注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
安定性に関する推奨事項
このページでは、時間をかけて耐久性と安定性のあるパイプラインを作成するための主要な推奨事項について説明します。
すべての変更をバージョン管理する
データセットを生成するすべてのロジックはバージョン管理されるべきです。これにより、パイプラインに生じた回帰や変更の追跡が容易になります。具体的には以下のようになります:
- 本番レベルのパイプラインを設定する際には、Contour や Code Workbook の使用を避けてください。これらのツールは変更の追跡が難しいためです。これらのツールは開発フェーズには適していますが、パイプラインが成熟するにつれて、機能は Transforms に書き換えられるべきで、理想的には Python または Java を使用します。
- ユーザーの Code Repositories のすべてで
masterブランチがロックされていて、すべての変更が Pull Request とコードレビュアーからの承認を必要とするようにしてください。 - マージする際には、常に
Squash and mergeを推奨します。これにより、master上のコミット履歴が綺麗に保たれます。
一般的なデータ品質エラーを分離する
「センシティブ」または「不安定」なデータセットは、検証ステップを通じてパイプラインの残りの部分から分離されるべきです。特に、Fusionで作成されたデータセット、手動でのデータアップロード、その他の種類のアップロードは、パイプライン全体に影響を及ぼす可能性のあるデータ品質問題に対して脆弱です。
以下の例では、Fusion と呼ばれるデータセットが頻繁にデータ品質問題(スキーマの変更、解析エラー、不完全なデータなど)を経験しており、これがパイプラインの残りの部分に影響を及ぼしていると仮定します。
解決策は、Fusion Validated というデータセットを作成し、一部の検証ステップが通過した場合に Fusion からデータをコピーすることです。
Fusion Sheets と手動アップロードに対する検証データセットを含む例のデータフローグラフ

Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16# 例: 検証コード @transform( input=Input("/MyProject/Fusion"), validated_input=Output("/MyProject/Fusion Validated"), ) def validate(input, validated_input): found_dtypes = input.dataframe().dtypes # スキーマが壊れているか、カラム数が少なすぎることを確認 assert len(found_dtypes) >= 8, "Schema break, column count too low" # 'hours'がint型であることを確認 assert ("hours", "int") in found_dtypes, "'hours' has to be an int" # 検証済みのデータフレームを書き込み validated_input.write_dataframe(input.dataframe())
