注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
推奨されるヘルスチェック
このドキュメントでは、パイプラインの健康状態を監視するためのヘルスチェックを設定するためのベストプラクティスを提供します。これらのガイドラインに従うことで、データが入力され、データが構築され、データが出力されることを確認するための、堅牢で効果的な監視レベルを達成できるはずです。
これらのベストプラクティスは、データセット内のコンテンツの品質、正確性、または有効性を保証することはカバーしていません。これには、パイプライン内で行うべき適切な検証を決定するために、パイプラインのより詳細で機能的な知識が必要です。
また、これらのガイドラインは、ヘルスチェックの設定に関する一般的な落とし穴を回避するのに役立ちます。
- チェックが多すぎて、チェックの量がノイズになる
- 役に立たないアラートを引き起こす間違った種類のチェック
- チェックが少なすぎて、問題が発生したときにシグナルが不足している
事前知識
これらのガイドラインは、以下の理解に基づいています。
- データヘルス
- スケジュール
- スケジュールは監視の単位となります。つまり、これらのガイドラインでは、スケジュールが実行されるときにどのチェックをどこにインストールするかについての推奨事項を提供します。
- データフロー
このドキュメントでは、スケジュールの入力、中間、および出力への参照は、Data Lineageアプリケーションのスケジュール構成とは異なる、解決されたスケジュールを指します。
重要な監視概念
監視の単位:解決されたスケジュール
解決されたスケジュールは、スケジュールに関与するさまざまなデータセットに役割を割り当てるための精神モデルです。いくつかのデータセットは、スケジュールによって構築できるため、スケジュールのデータセット選択の一部であることが関与します。他のデータセットは、ビルドに必要な必須の入力として関与します。データセットの役割によって、異なるヘルスチェックが推奨されます。
