注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
HyperAuto V2設定オプション
このページでは、HyperAuto V2の設定オプションについて説明します。HyperAuto V2の設定プロセスは以下のステップで構成されます:
HyperAuto V1の設定リファレンスについては、過去のドキュメンテーションを参照してください。
名称と場所
HyperAuto V2の設定ウィザードで最初に行うステップは、新しいパイプラインの名前と、Foundryファイルシステム内での希望するフォルダーの場所を指定することです。HyperAutoパイプラインリソースと関連する出力データセットは、このフォルダー内に作成されます。
ソース設定
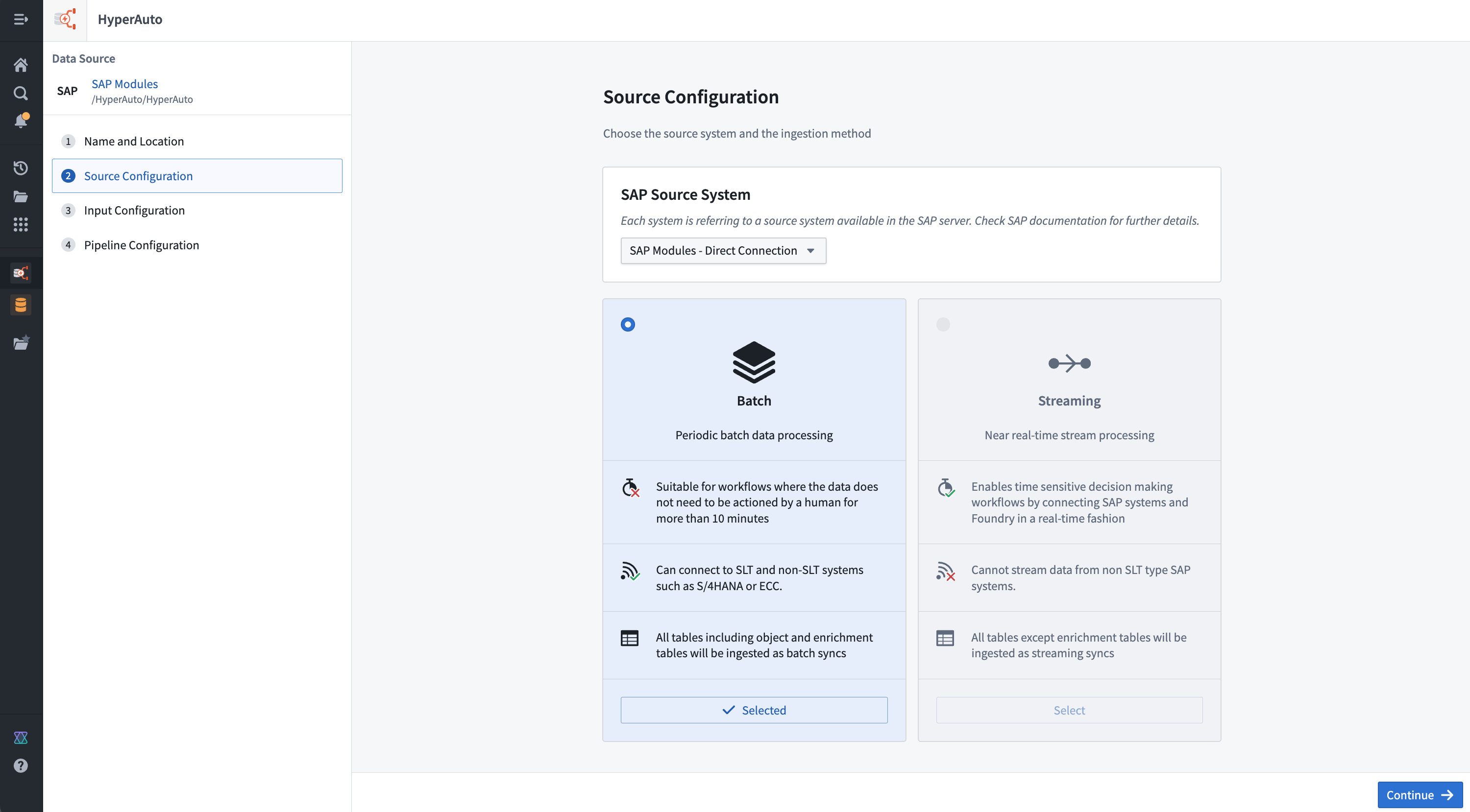
HyperAuto V2のソース設定ページでは、ソースシステムと取り込み方法を選択するのに役立ちます。
ソースシステム
この選択肢は、ユーザーが選択しなければならないサブシステムを持つソース(例えばSAP内の"contexts")で利用できます。サブシステムとは、そのソース内の設定で、それ自身の利用可能なテーブルとメタデータのセットを結果とするものを指します。その結果、サブシステム間で切り替えると、サポートされているpipeline mode(バッチ対ストリーミング)や、入力設定ページで選択可能なテーブルや既存の同期など、他の利用可能な設定が完全に変わります。
SAPソースシステム
FoundryをSAPシステムに接続するための3つの主要なアーキテクチャパターンがあります:
- 直接: コネクタはERPシステム自体のアプリケーションサーバーにインストールされ、テーブルに直接アクセスします。
- SLT: コネクタはSAP SLTレプリケーションサーバーにインストールされ、そこから基本的なERPシステムに接続します。SLTは、ストリーミングpipeline modeを使用するために必要です。
