注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
SQL プレビュー
SQL プレビュー機能を使用して、構造化データセットのクイック分析を表示します。SQL プレビューは、読み取り専用のSQLクエリを実行できるSQL「スクラッチパッド」で構成されており、以下を含みます。
- データセットのスキーマ/列名の自動補完
- バッククォート「`」内で他のデータセットを検索し、効率的な
JOINクエリを実行 - ハイライトされたクエリを実行するためのキーボードショートカットなど、エディターフレンドリーな機能を使用
- 実行されたSQLクエリの結果をプレビュー表として出力
- ユーザーの好みに合わせて列と下部パネルのサイズを調整
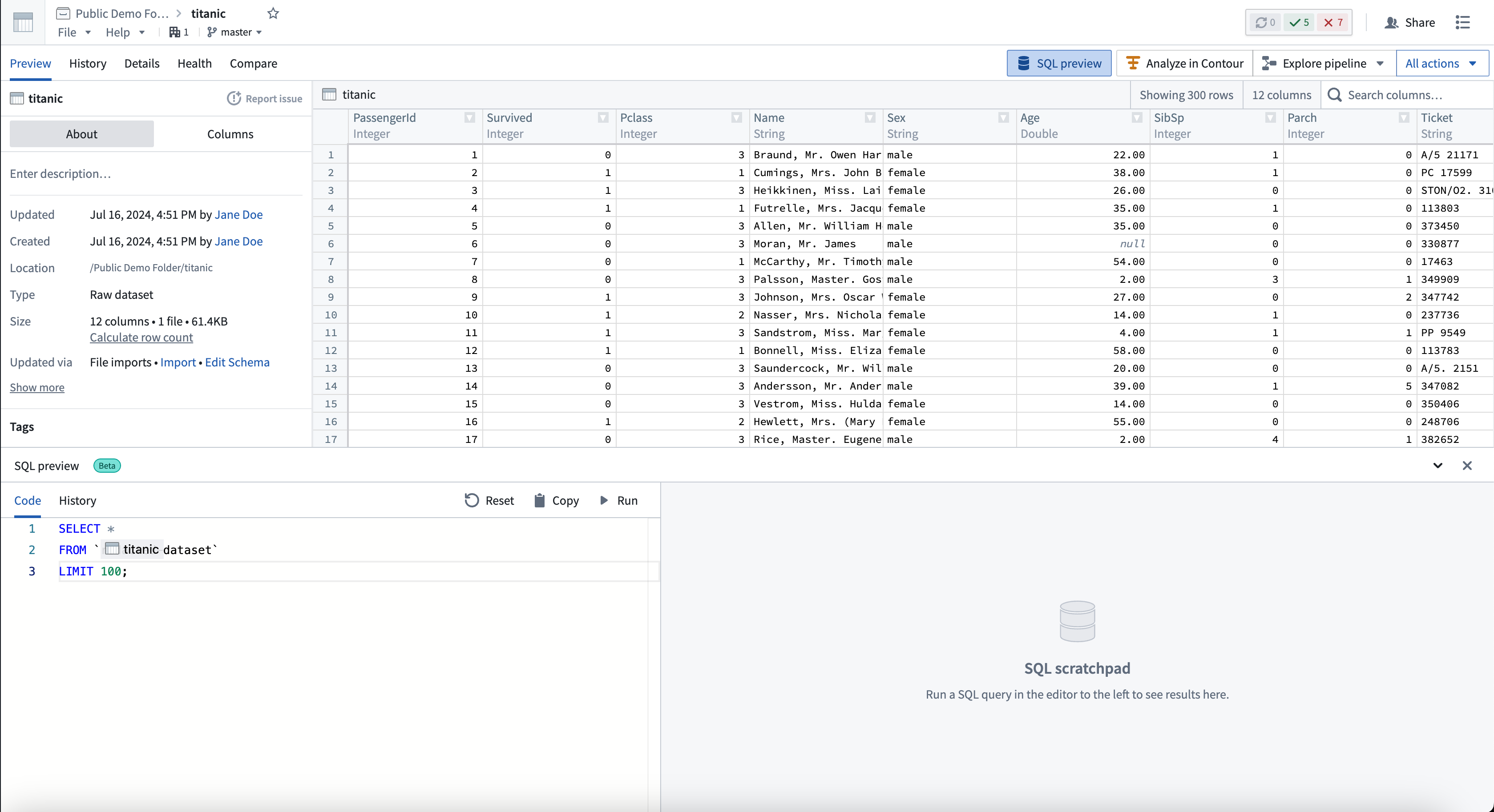
SQLデータを分析する
以下の手順に従って、SQL プレビュー機能を使用します。
- 任意の表形式のデータセットに移動します。
- 画面の左下隅から SQL プレビュー を選択して、調整可能なプレビューパネルを開きます。
- コード タブで、データセットに対する読み取り専用クエリ(結合を含む)を記述します。
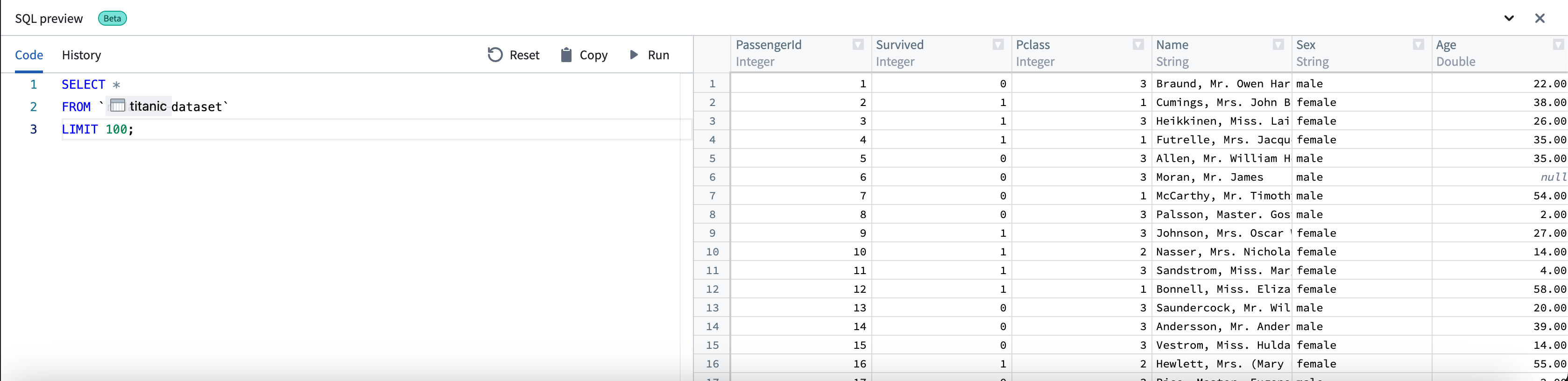
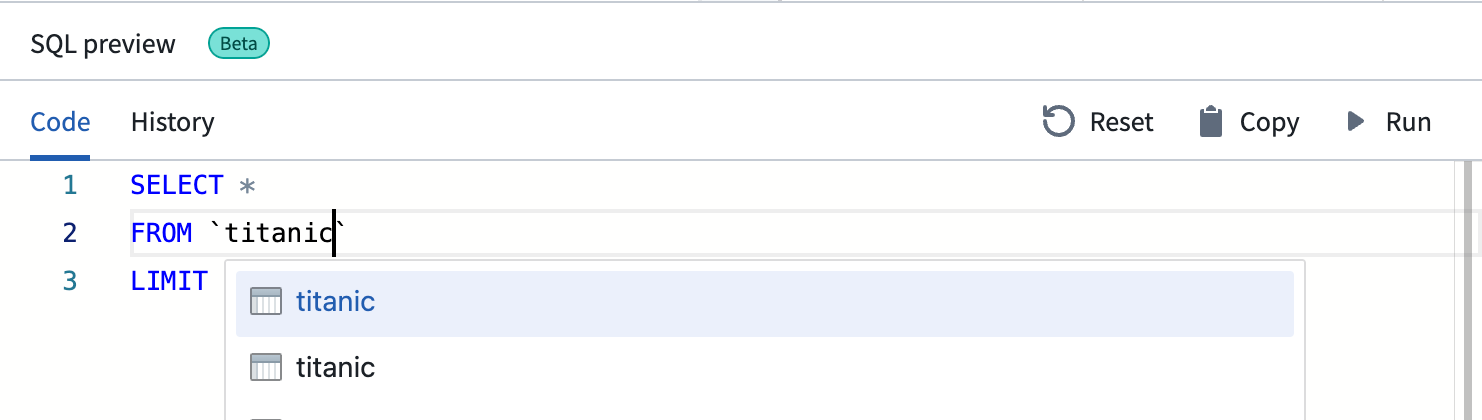
-
バッククォート「`」内にデータセット名を入力して、結合用のデータセットを検索できます。名前に一致するデータセットのドロップダウンリストが表示されます。
