、現在そのようなドキュメントが存在しない場合は実施すべきです。
デバッグフレームワークの概要
常に以下の三つの質問から始めてください、その順序で:
- 緩和: この問題をできるだけ早く緩和できますか?一部の例は以下の通りです:
- スケジュールを再構築する。データセットや失敗したジョブを1つだけ再構築するのではなく、スケジュールを再構築することをお勧めします。これは、スケジュールの履歴に表示されるためです。スケジュール履歴を使用すると、個々のデータセットの履歴ではなく、パイプラインの履歴を追跡できます。
- キューが多すぎる場合は、重複するスケジュールや集中的なスケジュールを探してキャンセルします。
- 手動のアップロードが壊れている場合は、既知の安定したバージョンにトランザクションを戻します。
- 分類: 問題のカテゴリーは何ですか?
- 問題を分類する理由は、根本原因の特定を支援し、解決策が他のチームの関与を必要とするかどうかを判断するためです。
- 問題のカテゴリーとその特定方法についての詳細は、以下 を参照してください。
- 幅広い影響: この問題はプラットフォームの他の部分に影響を及ぼしている可能性がありますか?
パイプラインのドキュメンテーションを読んでください!この問題は以前に解決されているかもしれません。または、緩和中に行うべきではないことについての警告があるかもしれません。たとえば、一部のビルドは非常に費用がかかり、ピーク使用時間中に環境のパフォーマンスに影響を与える可能性があります。このような詳細は、ユーザーの全チームに対して十分に文書化されるべきです。
問題カテゴリーの分類
問題の緩和を試みた後、パイプライン保守者としては、根本原因を理解し、対策を講じるためにさらに深く掘り下げる必要があります。問題を分類するのがデバッグ中に役立つ理由は、それが根本原因を特定し、何よりも重要なことは、ユーザーが問題を修正できるか、それとも他のチームに連絡する必要があるかを迅速に特定するのに役立つからです。
問題のカテゴリーは3つあります:
- 上流の問題: 他の人が管理するインフラストラクチャまたは作成物に関連する問題
- Foundry の外部: 上流のデータソースに関する問題
- Foundry 内部: 問題のあるパイプラインの上流のデータセット/プロジェクトによって引き起こされる問題
- プラットフォームの問題: Foundry Platform のサービスが期待通りに動作していないために引き起こされる問題。
- 変更: あなたが監視するパイプラインの範囲内で変更されたもの。これは最も一般的な問題のカテゴリーであり、ユーザーの変更によく引き起こされます。いくつかの例は以下の通りです:
- コードの変更
- スケジュールの変更
- パイプライン内のデータサイズの増加
問題のカテゴリー別の問題解決手順:
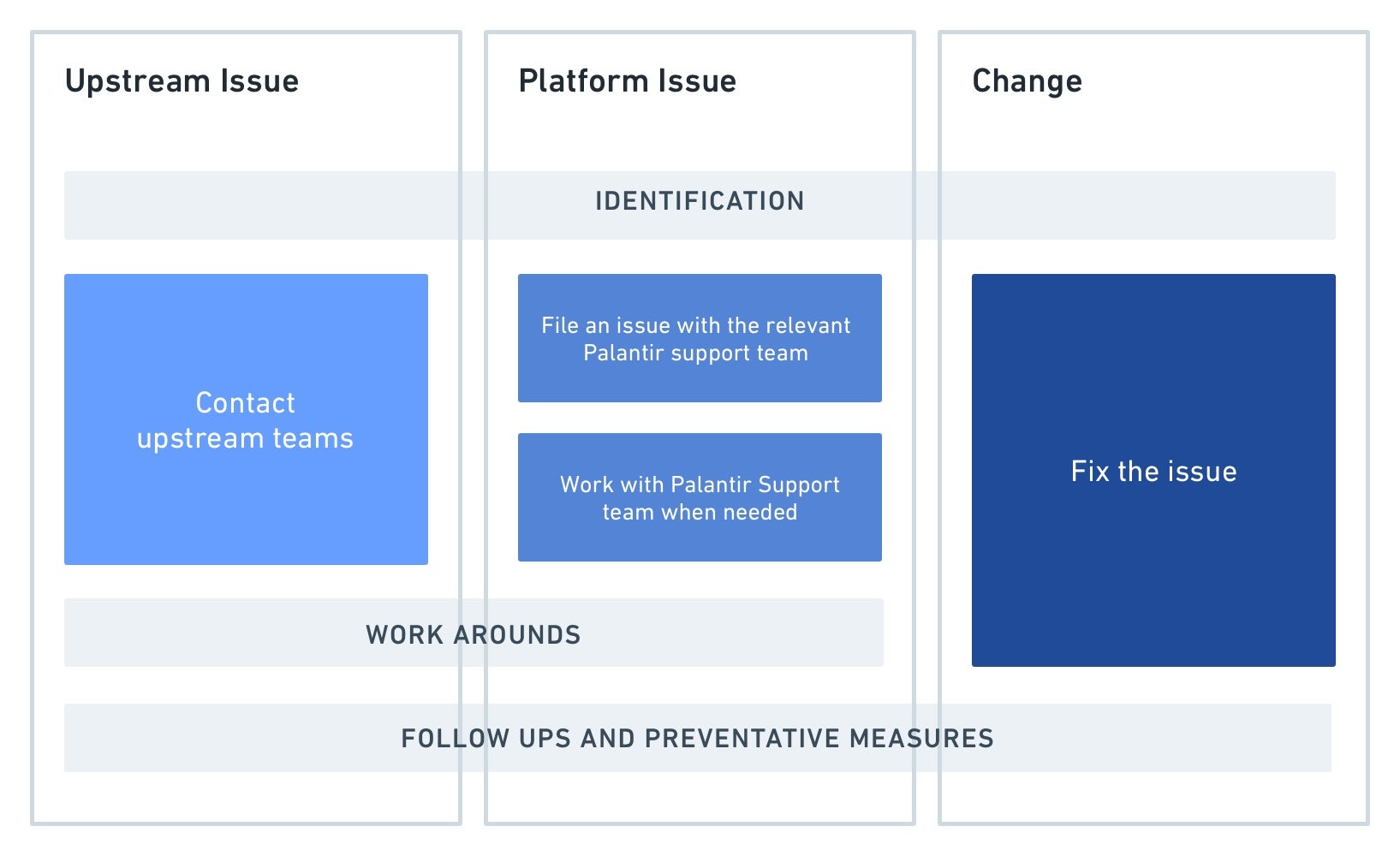
詳細には、上記で強調表示されている手順は以下の通りです:
-