- リモート: コネクタは、基本的なERPシステムに接続する"ゲートウェイ"アプリケーションサーバーにインストールされます。これは、SAPソースがコネクタの事前条件を満たさない場合によく使用されます。 SLTまたはリモート接続の場合、ユーザーは、どのSAPサブシステムに接続するかを識別するために使用されるコンテキストを選択する必要があります。
パイプラインモード
HyperAutoは、同期とデータ変換の2つのモードをサポートしています。ソース設定ページでストリーミングモードまたはバッチモードから選択できます。
- バッチ: パイプラインの各実行はすべての入力を再処理し、すべての既存の出力を上書きします。これはデフォルトのモードで、集約や重複排除など、最大限の機能を提供します。このモードは、ほとんどのユースケースで推奨されます。
- ストリーミング: ソースシステムは、まだ処理されていないデータを常にポーリングします。ソースシステムで利用可能になると、データはすぐに処理され、同期からオントロジーまでの遅延をほぼリアルタイムに短縮します。これは、オントロジーに依存してストリームデータを重複排除するリアルタイムアプリケーションを強化するのに特に有用です。
ストリーミングは、データをリアルタイムで処理するために常時計算が必要であり、したがってソースシステムとFoundry内の負荷を増加させる可能性があります。
入力設定
入力設定ページは、ユーザーが特定のHyperAutoパイプラインで処理する特定の入力を選択する場所です。
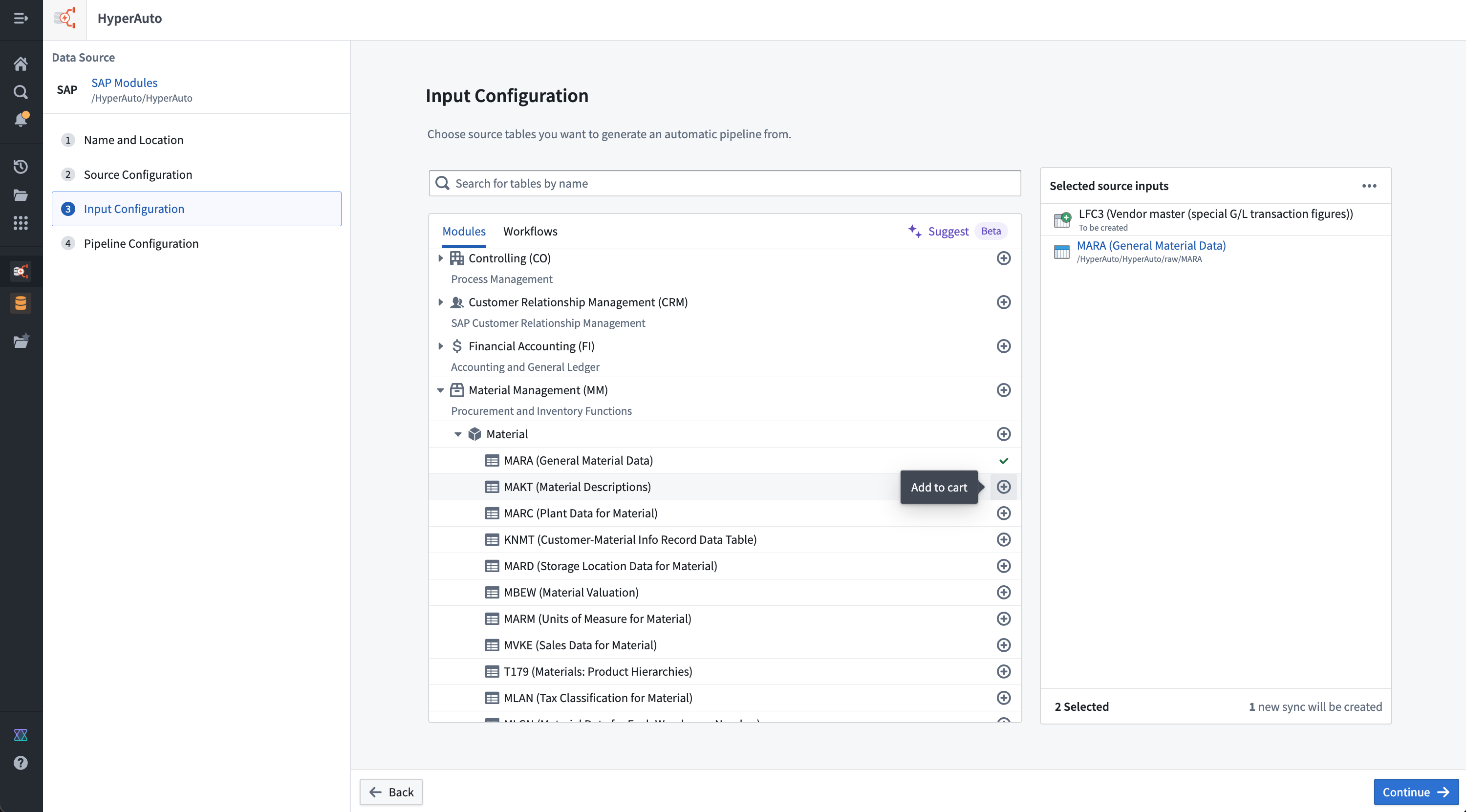
使いやすさのために、入力選択UIは、関連するソーステーブルを探すためのいくつかの方法をサポートしています。SAPの場合、方法は次のとおりです:
- モジュール: ソース内のテーブルを意見付けられたカテゴリに分け、ユーザーが探索し、必要に応じて一括追加できる階層的なビューを提供します。テーブルは、関連性がある場合は複数のモジュールに存在することがありますが、一度以上選択することはできません。
