注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
データセットの作成
データフロー図を使用してパイプライン内のどのデータセットが古いかを確認し、その後、Builds ヘルパーを使用してデータフローから直接ビルドを開始することができます。
データフローからトリガーされたビルドは常に、図で設定されているブランチ(フォールバックブランチを含む)に適用されます。
以下は、一般的なビルドのワークフローの例です:
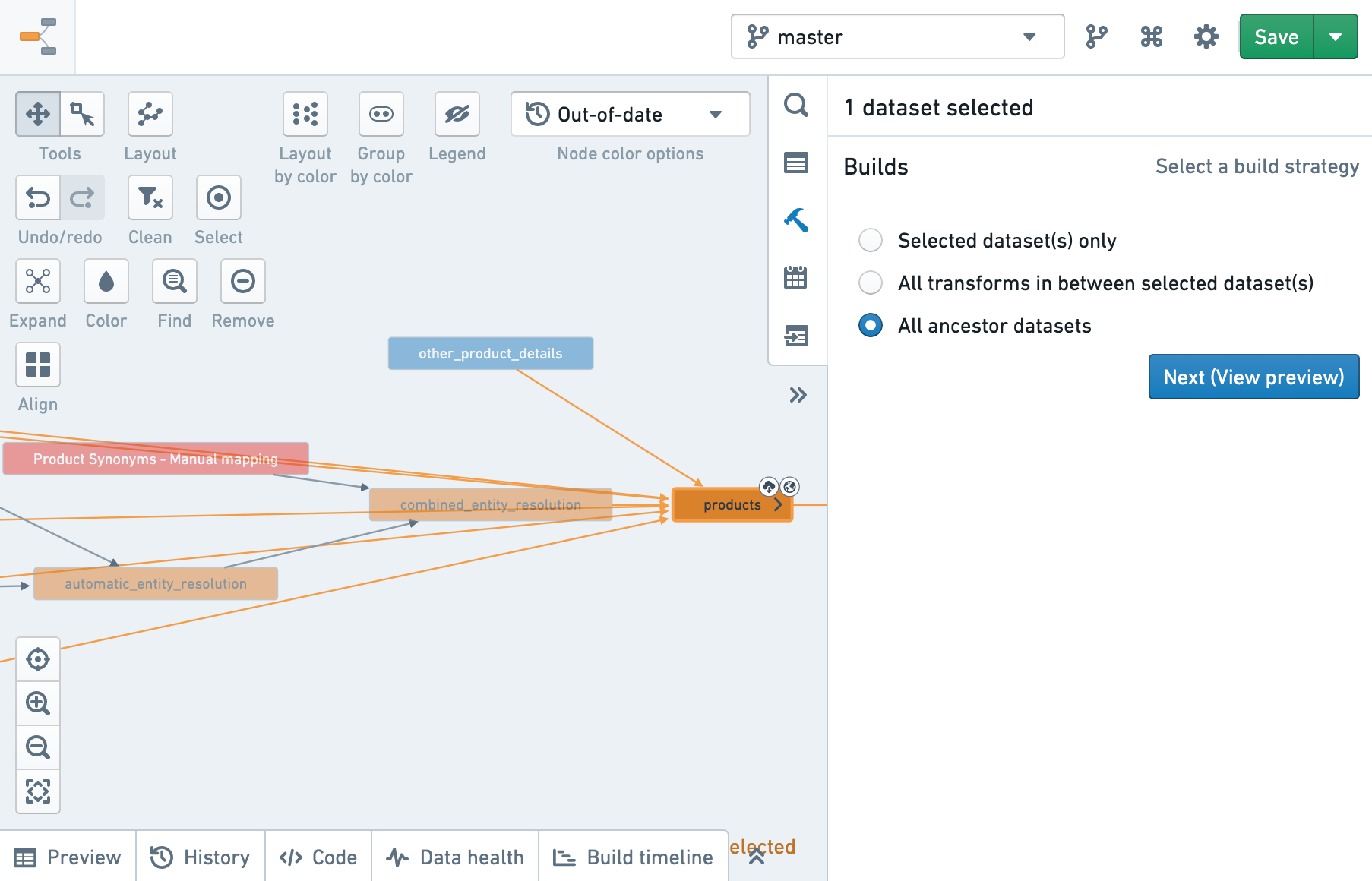
すべての先祖をビルドする
この戦略では、選択したデータセットとすべての先祖データセットをビルドし、選択したデータセットが完全に最新になるようにします。
デフォルトでは、古い先祖だけがビルドされますが、最新のデータセットの再ビルドを強制することも選択できます。強制的な再ビルドは、ビルド時間とリソースの観点から高価になる可能性があります。
- データセットをグラフに追加するか、保存されたスナップショットを開きます。
- ビルドしたいデータセットを選択します。
- Builds ヘルパーで、すべての先祖データセット を選択し、次へ をクリックします。
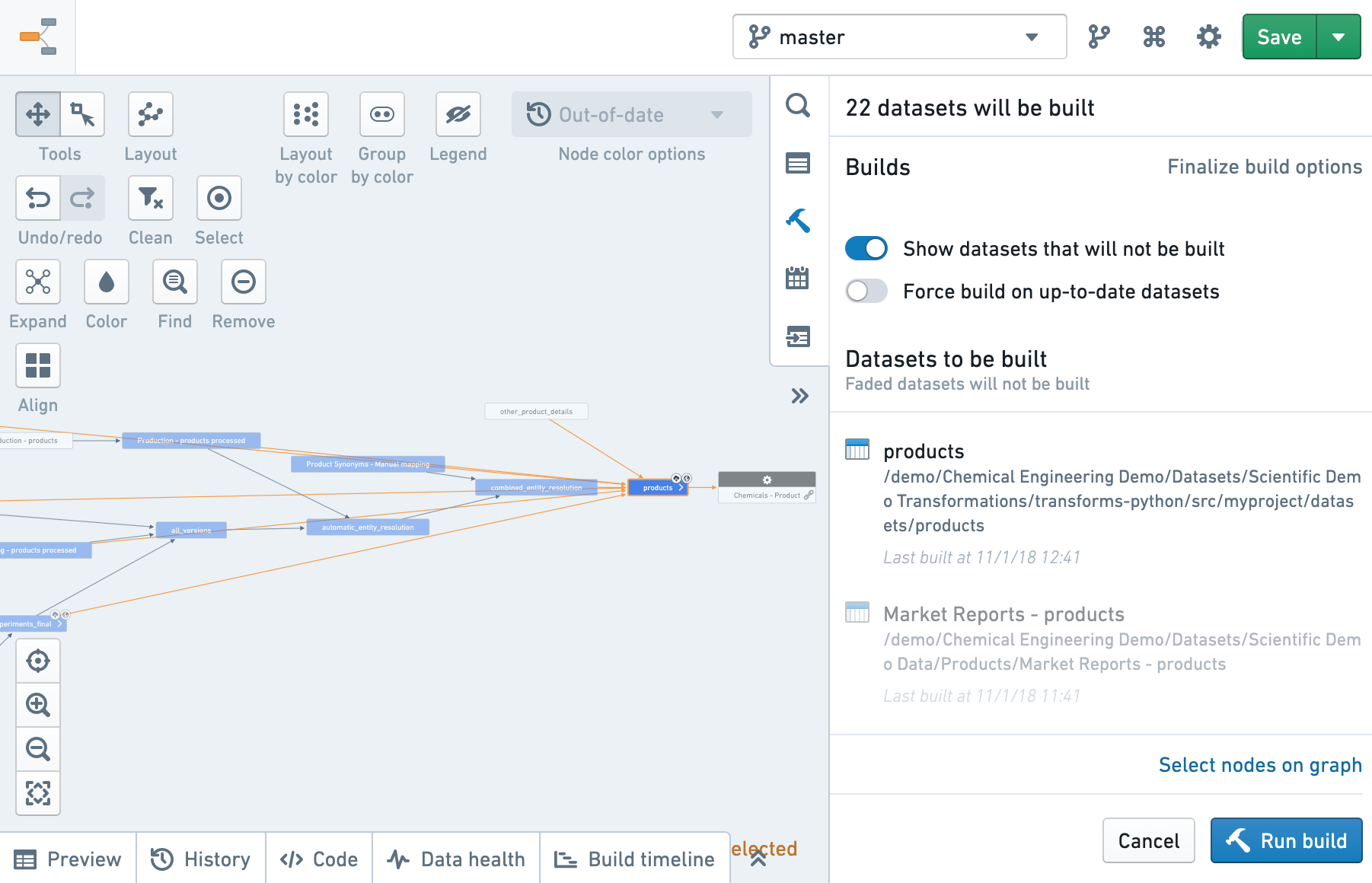
次へ をクリックしても、まだビルドはトリガーされません。ビルドされるデータセットのプレビューが表示されるだけです。
- 最新のデータセットの再ビルドを強制したい場合は、最新のデータセットで Force build をクリックします。
- ビルドされるデータセットのリストを確認した後、Run build をクリックしてビルドをトリガーします。
すべての古い先祖をビルドしたくない場合は、現在のビルドプレビューで Cancel をクリックし、選択したノードを変更する必要があります。ビルドプレビュー画面からは選択を変更することはできません。
