注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
HyperAuto V2 アーキテクチャ
このページでは HyperAuto V2 のアーキテクチャについて説明します。 HyperAuto V1 のアーキテクチャの説明については、HyperAuto V1 概要をご覧ください。
HyperAuto V2 は、データ統合ワークフローの3つの主要なコンポーネント - Data Syncs、Builder Pipelines、およびオントロジー - の周囲でオーケストレーションと自動化を提供し、サポートされているソースから即時に使用できる出力を自動的に生成します。
HyperAuto は、データソースのメタデータを活用し、ソースをリアルタイムでクエリして、どのように同期を構築するべきか、どのようなトランスフォームロジックを適用するべきか、そして適切なオントロジーをどのように設計するべきかについての意見を導き出します。
HyperAuto パイプラインとは、同期からオブジェクトまで、単一の HyperAuto インスタンスによって管理されるすべてのリソースを指します。各パイプラインは、ユーザーが提供するソーステーブルのリストを入力として受け取り、それらを Foundry に同期(必要な場合)し、それらを価値ある、即時に使用できる出力データセットおよび(オプションで)オントロジーオブジェクトにトランスフォームします。ユーザーは、個々のニーズに合わせて、ソースごとに複数の HyperAuto パイプラインを作成することができます。
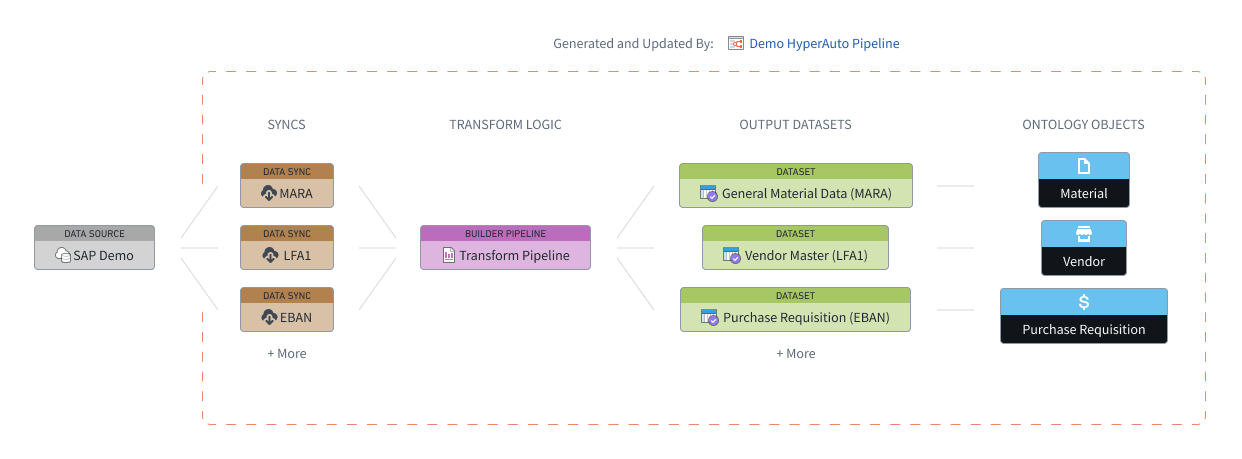
データ同期
ソースへの直接の接続が存在しない場合、HyperAuto は静的なファイルの使用もサポートしています。この場合、このセクションは適用されません。詳細については、フォルダーベースの SAP ドキュメンテーションをご覧ください。
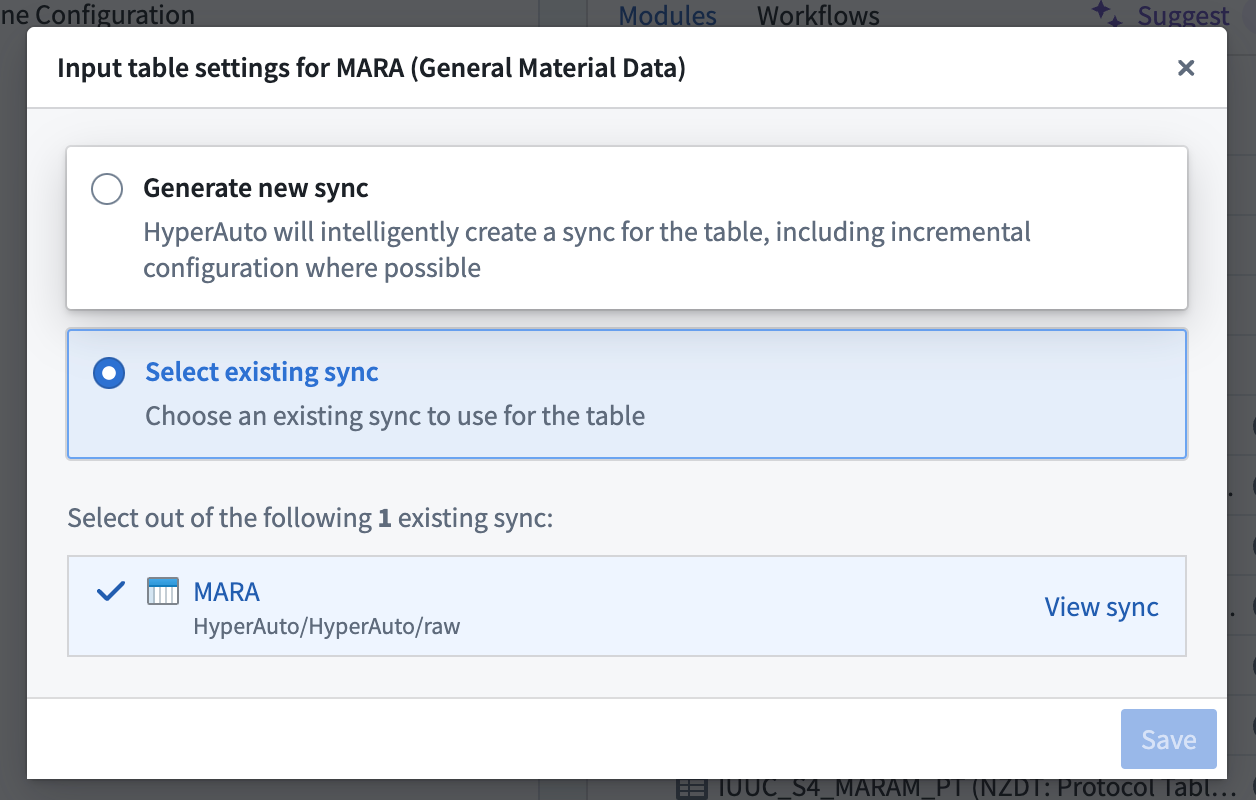
HyperAuto は、ソース上の全ての可視テーブルへのアクセスを提供します。ユーザーが既存のデータ同期にマップされていないソーステーブルを選択した場合、新しいデータ同期が自動的に生成されます。
