注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
HyperAuto V1 概要
HyperAuto V1(別名 SDDI または Bellhop)は、Palantir のソースから価値への自動化スイートの初版です。HyperAuto V2は SAP に対してリリースされ、そのデータソースに対しては強く推奨されていますが、HyperAuto V1は現在も以下のいくつかのソースタイプに対してサポートされています。
- Salesforce
- Oracle NetSuite
- SAP(V1は推奨されません。代わりにV2を使用してください。)
HyperAuto V1 の詳細なドキュメンテーションはプラットフォーム内で利用可能です。そこから、Software-Defined Data Integrationを参照して設定オプションの範囲を確認してください。
アーキテクチャ
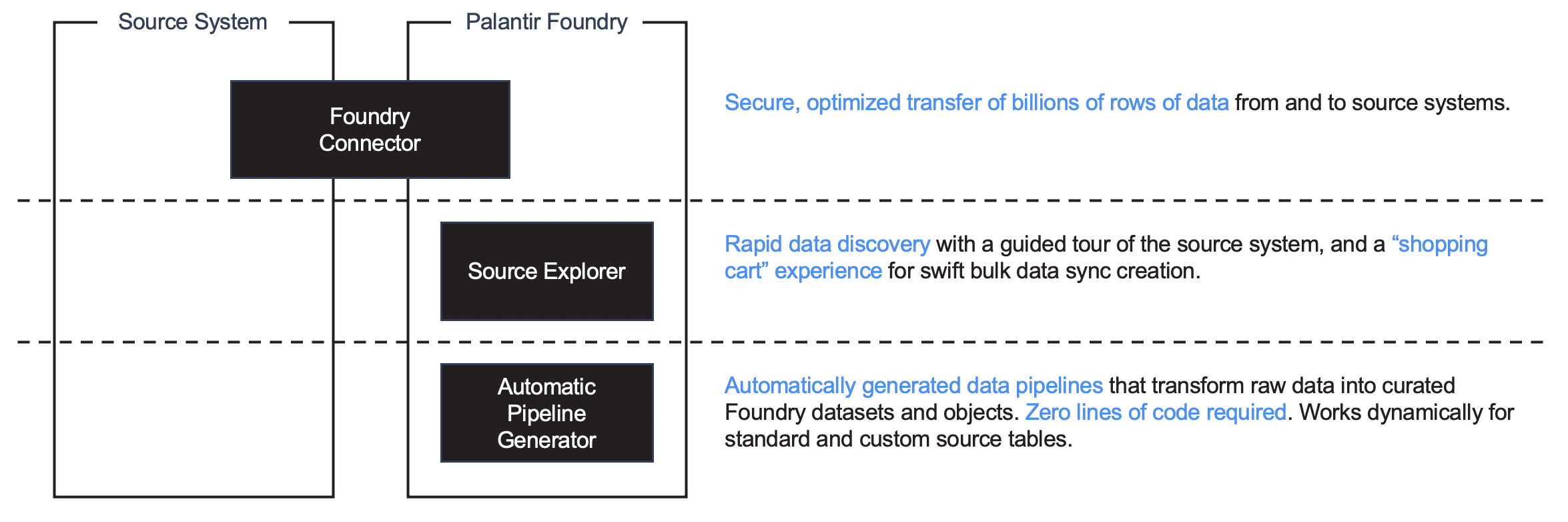
HyperAuto V1は、最小限の労力で原始データからオントロジーへのデータを統合するために設計された3つのコンポーネントで構成されています。