- ワークフロー: テーブルのカテゴリ化の別の形で、ソースの特定の一般的なユースケース(例えば、SAPソースの供給チェーン管理)に焦点を当てています。同様に、ユーザーはワークフローを使用して必要に応じて探索し、一括追加することができ、これらとモジュールの間で切り替えることができます。これにより、進捗を失うことなく、誤って選択を重複することなく切り替えることができます。
同期の作成も入力設定ページから利用でき、ユーザーは既に同期が存在しない任意の入力に対して新しい同期を作成することができます。これにより、ユーザーは新鮮なソースから完全に設定されたHyperAutoパイプラインまで、数回のクリックで開始することができ、各同期がどのように設定するべきかを解決する必要はありません。
同期の作成はベータ機能であり、ユーザーのFoundryインスタンスで利用できない場合があります。この機能を使用することに興味がある場合は、プラットフォームの管理者に連絡してください。
ユーザーのFoundryエンロールメントには、提案タブでAIP機能が有効になっている可能性があります。詳細はAIPドキュメンテーションを参照してください。
パイプライン設定
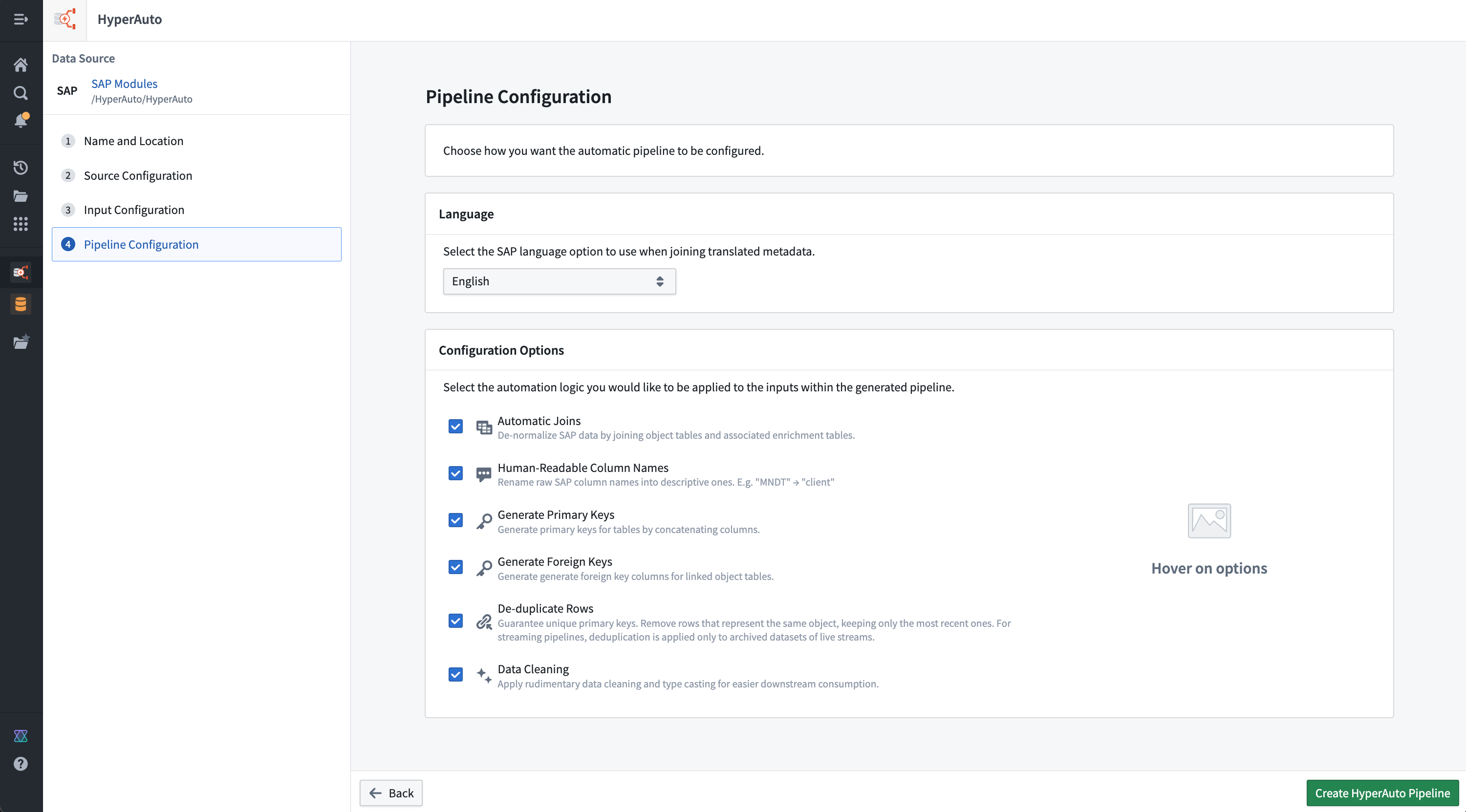
パイプライン設定ページでは、ユーザーのニーズに合ったパイプラインを設定することができます。オプションには以下のようなものがあります:
言語選択
複数の言語のデータを含むテーブルがあるソースについては、HyperAutoは言語フィルタリングステップを提供して、出力で可能な言語ごとに複数の行を格納するのを避けます。ここで選択した言語は、関連するテーブルに対してフィルターとして適用され、その後に追加の変換(他のテーブルへの結合など)が適用されます。
設定オプション
ユーザーは、パイプライン設定オプションから、ソース入力全体にどれだけの処理を自動的に適用するかを決定できます。すべての設定オプションはデフォルトで有効になっていますが、必要に応じて無効にすることができます(例えば、機能とパイプラインのパフォーマンスのバランスを取るため)。
自動結合