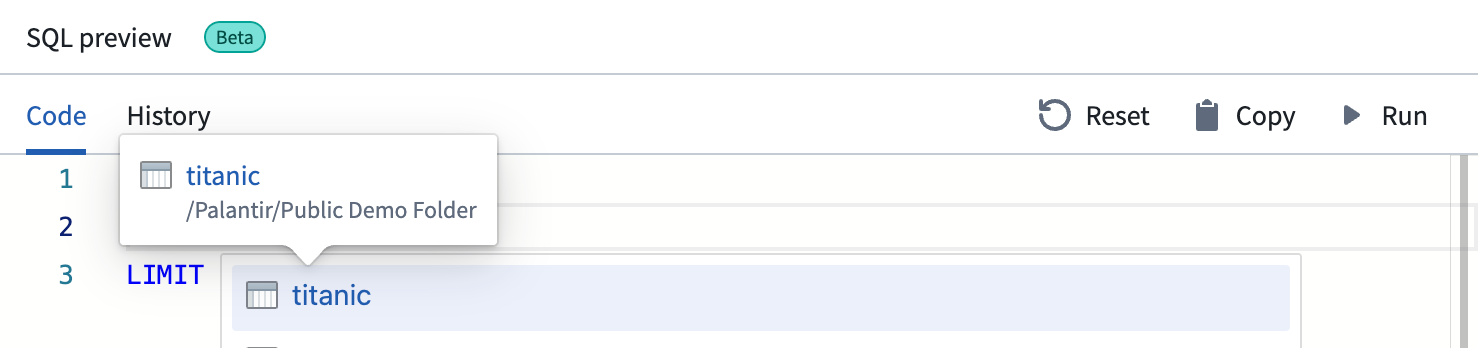
-
ドロップダウンリスト内の任意のデータセットにカーソルを合わせると、完全なリソース名とファイルパスが表示されます。
- 各クエリは、エディタ上の 実行 ボタンまたは
Cmd + Enter(macOS)またはCtrl + Enter(Windows)キーコマンドで実行します。1度に実行できるクエリは1つだけです。複数のクエリがある場合は、実行するクエリをハイライトしてください。
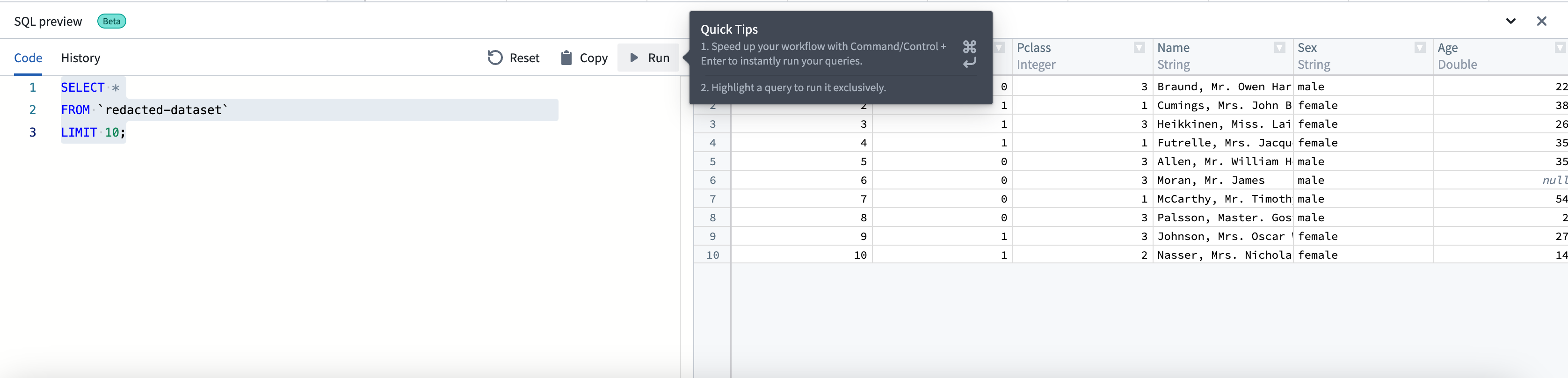
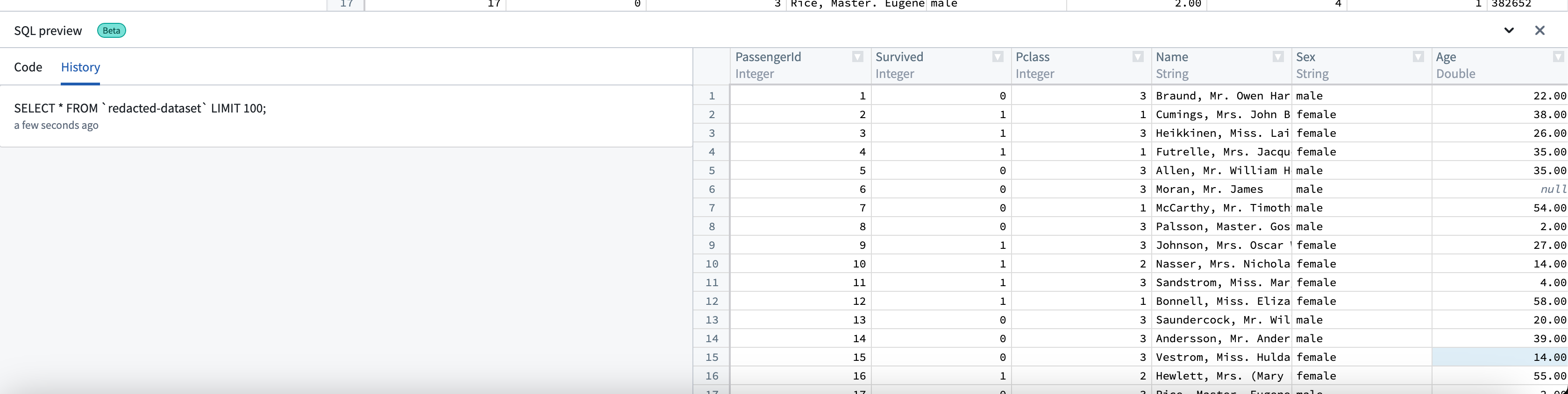
- 実行されたすべてのクエリは、自動的に 履歴 タブに保存されます。
互換性
SQL エンジンは Spark SQL 方言をサポートしています。Spark SQL では、テーブル名などの識別子はシングルクォートやダブルクォートではなく、バッククォート( ` )を使用して引用する必要があります。
たとえば:
Copied!1SELECT column_name FROM `table_name`;
-- table_name から column_name を選択するクエリ
Spark SQL 方言とその構文の詳細については、公式 Spark SQL ドキュメント ↗を参照してください。
クエリ実行の詳細と制限
- 各クエリはデータセット全体で実行され、Contour と同じコンピュートバックエンドを使用します。
- 各クエリは最大で 1,000 行のサンプルを返します。