特定: 上記の手順を経て、何が壊れているかを非常に具体的に特定することが重要です。以下のような質問に答えます:
- 問題はいつ始まったのですか?
- パイプラインのどのステップで何かが失敗しましたか?
- どのヘルスチェックが失敗していますか?
- パイプラインの何かが変更されてこの壊れた状態を引き起こしましたか?
これにより、上流の問題とプラットフォームの問題が必要となる場合に他のチームと効果的にコミュニケーションを取ることができ、解決時間を短縮できます。また、プラットフォームでのデバッグスキルも向上します。
-
アクション:
- 上流の問題: パイプラインの上流からの遅延、欠落、または不正確なデータによって問題が確かに引き起こされていることを確認したら、上流のデータを管理するチームに連絡します。
- Tip: モニタリングを始める前に、上流のチームの連絡先をドキュメント化しておくと便利です。これにより、オンコールの人が彼らに連絡するのが容易になります。
- プラットフォームの問題: Foundry から予期しない動作を確認し、パイプライン内のユーザーの変更を排除した場合は、Palantir の担当者に連絡してください。問題に関するできるだけ具体的な情報を提供してください。観察された変更の詳細を含めます。これらを見つける方法についてのヒントは、以下 を参照してください。
- 変更: 監視対象のパイプライン内で何かが変更されたことを特定した後、通常はそれを修正するためのアクションを取ることができます。場合によっては、より多くの情報を得るために変更を行った人に連絡する必要があるかもしれません。パイプライン内で何かが変更されたかを特定する方法については、次のセクションを参照してください。
- 上流の問題: パイプラインの上流からの遅延、欠落、または不正確なデータによって問題が確かに引き起こされていることを確認したら、上流のデータを管理するチームに連絡します。
-
[Optional] 下流ユーザーへの通信: 上記の図には言及されていないステップは、問題が分類され、さらに根本原因が特定された場合、パイプラインの下流の消費者に通知するのが適切であるかもしれません。これは、問題の影響、範囲、期間、およびパイプラインのユースケースによります。
-
回避策: 他のチームやユーザーからの修正が時間を要する場合、パイプラインの健全な部分が下流の消費者に対して継続して実行されることを保証するために、中期的な回避策を実装すると便利かもしれません。具体的な一時的な修正は、問題とユーザーのニーズによります。例えば:
- 壊れたデータセットやパイプラインのブランチをスケジュールから取り除くことで、問題を隔離します。
- これが問題の根本原因である場合、別のPythonライブラリのバージョンを固定します。これは meta.yml で、ライブラリ名の隣に明示的なバージョン番号を指定することで行うことができます。
パイプライン内の変更を特定する
