注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Transforms Excel Parser
Foundry では、Microsoft Excel ファイルを含むスキーマレスデータセットから表形式データを抽出する方法が多数あります。たとえば、Pipeline Builder、オープンソースライブラリを使用するPythonファイルベースのトランスフォーム、およびApache POIなどのオープンソースライブラリを使用するJavaファイルベースのトランスフォームがあります。
これらのオプションに加え、Palantir は transforms-excel-parser というライブラリを提供しており、Apache POI を利用した合理的なデフォルト動作をラッピングし、最小限の設定でtransforms-javaリポジトリで簡単に使用できるようにしています。
このライブラリが提供する便利な機能と動作のいくつかの例は以下の通りです。
- 部分的に重複しているが一貫性のないスキーマを持つファイルを含む入力データセットを処理し、テーブルヘッダーからスキーマを推測する。
- 複数のシート(または同じシート内の異なるテーブル)からデータを抽出し、ファイルをメモリに 1 度だけ読み込んで複数の出力データセットに書き込む。
- 非表形式の「フォームスタイル」シート(データがラベルの上、下、または隣に位置する)からフィールドの抽出を定義するための流暢な API を提供する。
- 不適切な「ジップボム」検出や「最大バイト配列サイズ」を超えるための失敗など、一般的な Apache POI の問題を解決する適切なグローバルパラメーターを設定する。
ParseResultクラスのerrorDataframe()メソッドを使用して、ジョブを失敗させるためにランタイムでチェックするか、別の出力に書き込んで非同期にチェックするかのいずれかの方法で、fail-fast と fail-safe の両方の動作をサポートする。- インクリメンタルパイプラインの一般的なエッジケース(インクリメンタルバッチ間の一貫性のないスキーマなど)を処理するための適切な構成オプションとユーティリティ機能を提供する。
設定
1. transforms-excel-parser-bundle の利用可能性を確認し、バックリポジトリとして追加
リポジトリの Maven ライブラリパネルで transforms-excel-parser を検索してください。

利用可能な最新バージョンを選択します。
これにより、追加のバックリポジトリとして transforms-excel-parser-bundle をインポートするためのダイアログが表示されます。「ライブラリを追加」を選択します。
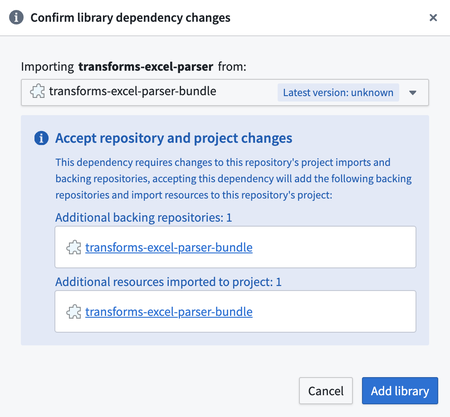
eddie-spark-module-bundle や ri.eddie.artifacts.repository.bundles が transforms-excel-parser-bundle 以外にもドロップダウンオプションとして表示されることがあります。
eddie という名前が付いたバックリポジトリはPipeline Builderアプリケーション専用のものであり、それらを使用すると将来的に問題が発生する可能性があるため、適切な選択ではありません。
transforms-excel-parser-bundle がオプションとして表示されない場合は、Palantir の担当者にインストールを依頼してください。
2. build.gradle に依存関係を追加
最新バージョンを transforms-java/build.gradle ファイルに以下のように追加します。
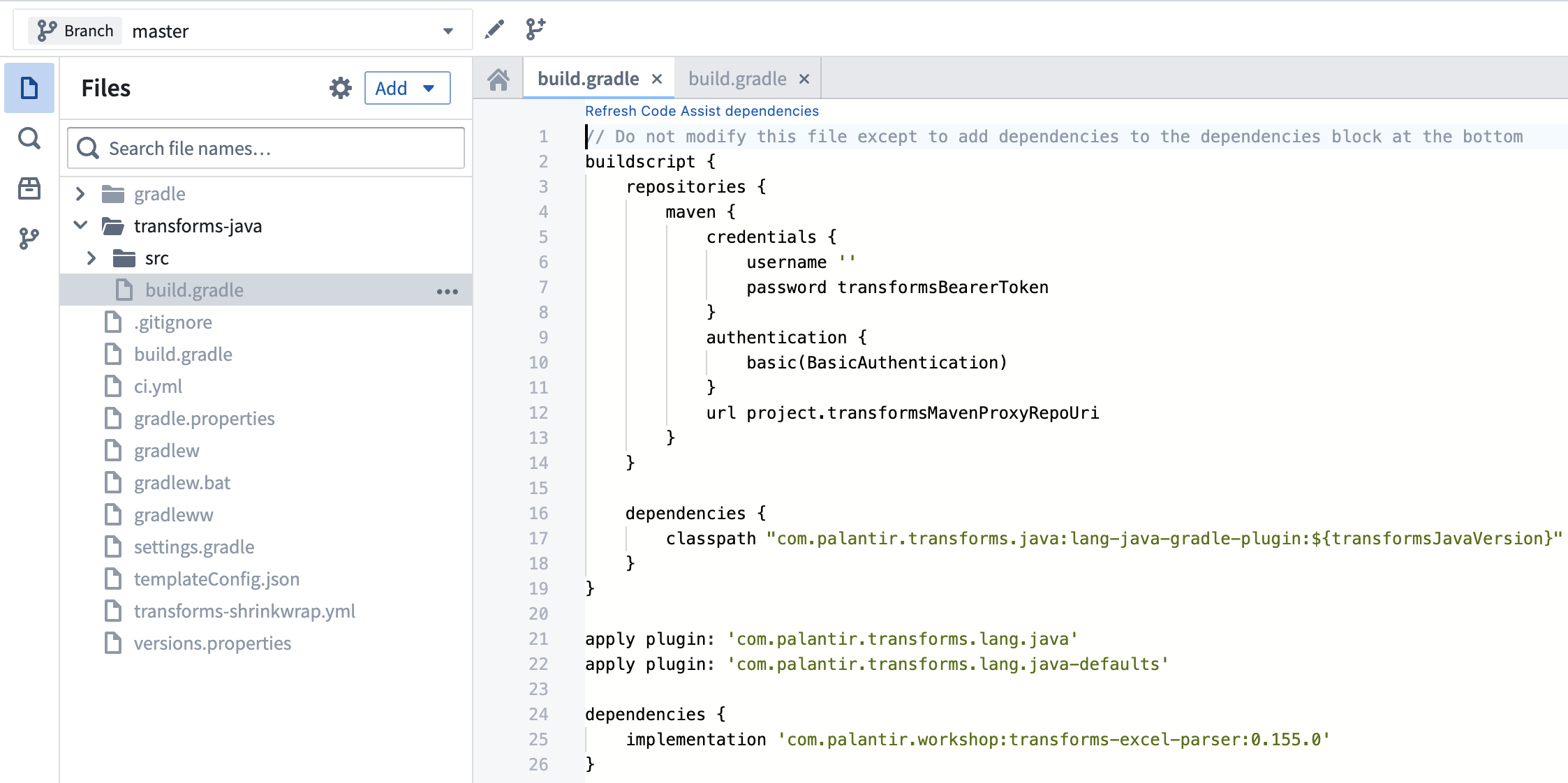
transforms-java/build.gradle は隠しファイルなので、表示するには Show hidden files 設定を切り替える必要があります。
API ドキュメント
詳細な API ドキュメントについては、javadoc アーカイブをダウンロードし、解凍して含まれている HTML ファイルをウェブブラウザーで表示してください。
javadoc を読む際の最良の出発点は com/palantir/transforms/excel/package-summary.html です。
既知の問題と注意点
サポートされているファイルタイプ
現在サポートされているファイル形式は次のとおりです。
- xls
- xlt
- xltm
- xltx
- xlsx
- xlsm
xlsb ファイルは現在サポートされていないことに注意してください。
Code Assist プレビューの不安定性
Code Assist プレビューを実行する際、ワークスペースの起動後、最初の実行が成功し、2 回目の実行が以下に似たエラーで失敗する問題が発生することがあります。
java.lang.ClassCastException: class com.palantir.transforms.excel.KeyedParsedRecord cannot be cast to class com.palantir.transforms.excel.KeyedParsedRecord (com.palantir.transforms.excel.KeyedParsedRecord is in unnamed module of loader java.net.URLClassLoader @5a5d825a; com.palantir.transforms.excel.KeyedParsedRecord is in unnamed module of loader java.net.URLClassLoader @53dafc50)