スケジュール内のデータセットは、次のいずれかの役割を持つことができます。
- 出力は、スケジュールの最終ステップであるデータセットです。スケジュールによって構築されますが、スケジュール内の他のデータセットには使用されません。
- 中間は、スケジュールによって構築されるデータセットであり、スケジュールの出力ではありません。
- 入力は、スケジュールによって構築されないデータセットであり、スケジュールによって使用されます。入力は、スケジュールの外側の最初のレイヤーであり、たとえば、Data Connectionの同期や自分で構築しない派生データセットが該当します。
具体的な例として、スケジュールが以下のデータセットを構築すると想像してください。
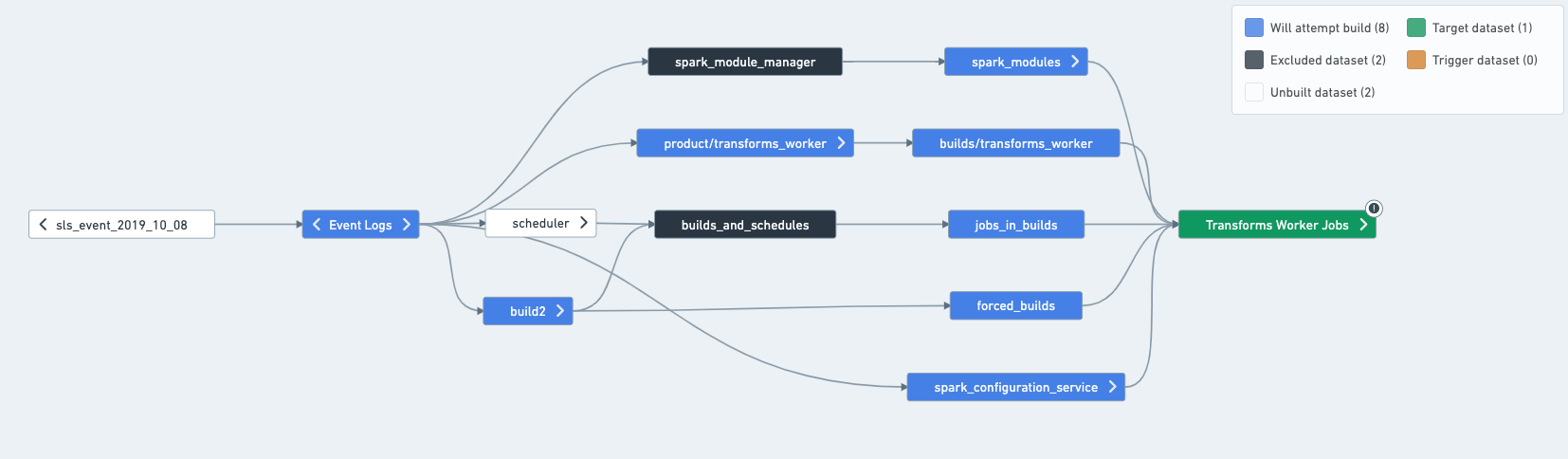
この場合、スケジュールを次のように分割できます。
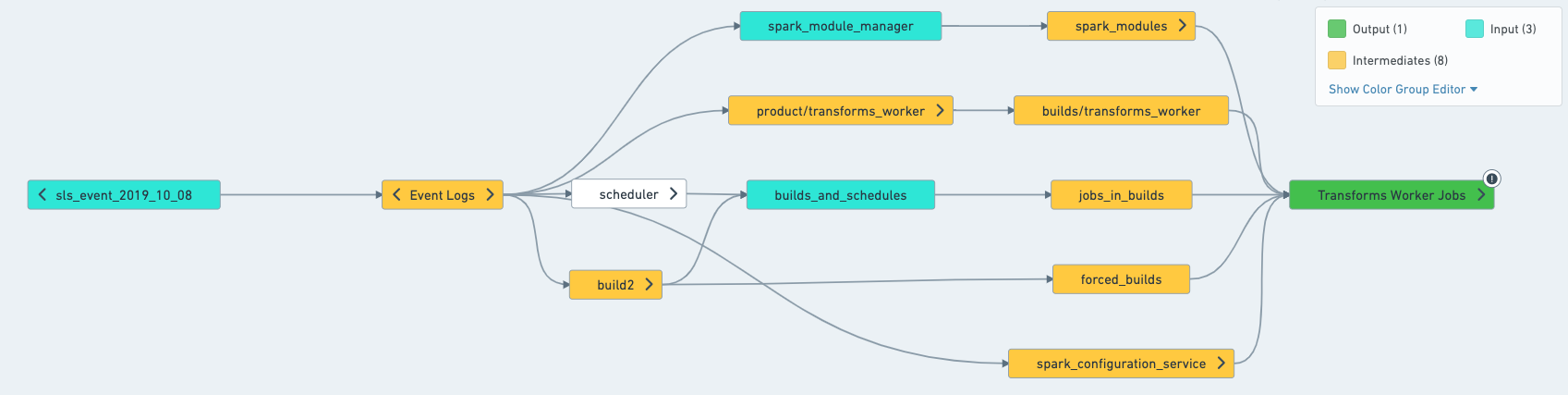
実際に構築されるものを理解する
スケジュールの入力、出力、および中間が何であるかを判断する最も簡単な方法は、データフローでスケジュールを開くことです。データフローで、サイドバーからスケジュールを選択すると、スケジュールの色分けが適用され、スケジュールがどのようなビルドを試みるかを理解するのに役立ちます。
-
ターゲットと構築を試みるものは、通常、スケジュールによって構築されます。ただし、Data Connectionの同期されたデータセットの場合は、スケジュールで「強制構築」が設定されている場合にのみ構築されます。
-
除外は、スケジュールによって決して構築されません。
-