選択したソーステーブルに対して一つまたは複数のデータ同期が既に存在する場合、最新の同期がデフォルトで選択されます。入力設定 ページで 入力テーブルの設定 ボタンにマウスを移動することで、その選択を変更することができます。そこから、使用する別の既存の同期を選択するか、新しい同期を作成することを選択できます。
データのスケールによっては、HyperAuto が新しいデータ同期を作成した場合、生成にかなりの時間がかかる可能性があります。これは、データ同期が HyperAuto プロセスの残りの部分、たとえばビルダーパイプラインの生成などを行う前に初期実行を必要とするためです。
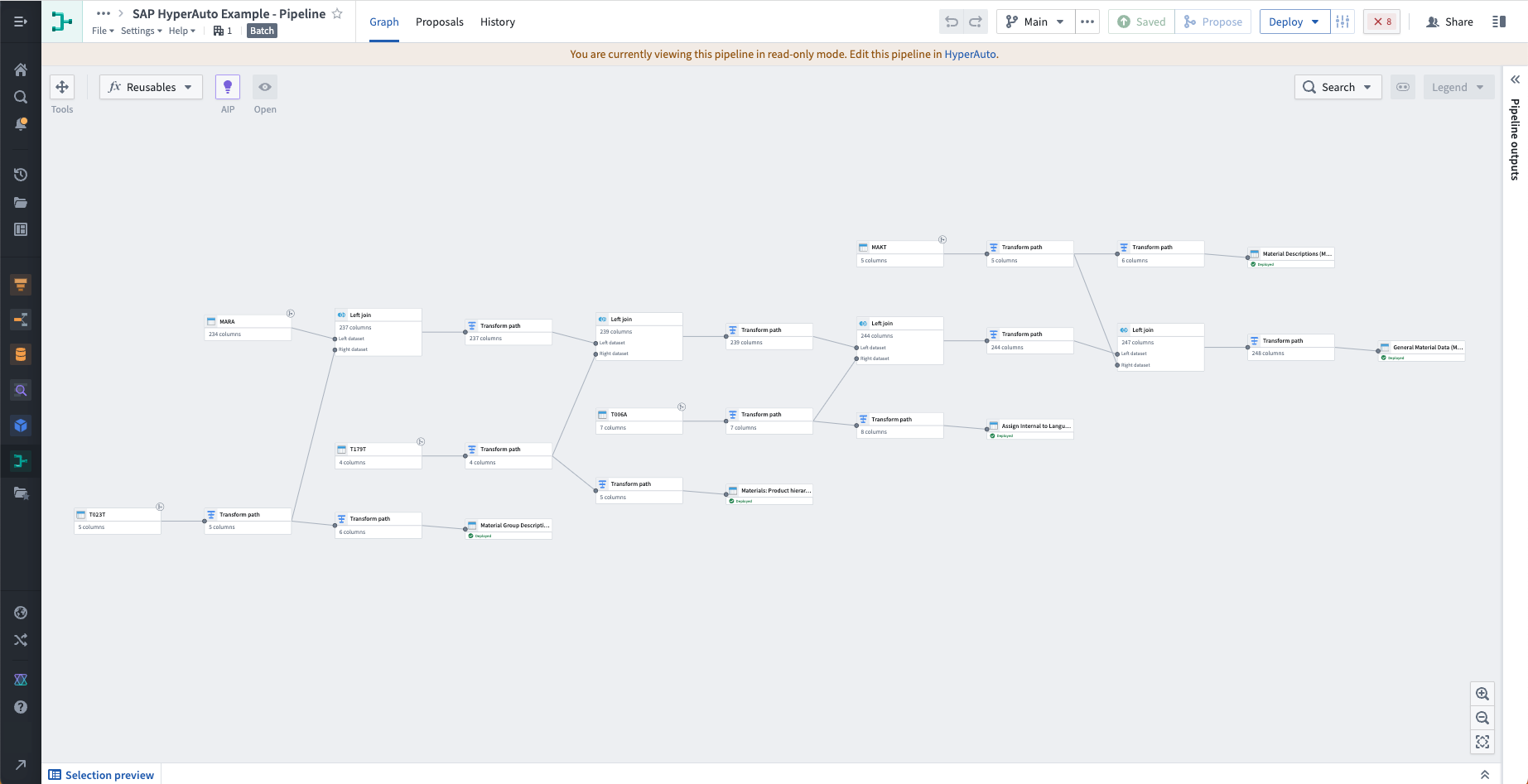
データ変換 (Pipeline Builder)
HyperAuto パイプライン内のデータ変換は、難解なソースデータをクリーンで豊かな出力に変換し、すぐに分析やアプリケーションの構築に使用できるようにします。
HyperAuto パイプラインは、自動生成された builder pipelines によって駆動されています - Foundry 内でのデータ変換の主な手段です。
HyperAuto は、ソースタイプとユーザーの設定に基づいて、意見を持った変換ロジックを動的に生成します。ユーザーは、HyperAuto パイプライン概要ページから パイプラインの表示 を選択することで、このビルダーパイプラインを表示することができます。このパイプラインへの編集は、提案を通じて HyperAuto の設定を変更することで行われます。
HyperAuto 内で利用可能な変換機能の種類は以下の通りです:
- クリーニング: ソースシステムは、しばしば間違ったデータ型、null / 空の値の取り扱いが不適切、または文字列値に不要な空白があるといった一般的な「クリーンさ」の問題を持つデータをエクスポートします。HyperAuto は、これらの問題(およびそれ以上)を修正するための意見を持った変換オプションを提供します。
- リネーミング: ソースのメタデータを使用することで、HyperAuto は出力テーブルと列の名前を説明的で自己説明的に変更できます、つまり、しばしば人間が読めないスキーマをそのまま使用するのではなく。
