注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
HyperAuto V2の始め方
このガイドはHyperAuto V2のものです。HyperAuto V1の始め方は、HyperAuto V1のドキュメンテーションをご覧ください。
もし直接的なシステムへの接続がなく、静的なデータを取り扱っている場合は、フォルダー基盤のパイプラインを作成できます。
以下のステップに従って、初めてのHyperAutoパイプラインを作成します:
-
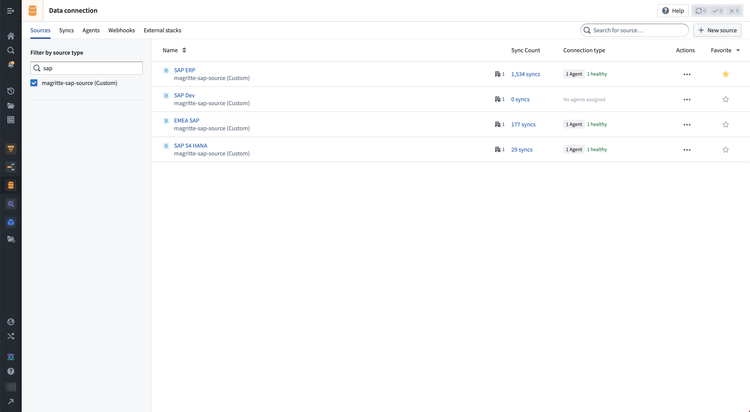
データを同期させたいサポート対象のソースに移動します。ユーザーのFoundryインスタンス上のすべてのソースのリストは、Data Connectionアプリで見つけることができます。
-
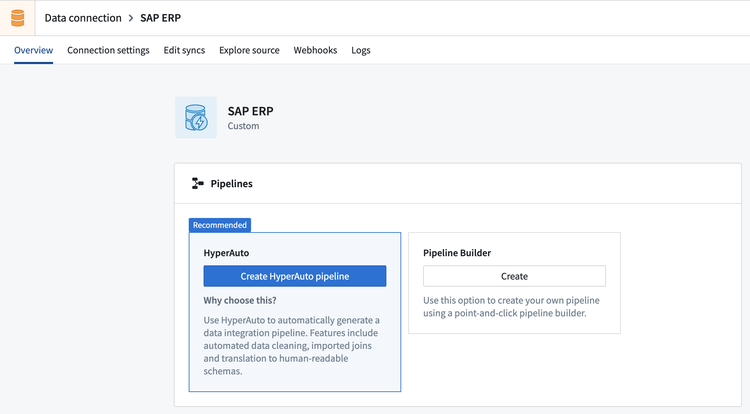
ソースの特定の概要タブから、HyperAutoパイプラインを作成を選択して、HyperAutoパイプラインウィザードを開きます。
-
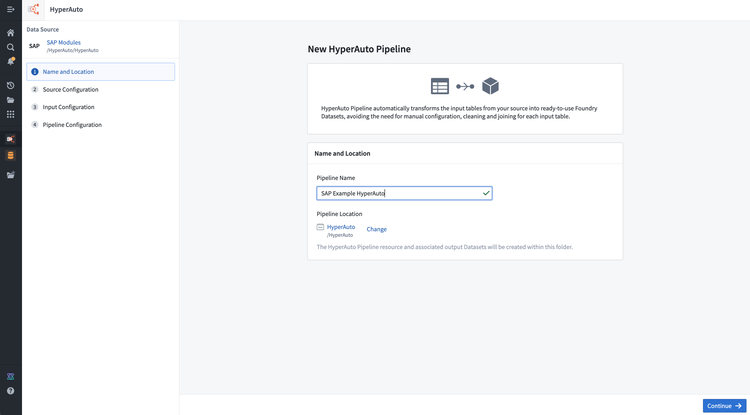
新しいHyperAutoパイプラインリソースと対応する生成リソースの名前と場所を定義します。HyperAutoパイプラインは、入力データセットと同じプロジェクト内に存在する必要があります。
-
必要に応じてソースのサブシステムを選択します(例えば、SAPソースの「context」)、そして取り込み方法を選択します(バッチまたはストリーミング、詳しくはアーキテクチャを参照してください)。
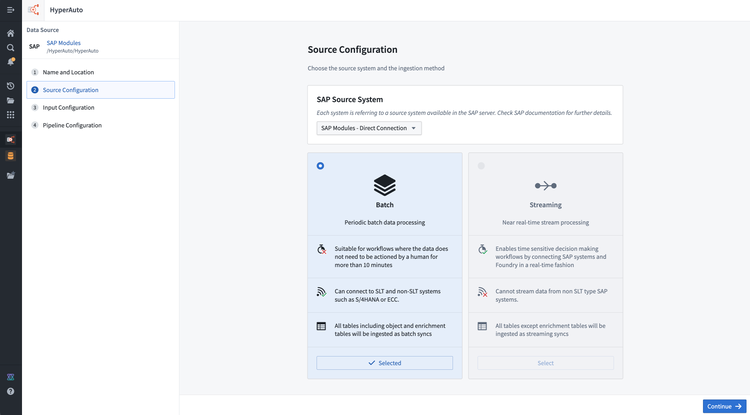
-