// クラスキャスト例外: com.palantir.transforms.excel.KeyedParsedRecord クラスを com.palantir.transforms.excel.KeyedParsedRecord クラスにキャストすることができない
// (com.palantir.transforms.excel.KeyedParsedRecord は java.net.URLClassLoader @5a5d825a の無名モジュールにあり、com.palantir.transforms.excel.KeyedParsedRecord は java.net.URLClassLoader @53dafc50 の無名モジュールにある)
// このエラーは、同じ名前のクラスが異なるクラスローダーによってロードされた場合に発生します。
// 解決方法として、同じクラスローダーを使用するか、クラスローダーの設定を見直すことが必要です。
この問題は Code Assist プレビュー機能に特有であり、ビルド時に問題を引き起こすことはありません。 ブラウザーウィンドウを更新すると、Code Assist ワークスペースの完全な再構築を行わずに再度プレビューできるはずです。
メモリ要件
Apache POI ライブラリは高いメモリ消費量で知られており、比較的小さな Excel ファイルでさえ開くとかなりのメモリフットプリントを引き起こすことがあります。その結果、デフォルトのトランスフォーム Spark プロファイル設定では、メモリ内オブジェクトを収容するためのタスクごとのメモリが不足することがよくあります。メモリが不足すると、次のような問題が発生する可能性があります。
- トランスフォームジョブが
Spark module '{module_rid}' died while job '{job_rid}' was using itのようなエラーで失敗する。 - トランスフォームジョブが長時間停止し、成功も失敗もしない。
ジョブが停止しているかどうかを判断するための大まかなガイドラインは、単一ファイルの処理に 10 分以上かかるかどうかです。十分なメモリがあれば、非常に大きな Excel ファイルの処理に約 8 分かかることがあります。1 つの Spark タスクが複数の入力ファイルを処理できるため、このルールを適用するのは必ずしも簡単ではありません。
メモリ不足の症状がジョブの失敗であれ、ジョブの停止であれ、タスクごとにさらに多くのメモリを提供する spark プロファイル の組み合わせ、たとえば EXECUTOR_MEMORY_LARGE や EXECUTOR_CORES_EXTRA_SMALL に切り替えることで問題を解決することをお勧めします。
使用例
単純な表形式の Excel ファイル
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49package myproject.datasets; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.table.SimpleHeaderExtractor; import com.palantir.transforms.excel.table.TableParser; import com.palantir.transforms.lang.java.api.Compute; import com.palantir.transforms.lang.java.api.FoundryInput; import com.palantir.transforms.lang.java.api.FoundryOutput; import com.palantir.transforms.lang.java.api.Input; import com.palantir.transforms.lang.java.api.Output; import java.util.Optional; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; public final class SimpleTabularExcel { @Compute public void myComputeFunction( @Input("<input_dataset_rid>") FoundryInput myInput, @Output("<output_dataset_rid>") FoundryOutput myOutput, @Output("<error_output_dataset_rid>") FoundryOutput errorOutput ) { // SimpleHeaderExtractorを適切に設定したTableParserを作成 // この例では、ファイルのヘッダーは2行目にあります。 // ヘッダーが1行目にある場合、rowsToSkipを指定する必要はありません。 // デフォルト値は0ですので、その場合はTableParser.builder().build()を実行するだけです。 Parser tableParser = TableParser.builder() .headerExtractor( SimpleHeaderExtractor.builder().rowsToSkip(1).build()) .build(); // TableParserを使用してTransformsExcelParserを作成 TransformsExcelParser transformsParser = TransformsExcelParser.of(tableParser); // 入力を解析 ParseResult result = transformsParser.parse(myInput.asFiles().getFileSystem().filesAsDataset()); // 解析されたデータを取得。入力に行がない場合やエラーが発生した場合は空になる可能性があります。 Optional<Dataset<Row>> maybeDf = result.singleResult(); // 解析データが空でない場合、それを出力データセットに書き込む maybeDf.ifPresent(df -> myOutput.getDataFrameWriter(df).write()); // エラー情報をエラー出力に書き込む errorOutput.getDataFrameWriter(result.errorDataframe()).write(); }