- コネクタは、ソースシステムから、そしてソースシステムへの大規模なデータの転送を安全かつ最適化された方法で可能にします。
- ソース探索は、ガイド付きの方法で迅速にデータを発見し、迅速な一括データ同期作成と設定のための "ショッピングカート"体験を提供します。
- 自動パイプライン生成は、自動生成されたデータパイプラインを使用して、原始データをキュレートされた Foundry データセットと オントロジー のオブジェクトタイプにトランスフォームします。
パイプライン生成
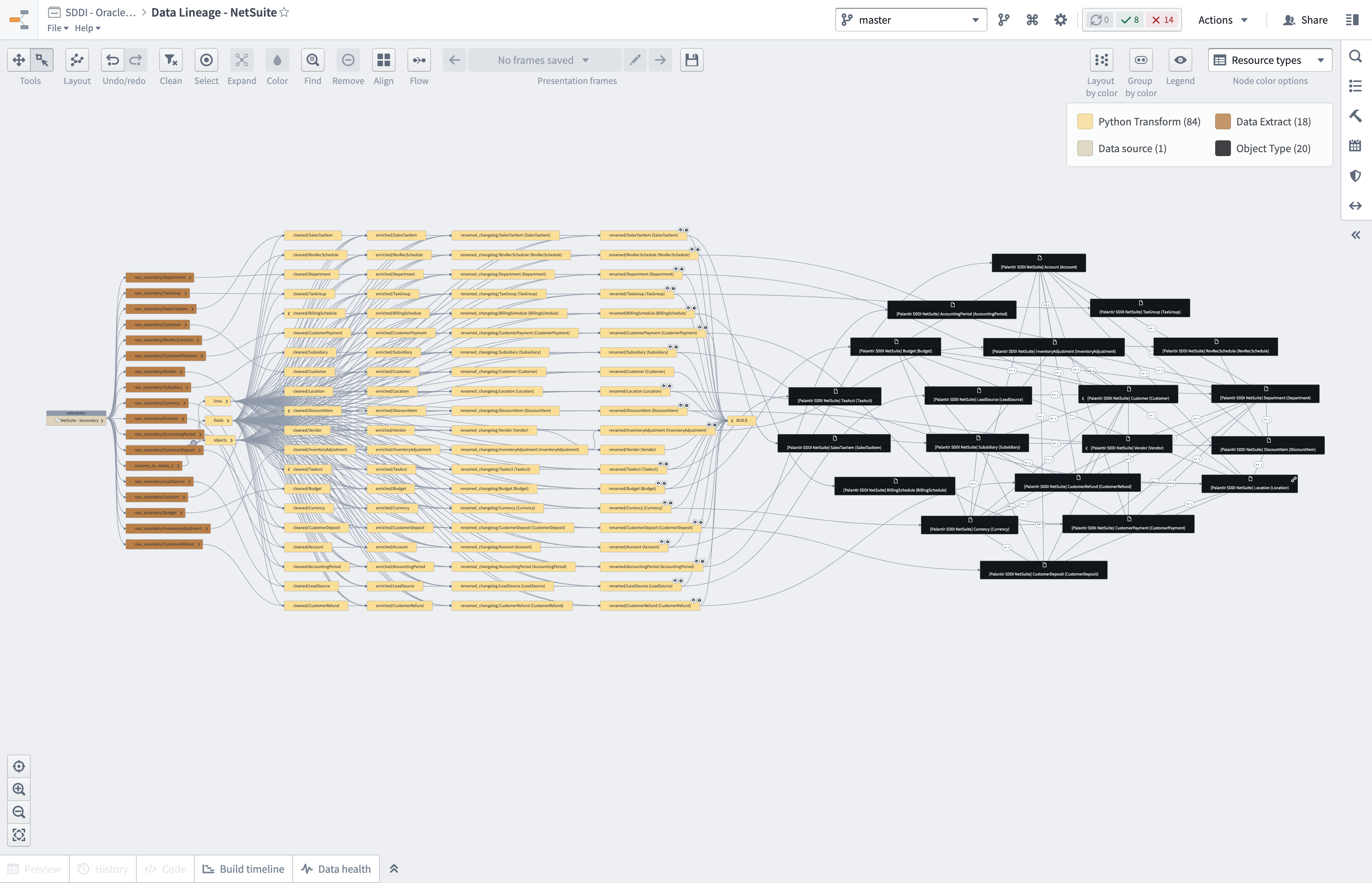
自動パイプライン生成は、一般的なソースシステムを統合するためのアウトオブザボックスのデータパイプラインを作成します。パイプラインは、データがオントロジーとワークフローで使用できるようにデータを準備します。パイプライン生成は各ソースシステムについての組み込みの知識を提供するため、この機能を使用すると効率が向上し、各基礎となるソースシステムの複雑さを完全に理解する必要がなくなります。
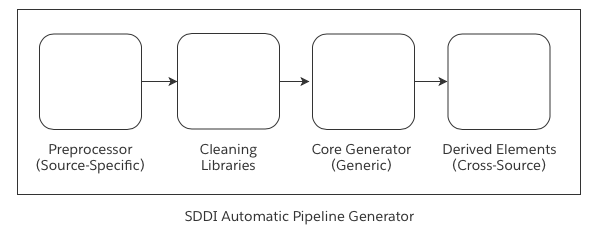
生成されたパイプラインには4つの主要なステップが含まれます。
