注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
フォルダーに基づく SAP パイプライン
HyperAuto V2 は、直接の SAP 接続を必要とせずに SAP データからパイプラインを作成することもサポートしています。これにより、ソースミラー、静的データ抽出、事前にフィルター処理されたデータを含む、多種多様なアーキテクチャに対応する柔軟性が提供されます。
SAP 静的データ用の HyperAuto V2 パイプラインを設定する
SAP データセットの上に HyperAuto V2 パイプラインを作成するには、以下を含む単一の Foundry フォルダーを設定します:
- 入力テーブルデータセット(処理したい SAP テーブルごとに1つのデータセット)
- データ辞書テーブル
すべてのデータセットを同じフォルダーに直接保管することで、自動検出が機能し、パイプライン作成の手順を最小限に抑えます。入力テーブルデータセットに SAP テーブル名(例:MARA)をつけると、自動マッピングプロセスが容易になり、必要な手動操作の数を減らすことができます。
データは、技術的な列名を持つ生の SAP テーブルの未トランスフォームの抽出物である必要があります。
データ辞書テーブル
データ辞書テーブルには、HyperAuto がパイプラインを生成するために必要な SAP からのメタデータが含まれています。これには、テーブルと列の説明、テーブル間の関係の説明などが含まれます。
フォルダーに基づく SAP HyperAuto パイプラインを作成するために必要なデータ辞書テーブルは以下の通りです:
- DD02L(SAP システム内のテーブルの詳細)