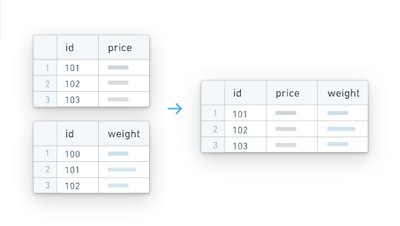
HyperAutoは、ソースのメタデータ経由でテーブルの分類を受け取り、それらをオブジェクトテーブルまたはエンリッチメントテーブルに分割します。この定義では、エンリッチメントテーブルとは、それ自体では本質的に価値がないが、関連するオブジェクトテーブルの拡張子やルックアップテーブルとして機能するテーブル(例えば、テキストの説明テーブル)を指します。
このようにして、HyperAutoはソースからobject <-> enrichmentテーブルの関係をクエリし、エンリッチメントテーブルからオブジェクトテーブルへの対応する左結合を生成します。これにより、他のテーブルに対する結合を必要とせずに、各オブジェクトのための豊かで包括的な非正規化データセットが得られ、広範なレビューが可能となります。
これは、Foundryオントロジーを構築する際に特に役立ちます。ここでは、セマンティックに向けた非正規化データモデルの使用が一般的なアプローチです。
SAPでの自動結合
SAPの場合、"TEXT"テーブルはHyperAutoの処理内でエンリッチメントテーブルとして分類されます。例えば、MAKT(材料説明)はMARA(一般的な材料データ)に結合することができます。
ストリーミング
エンリッチメントと分類されたテーブルは、ストリームではなくバッチ入力として消費されます。これにより、パイプラインは、これらのテーブルからコアストリームへの"ルックアップ"左結合を作成することができます。これにより、一度に2つのライブストリームを結合することなく、ストリームデータが強化されます。
エンリッチメントテーブルの既存の同期は、Foundryのストリーミングと、使用されているAvroファイルフォーマットに準拠したスキーマがある場合に限り、関連する入力を設定する際に提供されます。
ヒント:SAPの同期では、cleanFieldNamesForAvro設定オプションをtrueに設定すると、スキーマがAvro(ストリーミング)に準拠していることが確保されます。HyperAutoが作成した同期では、このオプションがデフォルトで有効になります。