複雑な複数行ヘッダーを持つ表形式のExcelファイル
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49package myproject.datasets; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.table.MultilayerMergedHeaderExtractor; import com.palantir.transforms.excel.table.TableParser; import com.palantir.transforms.lang.java.api.Compute; import com.palantir.transforms.lang.java.api.FoundryInput; import com.palantir.transforms.lang.java.api.FoundryOutput; import com.palantir.transforms.lang.java.api.Input; import com.palantir.transforms.lang.java.api.Output; import java.util.Optional; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; public final class ComplexHeaderExcel { @Compute public void myComputeFunction( @Input("<input_dataset_rid>") FoundryInput myInput, @Output("<output_dataset_rid>") FoundryOutput myOutput, @Output("<error_output_dataset_rid>") FoundryOutput errorOutput ) { // MultilayerMergedHeaderExtractorを使用してTableParserを作成 Parser tableParser = TableParser.builder() .headerExtractor(MultilayerMergedHeaderExtractor.builder() .topLeftCellName("A1") .bottomRightCellName("D2") .build()) .build(); // TableParserを使用してTransformsExcelParserを作成 TransformsExcelParser transformsParser = TransformsExcelParser.of(tableParser); // 入力をパース ParseResult result = transformsParser.parse(myInput.asFiles().getFileSystem().filesAsDataset()); // パース結果からデータを取得。入力に行がない場合やエラーが発生した場合は空になる可能性がある Optional<Dataset<Row>> maybeDf = result.singleResult(); // パースされたデータが空でない場合、出力データセットに書き込み maybeDf.ifPresent(df -> myOutput.getDataFrameWriter(df).write()); // エラー情報をエラー出力に書き込み errorOutput.getDataFrameWriter(result.errorDataframe()).write(); } }
フォームを含む Excel ファイル
この例では複数の FormParser インスタンスを登録していますが、FormParser インスタンスと TableParser インスタンスの両方を登録することも可能です。これは、表形式の要素を含む複雑なフォーム(同じシート内またはシートをまたいで)に共通するパターンです。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72package myproject.datasets; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.form.FieldSpec; import com.palantir.transforms.excel.form.FormParser; import com.palantir.transforms.excel.form.Location; import com.palantir.transforms.excel.form.cellvalue.AdjacentCellAssertion; import com.palantir.transforms.excel.form.cellvalue.CellValue; import com.palantir.transforms.excel.functions.RegexSubstringMatchingSheetSelector; import com.palantir.transforms.lang.java.api.Compute; import