*入力(接続ビルドのみ)*は、スケジュールによって構築されません。ただし、それらの上流に別の入力がある場合には構築されます。
古さに関する短い説明:実際には、スケジュールはこのグラフのすべてを構築することはめったにありません。なぜなら、一部のデータセットはすでに最新であり、それらを再計算することはリソースの無駄になるからです。ただし、スケジュールを解決することは、スケジュールが触れるすべてのことを理解することです。
ターゲットと出力
スケジュールは「ターゲット」で定義されており、これらは通常「出力」と同じです。ただし、ターゲットと出力が異なる場合があります。
(1)データセットは、「ターゲット」として明示的に定義されていなくても、「出力」になることがあります。
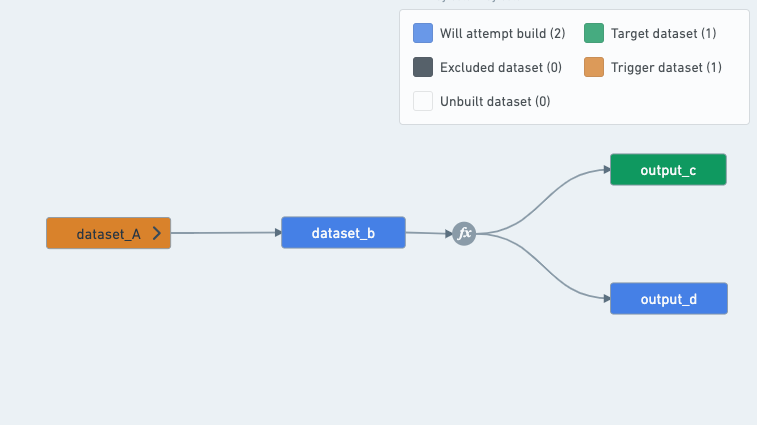
output_cを構築するスケジュールは、B、C、およびDの間の変換が複数の出力変換であるため、必ずoutput_dも構築する必要があります。
したがって、output_cを対象とするスケジュールは、output_cとoutput_dの両方を出力として持ちます。output_dは、スケジュール内の他のデータセットには使用されないスケジュールによって構築されるデータセットだからです。

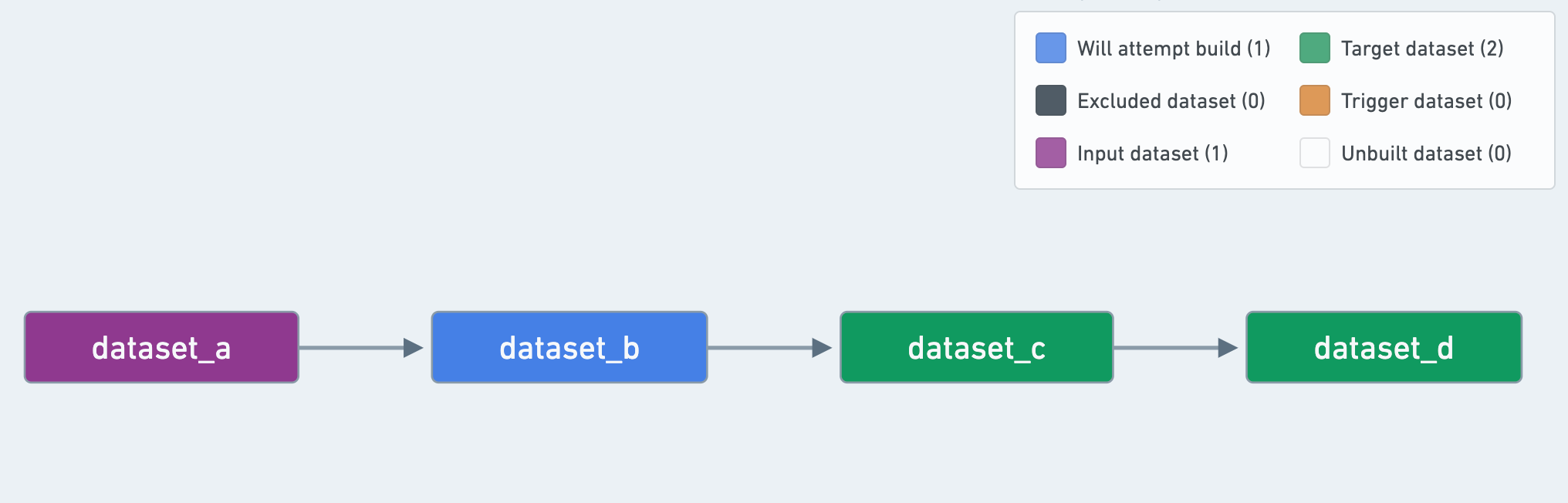
(2)データセットが「ターゲット」として定義されていても、「出力」としては扱われません。
データセットがスケジュールの「ターゲット」として定義されていても、スケジュール内の他のデータセットに使用される場合、それは「出力」データセットではなく「中間」データセットと見なされます。
この例では、dataset_cはスケジュールの「ターゲット」ですが、「出力」としては扱われません。
スケジュールでヘルスチェックをどこにインストールするべきか?