- ソース特有の前処理は、定義済みのスキーマを持つメタデータデータセットのセットを生成します。これらのメタデータには、ソースシステムからのデータを理解するための必要な情報が含まれています。
- クリーニングライブラリは、すべてのデータセットに対して標準化されたデータクリーニング手順を適用し、システムに流入するすべてのデータに対してベストプラクティスが遵守されることを確保します。
- コア生成は、データの強化、列の名前変更、重複排除、データのユニオンを行い、分析、レポーティング、オントロジーでのワークフローに使用できる使用可能なデータを生成します。
- 派生要素は、結合テーブルの生成、時系列データセット、オントロジーにも供給される豊富な派生情報を提供する豊富な列の生成を含む高度なワークフローに対する事前定義されたサポートを提供します。
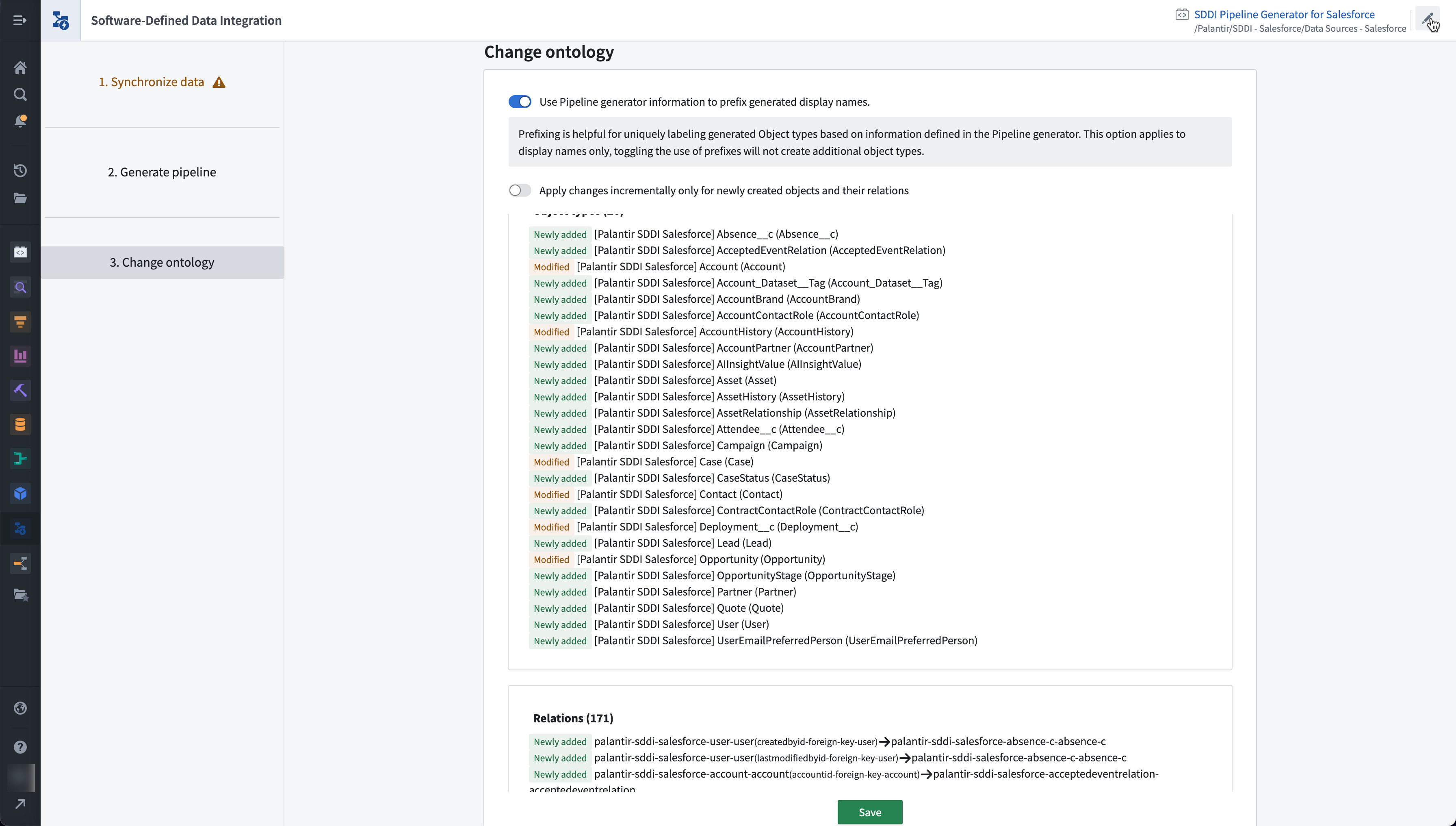
オントロジー作成
パイプラインが自動生成された後、HyperAuto V1はさらにオントロジーを自動的に生成することもサポートしています。これによりデータ統合プロセスが完了し、Foundry の広範なオントロジー対応アプリケーションセットのおかげで、すぐにデータの検索、分析、さらにはデータの上にアプリケーションを構築することができます。