パイプライン保守者が直面する最も一般的な問題は、監視対象のパイプライン内の何かが変更された結果として生じます。また、パイプライン保守者として、あなたは最も制御でき、他のチームに頼ることなく問題を直接修正できるカテゴリーでもあります。
詳細には、以下のステップを踏む必要があります:
-
パイプライン内で問題が発生している正確な場所をできるだけ特定します。たとえば、スケジュール、データセット、トランザクション、コードの変更などを特定しようとします。
-
健全な前回の実行と現在の壊れた状態を比較して、何が変更されたのかを特定します。 念頭に質問のチェックリストを持つと便利です。以下に、質問の例と、答えを見つけるのに役立つ可能性のあるツールの例を示します:
- 通常より遅い?これはキューイングによるものか、それともビルドが実際に計算に時間がかかっているのか?
- ファイル/データサイズの変更?
- コードの変更?スキーマの変更?
- スケジュールの変更?
- 進行中のプラットフォームのインシデント?
ツール
上記の質問の一部に答えるために Foundry で使用されるツールに不慣れな場合、以下のリストは、調査中に最も一般的に使用されるパターンの例を提供します。このリストはすべての可能性を網羅するものではなく、ガイドのスタート地点として機能します:
私のジョブ/ビルドは通常より遅いですか?
-
特定のデータセットのジョブを比較するための Builds application。Build の概要の右上にある進行状況の詳細トグルを使用すると、ビルドの進行状況をキューイング時間対計算時間で確認できます。
- 失敗したジョブがスケジュールの一部としてビルドされた場合、ビルドの詳細ページの左下にスケジュールカードが表示されます。以前のビルドを表すドットをクリックすると、スケジュールの以前の実行を開くことができます。
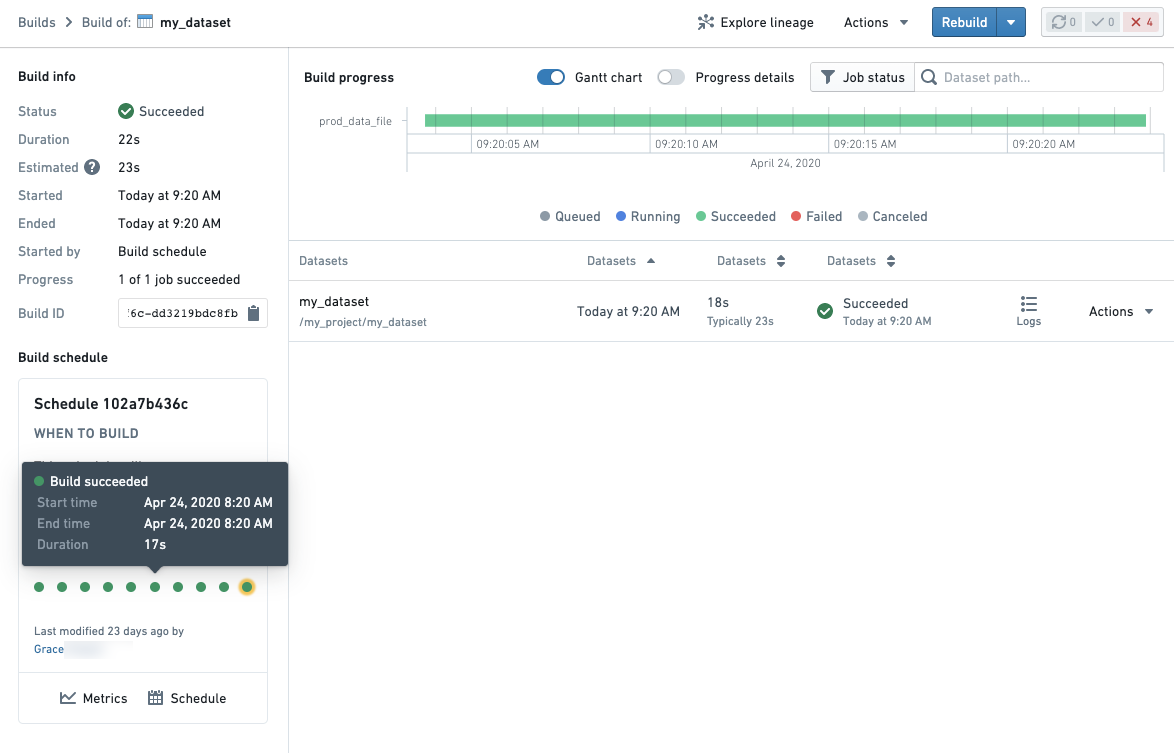
- 失敗したジョブがスケジュールの一部としてビルドされた場合、ビルドの詳細ページの左下にスケジュールカードが表示されます。以前のビルドを表すドットをクリックすると、スケジュールの以前の実行を開くことができます。
-
Schedule metrics これにより、スケジュールの歴史的な実行を確認し、実行を比較するための指標とグラフを表示できます
私のデータセットのサイズに変更はありますか?私のトランスフォームはより多くのデータで実行されていますか?
-
Dataset Preview:Foundry データセットの履歴と比較タブは、データセットの履歴の概要を提供し、データセットの以前のトランザクションと比較して何が変更されたのかの概要を取得する能力を提供します。

-
Contour は、summary board を使用して行数を比較するための歴史的なビューへのアクセスを提供します。また、特定の列を含むパイプライン全体のデータセットを追跡するために特に便利な、サイドパネルの Properties & Histogram を使用して、データが追加/作成された日付を表す列がある場合、行数を日付に対して比較するチャートを作成できます。