入力設定ステップで、データを処理するソーステーブルを選択します。テーブルは個別に、カテゴリー("module")ごとに、またはワークフローごとに選択できます。また、Data Connectionの同期がないテーブルを入力として選択することもできます。選択した入力に既存の同期がある場合、HyperAutoは最新のものを使用するようデフォルト設定されます。選択した入力を再設定するには、入力設定テーブルボタンの上にマウスを置きます。このメニューから、既存の同期を選択するか、新しい同期を作成することができます。
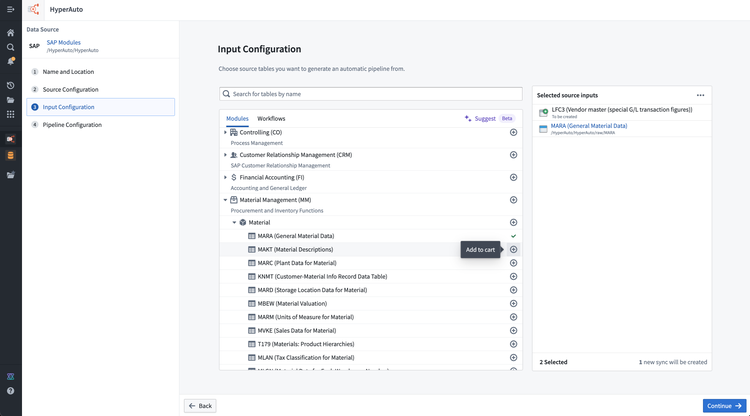
-
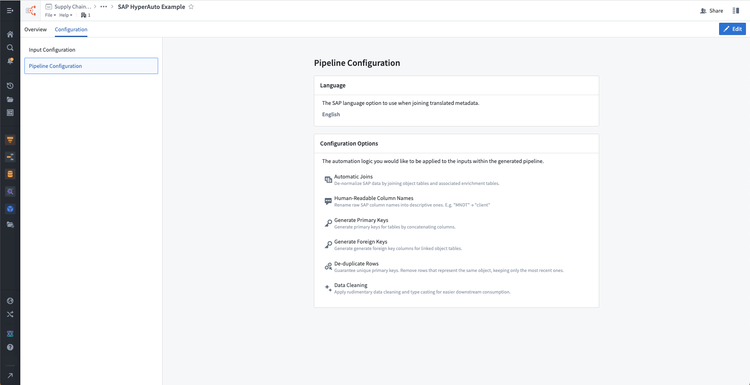
望ましいパイプラインの設定を決定します。これには言語とトランスフォームのオプションが含まれます。詳しくは設定オプションを参照してください。
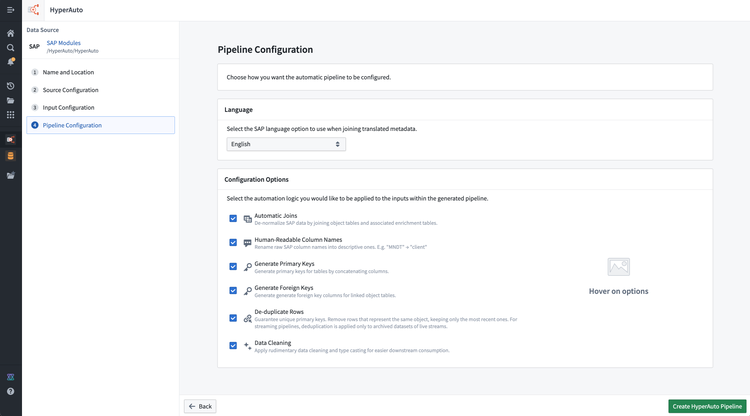
-
HyperAutoパイプラインを作成を選択します。新しいHyperAutoパイプラインが作成され、データの処理を始めます。パイプラインの概要ページにリダイレクトされ、生成の進行状況を監視することができます。
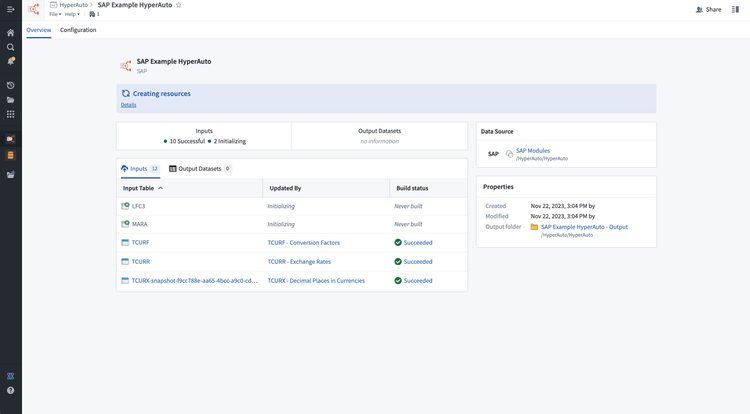
-
生成が成功したら、概要ページを使ってパイプラインとその関連リソース(入力同期とデータセット、出力データセットとオブジェクト)の管理と監視を行うことができます。
- ビルダーパイプラインを表示を選択して、読み取り専用のビルダーパイプラインを開き、トランスフォームロジックを詳細に閲覧します。
-
設定タブでは、HyperAutoパイプラインの入力とパイプライン設定が表示されます。このタブで編集を選択すると、新しい提案を作成し、設定を更新することができます。