以下のステップバイステップガイドは、Job vs Build Statusチェック、およびSync vs Data Freshness vs Time Since Last Updatedチェックの理解に基づいています。これらのチェックの違いがわからない場合は、ここでヘルスチェックのタイプを確認してください。
スケジュールは、パイプラインの適切な表現を提供します。監視の推奨される単位であるため、監視は設定したスケジュールの品質によって決まります。ヘルスチェックを設定する前に、スケジュールがここで概説されているベストプラクティスに従っていることを確認するために時間をかけてください。
入力へのチェック
パイプラインの解決された入力すべてにチェックをインストールします。パイプラインが失敗した場合、根本原因を追跡できるようにすることが重要です。入力の古さやスキーマの破損が発生することがあります。入力にチェックをインストールすることで、それらを検出するのに役立ちます。注:現時点では、特定のデータセットには、同じタイプのチェックが1つしか存在できません。インストールしようとしたチェックがすでに存在する場合は、それを購読するだけです。
- スキーマチェック:これにより、列が追加または削除された場合、またはパイプラインが依存する列名と型が予期せず変更された場合に警告が表示されます。
- 最終更新時刻(TSLU)[オプション]:パイプラインの入力に対してデータが適時に配信されることを確認できます。これにより、パイプラインが時間通りに構築されない場合の原因分析を行うのに役立ちます。これはオプションのチェックであり、更新頻度を正確に期待できる場合にのみインストールする必要があります。
- 上流の所有者が入力データセットをすでに監視している場合は、このチェックを適用しないでください(上流のデータセットにチェックを追加する権限がない可能性があります)。
- 「空のトランザクションを無視する」を有効にすることをお勧めします。
- ジョブまたはビルドステータス:オプションですが、Data Connectionの同期や所有権が明示的に定義されていないデータセットに推奨されます。ビルドステータスは、ジョブステータスよりも推奨されます。これは、入力データセットの一部でビルドが失敗し、キャンセル/中止された場合にもアラートが表示されるためです。
出力へのチェック
パイプラインの解決された出力すべてにチェックをインストールします(これらはスケジュールによって構築されますが、スケジュール内の他のデータセットには使用されません)。
- ビルドステータスチェック:これにより、パイプライン内のすべての失敗が検出されます。すべてのデータセットにジョブステータスチェックを入れる必要はありません。
- ビルドステータスを使用する結果として、スケジュールごとに出力が少なくなることをお勧めします。
- ビルド期間チェック:可能な競合や、パイプラインをブロックするビルドを検出するのに役立ちます。また、次のような問題の検出にも役立ちます。
- 異常な入力(例:入力のキーの分布が変更されると、結合が突然かかる時間が長くなります)。ヒント:ステージ内のタスクがすべて完了していない失敗したジョブは、ジョインがスキューされていることを非常に強く示しています。
- コード変更によって導入されたパフォーマンスの低下。
- 最終更新時刻チェック(TSLU):このチェックを使用して、パイプラインが必要なカデンスで更新されることを確認します。
- 例:パイプラインが24時間ごとに実行される必要がある場合(例えば、毎日午前9時、平均ビルド時間が1時間です)、次のいずれかを行うことができます。
- 「最終更新時刻」のしきい値を26時間に設定し(ビルド時間を考慮し、少し余裕を持たせるため)、チェックを自動更新します。