-
Spark details:任意のジョブで Spark details ボタンをクリックすると(以下参照)、パイプライン内にデータが増えているかを示す情報を確認できます。たとえば、
count of tasksメトリックです。

パイプラインのコードが変更されましたか?
- Dataset Preview の Compare タブを使用すると、データセットの歴史的なトランザクションを比較する際に、直接的なトランスフォームファイル上のコードの変更を確認できます。
- Code Repositories 内の Code tab の File changes(コミット履歴)ヘルパーを使用してコードの変更を確認できます。
- Data Lineage ツールを使用すると、パイプライン全体のスキーマの概要をすばやく取得できます。特に、特定の列を含むパイプライン全体のデータセットを追跡するために便利なのが、サイドパネルの Properties & Histogram です。
コードの変更は、Python や Java など、これをサポートする言語を使用してトランスフォームでインポートされたライブラリで発生する場合があります。トランスフォームに変更が見られない場合は、ライブラリ関数のロジックが変更されたかどうかを確認することを検討してください。
スケジュールが変更されましたか?
- プラットフォームの様々な部分にあるスケジュールカードを使用すると、スケジュールが最後に変更された時期を確認できます。
- スケジュールの指標ページの schedule versions tab を使用すると、スケジュール設定に対して具体的にどのような変更が行われたかを特定することができます。
プラットフォームの問題を特定する
他のジョブ、ビルド、または関連するプラットフォームコンポーネントで同様の症状をチェックすると、問題が何であるかに基づいて症状から問題を特定できない場合に有用な調査経路となることがあります。
特に、以下の質問に答えを探す必要があります:
- それは 再現性 がありますか?
- この問題は一貫して発生しますか?
- パターンに従っていますか?たとえば、それは毎週月曜日の午前9時に週末の後に失敗しますか?
- その 範囲 は何ですか?
- ジョブが遅いか失敗している場合、他のトランスフォームジョブでもこれを見ていますか?それとも他の Python ジョブのみですか?
Builds application を使用して、プラットフォーム全体のジョブ履歴をフィルタリングすることで、上記の質問に答えるのに役立ちます。
パイプラインの問題を迅速にデバッグし、解決する能力は、パイプライン保守者の作業の中心的な部分です。これにより、重要な組織のワークフローを供給する本番パイプラインが信頼性と意味を保つことが保証されます。このページで概説されたガイドラインに従っていても、手元の問題を特定できない場合は、Palantir の担当者に連絡してください。