com.palantir.transforms.lang.java.api.FoundryInput; import com.palantir.transforms.lang.java.api.FoundryOutput; import com.palantir.transforms.lang.java.api.Input; import com.palantir.transforms.lang.java.api.Output; public final class FormStyleExcel { private static final String FORM_A_KEY = "FORM_A"; private static final String FORM_B_KEY = "FORM_B"; @Compute public void myComputeFunction( @Input("<input_dataset_rid") FoundryInput myInput, @Output("<form_a_output_dataset_rid>") FoundryOutput formAOutput, @Output("<form_b_output_dataset_rid>") FoundryOutput formBOutput, @Output("<error_output_dataset_rid>") FoundryOutput errorOutput) { // Form A パーサーの設定 Parser formAParser = FormParser.builder() .sheetSelector(new RegexSubstringMatchingSheetSelector("Form_A")) .addFieldSpecs(createFieldSpec("form_a_field_1", "B1")) .addFieldSpecs(createFieldSpec("form_a_field_2", "B2")) .build(); // Form B パーサーの設定 Parser formBParser = FormParser.builder() .sheetSelector(new RegexSubstringMatchingSheetSelector("Form_B")) .sheetSelector(new RegexSubstringMatchingSheetSelector("Form_B")) .addFieldSpecs(createFieldSpec("form_b_field_1", "B1")) .addFieldSpecs(createFieldSpec("form_b_field_2", "B2")) .build(); // Form A と Form B の両方のパーサーを含む TransformsExcelParser TransformsExcelParser transformsParser = TransformsExcelParser.builder() .putKeyToParser(FORM_A_KEY, formAParser) .putKeyToParser(FORM_B_KEY, formBParser) .build(); // 入力を解析 ParseResult result = transformsParser.parse(myInput.asFiles().getFileSystem().filesAsDataset()); // 解析されたデータを出力データセットに書き込み result.dataframeForKey(FORM_A_KEY) .ifPresent(df -> formAOutput.getDataFrameWriter(df).write()); result.dataframeForKey(FORM_B_KEY) .ifPresent(df -> formBOutput.getDataFrameWriter(df).write()); // エラー情報をエラー出力に書き込み errorOutput.getDataFrameWriter(result.errorDataframe()).write(); } // 適切なアサーションを持つ FieldSpec を簡潔に作成するためのヘルパーメソッド private static FieldSpec createFieldSpec(String fieldName, String cellLocation) { return FieldSpec.of( fieldName, CellValue.builder() .addAssertions(AdjacentCellAssertion.left(1, fieldName)) .location(Location.of(cellLocation)) .build()); } }
複数の出力を持つインクリメンタル処理
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63package myproject.datasets; import com.palantir.transforms.excel.ParseResult; import com.palantir.transforms.excel.Parser; import com.palantir.transforms.excel.TransformsExcelParser; import com.palantir.transforms.excel.functions.RegexSubstringMatchingSheetSelector; import com.palantir.transforms.excel.table.CaseNormalizationOption; import com.palantir.transforms.excel.table.SimpleHeaderExtractor; import com.palantir.transforms.excel.table.TableParser; import com.palantir.transforms.excel.utils.IncrementalUtils; import com.palantir.transforms.lang.java.api.