- しきい値を2時間に設定し、スケジュールでチェックを実行します。上記の例では、毎日午前11時です。ヒント:「自動解決」フラグをチェックしてください。そうしないと、ビルドが少し遅れて完了した場合、パイプラインが24時間完全に不健康と見なされます。
- 例:パイプラインが24時間ごとに実行される必要がある場合(例えば、毎日午前9時、平均ビルド時間が1時間です)、次のいずれかを行うことができます。
- スキーマチェック:パイプラインの出力は、Contour、Slate、Object Explorerなどの他のアプリケーションでユーザーが使用することがよくあります。これは、出力スキーマが壊れた場合に警告することが重要であることを意味します。下流のアプリケーションを更新する必要があるか、ユーザーに通知する必要があるかもしれないからです。
- ビルドステータス、ビルド期間、およびTSLUチェックが出力データセットにある場合、ビルドステータスとビルド期間で何か問題があることが早期に警告されます。 TSLUが発火すると、何かがおかしい可能性が高く、誰かが調査する必要があります。
オプションのチェック
必要に応じて、重要な中間データセットにチェックをインストールしてください。これらのデータセットは、ユーザーが別のアプリケーションで直接使用するか、同期を介して使用します。
- スキーマチェック:出力と同様に、ユーザーがアプリケーションでデータセットを使用している場合(Contourであろうと同期を介した場合であろうと)、スキーマの変更により、破損が発生するか、手動のフォローアップが必要になる可能性があります。
- データフレッシュネス:データセットの内容がフレッシュネス要件を満たしていることを確認するために使用します(ソースシステムでデータセットに行が追加されたときのタイムスタンプ列が適切にある場合)。
- 最終更新時刻チェック。パイプラインの途中に重要なデータセット(たとえば、他の多くのユーザーに使用されるデータセット)がある場合、それが遅延した上流などのために時間通りに更新されない場合があります。パイプライン入力チェックのおかげでそれを検出できるはずですが、TSLUチェックを追加すると便利です。
- 同期がある場合:
- 同期ステータスチェック:同期されるデータセット(FoundryアプリケーションのSlateや外部システムへの同期など)にインストールする必要があります。
- 同期フレッシュネスチェック:これは、データフレッシュネスとTSLUとともに評価されると特に役立ちます。問題がa)データセットが時間通りに更新されなかったb)データセットが更新されたが、ソースシステムが新鮮なデータを提供しなかったc)データセットに新鮮なデータがあるが、同期が再読み込みされていないことをすぐに判断できます。
サマリーテーブル
上記で説明したベストプラクティスは、参照のためにこのテーブルにまとめられています。
| ビルドステータス | スキーマ | ビルド期間 | TSLU | データフレッシュネス | 同期フレッシュネス | 同期ステータス | |
|---|---|---|---|---|---|---|---|
| 入力 | ✓ | ✓ (追加を許可) | |||||
| 中間 | |||||||
| 出力 | ✓ | ✓ (完全一致) | ✓ | ✓ | |||
| ユーザー向けデータセット* | ✓ (完全一致) | ✓ | |||||
| 同期されたデータセット* | ✓ (完全一致) | ✓ | ✓ | ✓ |
[*] 入力、中間、または出力データセットになることがあります。ユーザー向けデータセットは、Contourなどのアプリでユーザーが直接使用するデータセットです。