選択したデータセット間のすべての変換
この戦略では、ビルドをパイプラインの一部にバインドすることができます。この戦略の一般的な使用例は、新しい生データが定期的にパイプラインに入り、新しいデータを反映させたい特定のデータセットがあるが、すべての古い先祖をビルドしたくない場合です。その後、データフローを使用して、興味のあるデータセットをより最新の状態にするためにどの他のデータセットをビルドする必要があるかを判断できます。
- 最終的にビルドしたいデータセットをグラフに追加します。
- 生データセットをグラフに追加します(または任意の上流データセット)。
- すべてのノードを選択します。
- Builds ヘルパーで、選択したデータセット間のすべての変換 の戦略を選択し、次へ をクリックします。
次へ をクリックしても、まだビルドはトリガーされません。選択したノードに基づいてビルドされるデータセットのプレビューが表示されるだけです。興味のあるデータセットを更新するために何がビルドされる必要があるのかを確認できます。すべてのデータセットをビルドしたくない場合もあります - たとえば、一日に一度だけビルドすべき非常に大きな派生データセットがある場合など - そのため、リストの下部で Add all to graph をクリックします。
選択したデータセット
この戦略では、ビルドしたい個々のデータセットを選択できます。データセット間に依存関係がある場合、ビルドは先祖がビルドされた後に子孫がビルドされるように、適切な順序で実行されます。
ビルドするデータセットを変更したい場合は、現在のビルドプレビューで Cancel をクリックし、選択したノードを変更し、新しいプレビューを入力する必要があります。ビルドプレビュー画面からはビルドの選択を変更することはできません。
ビルドされる最終的なデータセットのリストを確認した後、Run build をクリックしてビルドをトリガーします。