人間が読める列名
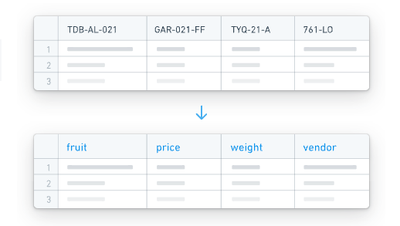
HyperAutoは、ソースが提供する列のメタデータを使用して、ソースが定義した列名を、ソースのスキーマに詳しくないユーザーが簡単に使用できる名前に変更することができます。
これは、列の人間が読める名前を元の列名に連結する形で行われ、形式はHuman readable_|_originalとなります。これにより、データとのやりとりの際に両方の形式にアクセスでき、最大の利便性を提供します。
主キーの生成
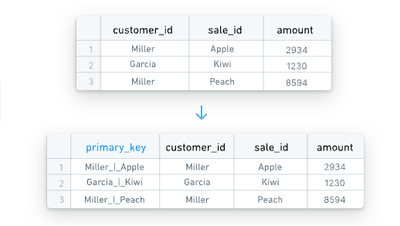
ソースが単一列の主キーを持っていない場合、HyperAutoは動的に主キーを生成することができます。ソースのメタデータには、どの列が一緒になると主キーとなるかを示す情報が含まれており、HyperAutoはこれを使用してprimary_key列を作成する連結ロジックを作成します。
値は_|_セパレータで連結されます。
主キーを単一の列とすることは、出力をオントロジーオブジェクトの元データセットとして使用するために必要です。
外部キーの生成
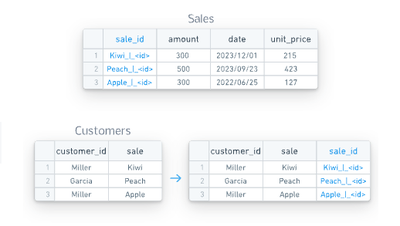
HyperAutoはまた、ソースのデータモデルメタデータで定義されたオブジェクト間の関係にアクセスすることができます。このメタデータを使用して、パイプライン内で関係ごとに外部キー列を生成するロジックを作成することができます(関連する列を連結することで、主キーロジックと同様)。これは、結合やオントロジーリンクの作成に使用することができます。
外部キーは、形式がcolumn1_column2_|_foreign_key_tableAとなるように名付けられます。つまり:
- 列の値は、
column1とcolumn2を_|_セパレータで連結することで作成され、 - 外部の関係が存在するため、ユーザーはこのテーブルをこの列を介して