- DD02T(異なる言語でのテーブルの説明文とラベル)
- DD03L(フィールド定義、データ型、長さ)
- DD04T(複数の言語でのデータ要素の説明とラベル)
- DD05S(外部キー関係の詳細、親テーブルと子テーブルのフィールドを含む)
- DD08L(SAP システム内のテーブル間の外部キー関係に関するメタデータ)
データ辞書テーブルは、その生形式であり、HyperAuto が適切に機能するためにはフィルター処理されていない必要があります。
例
SAP システムの MARA と MAKT テーブルの上に基本的な HyperAuto パイプラインを作成するには、以下のデータセットを含むフォルダーを作成します:
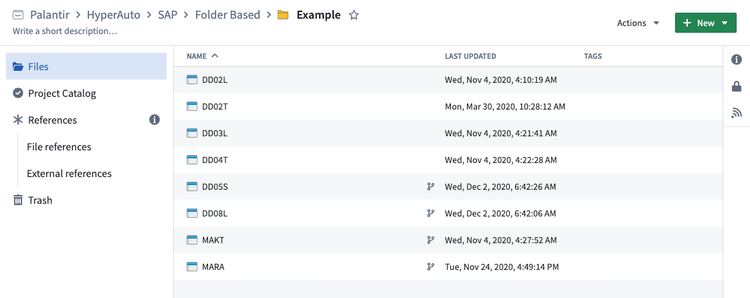
フォルダーに基づくパイプラインを作成する
- ユーザーの入力フォルダーが設定されたら、新しいパイプラインを作成するために HyperAuto のホームページに移動します。これは、Foundry の左側のサイドバーにあるアプリケーションブラウザから見つけることができます。
- + パイプラインを作成をクリックして、パイプライン作成ダイアログを開きます。
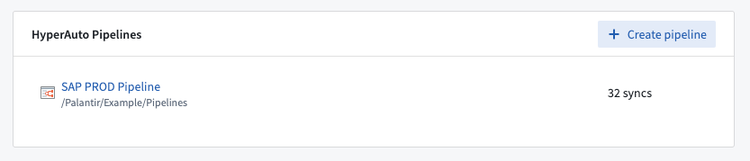
- ここでは、通常のパイプライン(これにはライブ SAP 接続が必要)またはフォルダーに基づく SAP パイプラインを作成する選択肢が提供されます。"フォルダー(SAP のみ)"を選択し、参照をクリックしてユーザーの入力フォルダーを選択します。
パイプラインを作成をクリックすると、HyperAuto パイプライン作成ウィザードに移動します。
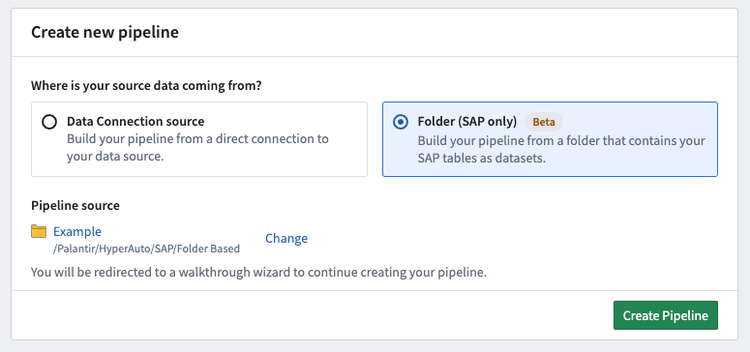