- ジョイニング: ソースシステムは、関連情報(例えばメタデータ)を別のテーブルに保存することがよくあります、例えば「ノーマル」なデータモデルに準拠するために。HyperAuto は、ソースのデータモデルを理解してこれらのテーブルを結合し、分析の容易さとオントロジーの強固な基礎を提供する、非正規化された豊かな出力データセットを提供します。
- フィルター処理: 望ましくない行(たとえば、重複)は、HyperAuto によって自動的にフィルター処理されます、例えば、変更データ取得入力の重複を削除するために。
バッチ およびリアルタイムの ストリーミング パイプラインモードの両方がサポートされています、詳細については 設定オプション をご覧ください。
オントロジー
HyperAuto は、ソースのデータモデルを使用して、生成された出力データセットに基づいたオントロジーを動的に生成することができます、これにはオブジェクト間のセマンティックリンクの定義も含まれます。
この設定を有効にすると、新しい(サポートされている)ソースから完全に定義されたオントロジーまで、手動での介入が必要なく数分で移動することができます。
この機能に興味がある場合は、あなたの Palantir 代表者に連絡してください。
リソース管理
HyperAuto パイプラインは、それらが作成するすべてのリソースを完全に制御するように設計されており、ユーザーは一貫してシステムへの利益とアップグレードを受け取ることができます、これにはパフォーマンスのアップグレードとバグ修正も含まれます。これらのパイプラインの設計は、既に生成されたリソースを微調整することを容易にします、たとえば新しい変換ステップや入力をパイプラインに追加するなどです。
基礎となるリソースへの任意の編集(例えば、同期やビルダーパイプライン)は、変更の競合を避けるために、HyperAuto アプリケーションを通じて管理する必要があります。
必要に応じて、HyperAuto パイプラインリソースを削除すると、対応するビルダーパイプラインに対する所有権が削除され、通常通りビルダーパイプラインに直接編集を加えることができます。