Fusionが更新されるたびに、Fusion Validatedを構築するイベントベースのスケジュールを作成します。
Fusion Validatedを他のパイプラインの入力として扱い、ビルドから無視し、それに関連するヘルスチェックを追加します。ビルドステータスは重要であり、潜在的なエラーや問題を知らせるために、Fusionを更新する担当者に連絡する必要があるかもしれません。
同様の理由がManual UploadおよびManual Upload Validatedデータセットにも適用されます。
Apex 1 のビルドから除外されたデータセットを強調表示したExample Data Lineage Graph
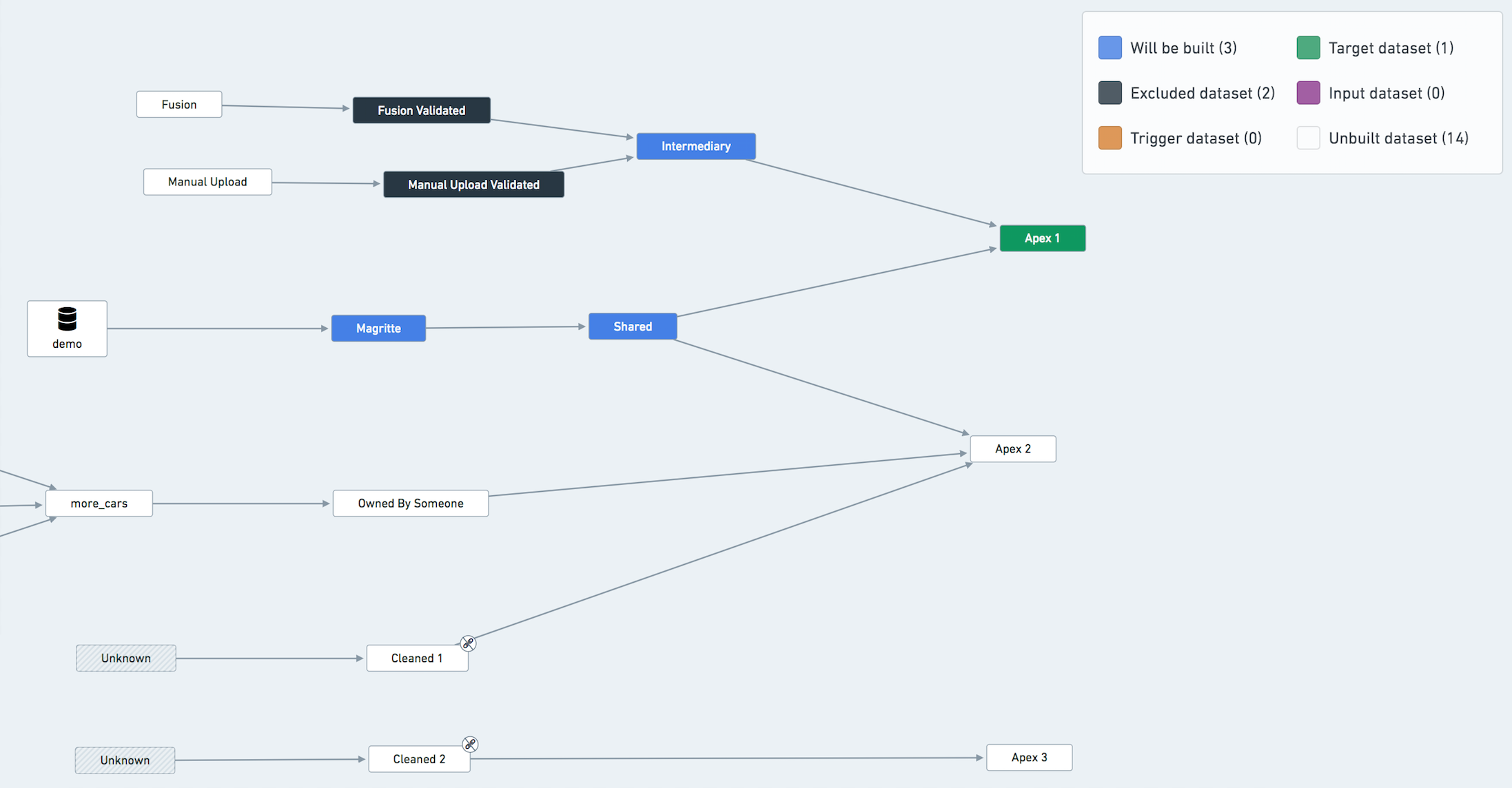
データ接続の同期をビルドから明示的に除外する必要はありません。これは常にオーケストレーションシステムによって最新と見なされます。上記のグラフで青色になっているという事実は、取り込みがトリガされることを意味しません。
共有リソースの取り扱い
プロジェクト内に多くの異なるパイプラインに属するデータセットがあるかもしれません。ビルドが完全に一致しない場合、このデータセットの構築にパイプラインがブロックされる可能性があります。
この場合、この共有データセットを必要な頻度で構築する新しいパイプラインを作成し、共有データセットを他のパイプラインの入力にすることを検討するべきです(スケジュールからは無視します)。ただし、このような操作はパイプライン設定の複雑さを大幅に増加させることに注意してください。私たちの推奨は、絶対に必要な場合を除き、これを行わないことです。
この問題を回避する別の侵襲的でない方法は、共有リソースを1つのパイプライン/スケジュールで構築し、それをすべての他のパイプラインの入力として扱うことです。たとえば、前の図では、Sharedをパイプラインの1つの入力として扱う(つまり、すべてのスケジュールから除外する)。
部分的な実行を避ける
パイプラインの一部だけを実行したり、データセットに対して 'Full Builds' を実行したりすることは避けるべきです。
パイプラインは最新の状態であるか、あるいはそうでないかのどちらかです。パイプラインの一部だけを実行すると(例えば、エクスポートフェーズだけ)、一貫性のない状態になり、パイプラインが健全かどうかを評価することが難しくなる可能性があります。端末データセットで 'full build' を実行すると、このビルドにはパイプラインを実行するべきすべての関連オプション(リトライ、失敗戦略、無視など)が欠けています。ビルドを手動で開始する必要がある場合は、スケジュールの概要ページの 'Run Schedule Now' ボタンを使用して、スケジュール設定に従ってビルドを実行すべきです。