*; public final class IncrementalTransform { @Compute public void myComputeFunction( @Input("<input_dataset_rid>") FoundryInput myInput, @Output("<sheet_1_output_dataset_rid>") FoundryOutput sheet1Output, @Output("<sheet_2_output_dataset_rid>") FoundryOutput sheet2Output) { // パーサーを定義する // CaseNormalizationOptionにCONVERT_TO_LOWERCASEまたはCONVERT_TO_UPPERCASEを指定することは、 // インクリメンタル処理において特に重要です。入力ファイル間での大文字小文字の不一致により、 // 微妙な問題が発生するのを防ぐためです。 Parser sheet1Parser = TableParser.builder() .headerExtractor(SimpleHeaderExtractor.builder() .caseNormalizationOption(CaseNormalizationOption.CONVERT_TO_LOWERCASE).build()) .sheetSelector(new RegexSubstringMatchingSheetSelector("Sheet1")).build(); Parser sheet2Parser = TableParser.builder() .headerExtractor(SimpleHeaderExtractor.builder() .caseNormalizationOption(CaseNormalizationOption.CONVERT_TO_LOWERCASE).build()) .sheetSelector(new RegexSubstringMatchingSheetSelector("Sheet2")).build(); TransformsExcelParser transformsParser = TransformsExcelParser.builder().putKeyToParser("Sheet1", sheet1Parser) .putKeyToParser("Sheet2", sheet2Parser).build(); // データを解析する FoundryFiles foundryFiles = myInput.asFiles(); ParseResult result = transformsParser.parse(foundryFiles.getFileSystem(ReadRange.UNPROCESSED).filesAsDataset()); // エラーをチェックし、早期に失敗させる // インクリメンタル処理では特に、エラーデータフレームを別の出力に書き込んで // 非同期にチェックするのではなく、早期に失敗させる方が良い場合があります。 // 早期に失敗させることができない場合や、「エラーデータフレームを別の出力に書き込む」 // アプローチを採用する場合、①解析エラーが発生したファイルを入力データセットに再アップロードするか、 // ②出力データセットの1つで手動ダミートランザクションを実行して、この変換のスナップショットビルドを強制する必要があります。 // これにより、解析エラーが発生したファイルの再処理がトリガーされます。 if (result.errorDataframe().count() > 1) { throw new RuntimeException("Errors: " + result.errorDataframe().collectAsList().toString()); } // 解析されたデータを可能な限りAPPENDトランザクションで出力にインクリメンタルに書き込み、 // それが不可能な場合はマージ&リプレースのSNAPSHOTトランザクションを使用する // 以下の実装は、インクリメンタルバッチのファイルのサブセットがデータを見つけられないのが通常で // 予期されると仮定しています。そうでない場合は、データフレームのサブセットが欠落していて // 入力に未処理ファイルが存在する場合は例外を発生させることを検討してください。 // 欠落した結果は必ずしもエラーデータフレームにエラーがあることを意味するわけではありません // (たとえば、SheetSelectorが空のシートコレクションを返してもエラーとは見なされません)。 FilesModificationType filesModificationType = foundryFiles.modificationType(); result.dataframeForKey("Sheet1").ifPresent( dataframe -> IncrementalUtils.writeAppendingIfPossible(filesModificationType, dataframe, sheet1Output)); result.dataframeForKey("Sheet2").ifPresent( dataframe -> IncrementalUtils.writeAppendingIfPossible(filesModificationType, dataframe, sheet2Output)); } }