tableAのprimary_keyを介して結合できます。
オブジェクト間のオントロジー関係を生成するためには、外部キーが必要です。
自動結合設定オプションが有効になっている場合、オブジェクトとエンリッチメントテーブルの関係に対しては外部キーは作成されません。
行の重複排除

HyperAutoは、重複した行を含むテーブルを自動的に重複排除するロジックを提供します。これは、変更が発生するたびに新しい行を追加する変更データキャプチャ(CDC)システムなどのケースで役立つことがあります。HyperAutoは、主キーごとの最新の最新の行を選択して重複排除を行います。
ストリーミング
ストリーミングモードでは、重複排除は異なる方法で処理されます。2つのストリーミング出力が作成されます。メインの出力は、バッチまたは増分パイプラインによって読み取られるときに重複排除したデータセットに解決します。変更ログ出力は、必要に応じてバッチまたは増分パイプラインによって読み取られるときに重複排除されていないデータセットを提供します。両方の出力は、通常どおり別のストリームから消費することができます。
テーブルの主キーを構成する列が以下のタイプのいずれでもない場合、それらは重複排除が機能することを確保するために文字列にキャストされます:
- 文字列
- タイムスタンプ
- ブール値
- バイナリ
- 整数
- バイト
- 短縮
- 浮動小数点数
- 長い
- ダブル
データクリーニング
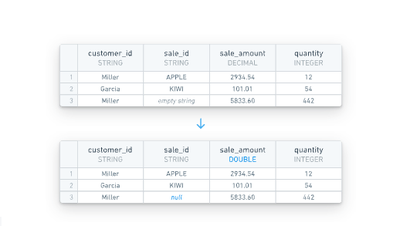
データクリーニング設定オプションは、すべてのテーブルから一般的なデータ清潔性の問題を削除します。対処される問題の種類については以下の情報を参照してください。
- 空文字列の処理:
""文字列はnullに変換されます(Foundryのデータに対する標準的な処理)。 - DECIMALのキャスティング:
DECIMALデータ型はDOUBLEにキャストされます。これにより、プラットフォーム全体で利点が得られます(オントロジープロパティのサポートを可能にするなど)。