設定ウィザード
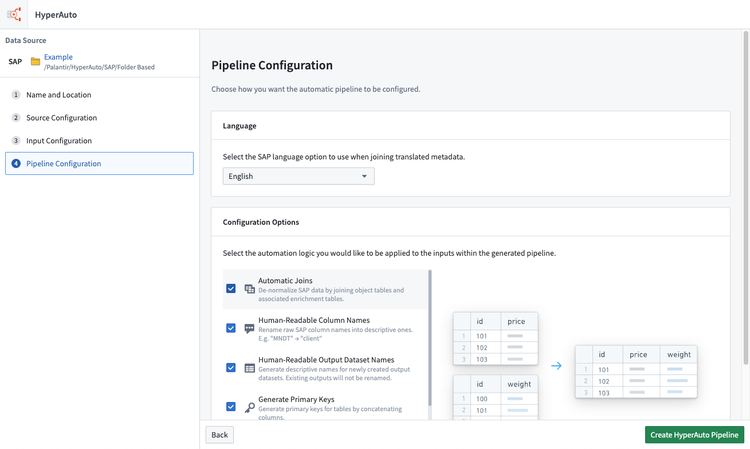
- ここで、ソースに基づくパイプラインと同様に、基本的なパイプライン設定を定義します。
まず、パイプラインの有効な名前と場所を選択します。
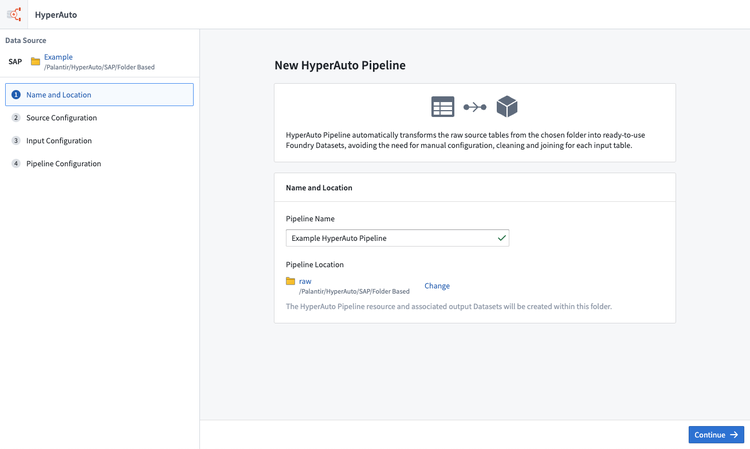
- ソース設定ステップは、HyperAuto がデータ辞書テーブルを認識して、パイプラインを構築するための必要なメタデータを読み取ることができることを確認します。
入力が正しく設定されていれば、これらは自動的にマップされます。それ以外の場合は、進行する前に各メタデータテーブルを手動でマップします。
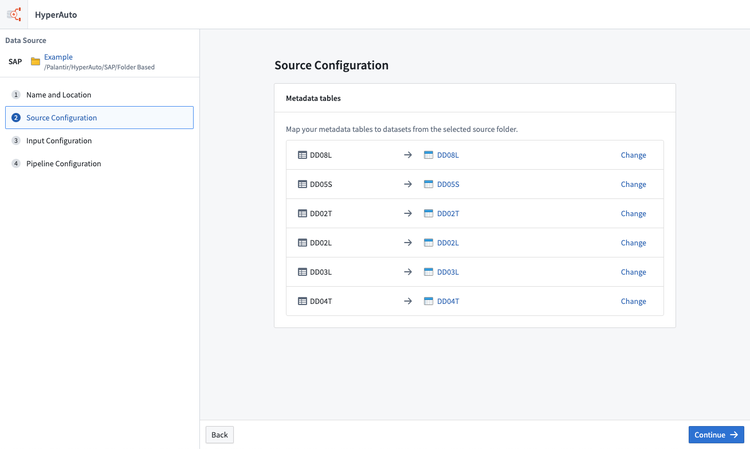
- 次のステップは、処理する入力を選択することです。デフォルトでは、発見可能な入力(入力フォルダー内に名前で直接一致するデータセットがあるもの)のみが入力選択インターフェースに表示されます。
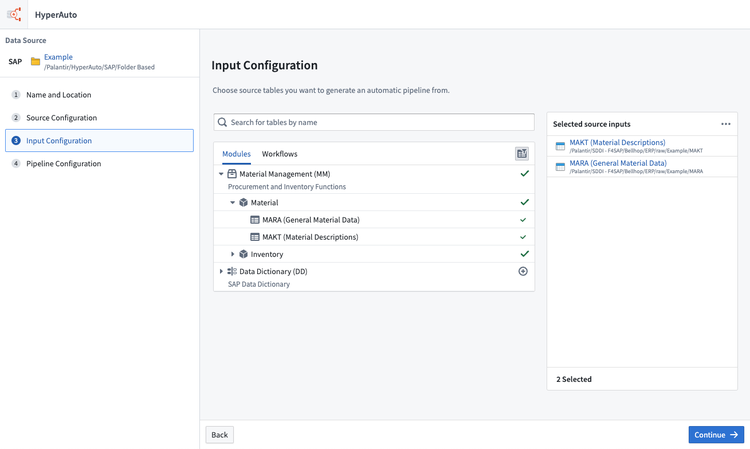
利用可能なすべてのテーブルを表示するには(データ辞書テーブルに基づく)、未発見のテーブルを表示をクリックします。
未発見のテーブルを追加すると、入力を適切な Foundry データセットに手動でマップする必要があります。
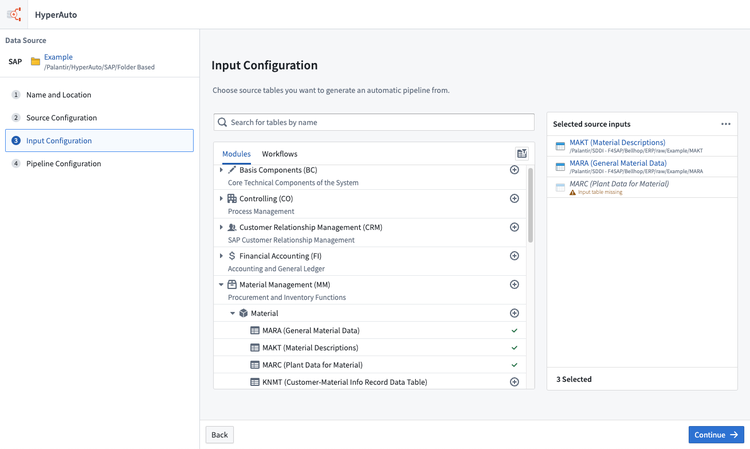
マップされていない入力でパイプラインを作成すると、その入力は無視されます。
- パイプラインの設定を選択し、HyperAuto パイプラインを作成をクリックしてウィザードを完了し、パイプラインの作成をトリガーします。