注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Streams
データセットと同様に、ストリームは Foundry にデータが到着してから、下流システムで処理されるまでのデータの表現です。ストリームはファイルシステムを利用した永続的な「ホットバッファー」と「コールドストレージ」によって保存された行のコレクションのラッパーです。Foundry ストリームを使用する利点は、ブランチング、バージョン管理、権限管理、スキーマ管理など、Foundry データセットと同じプリミティブを提供しながら、データの低遅延ビューも提供することです。
ストリームは本質的に表形式であり、したがって構造化されています。これらは Avro ↗ などのオープンソース形式で保存され、列自体に関するメタデータが付随します。このメタデータはスキーマとしてストリームと共に保存されます。
ストリームストレージ
ホットバッファー
レコードが Foundry ストリームに流れ込むと、ホットバッファーに保存され、ストリームの読み取りをサポートするすべての下流アプリケーションに低遅延で利用可能になります。このホットバッファーは、低遅延のトランスフォームと可用性を可能にするために重要です。データの取り込みには少なくとも一度のセマンティクスを提供し、プラットフォーム内のデータ処理にはオプションで正確に一度のセマンティクスを提供します。
コールドバッファー
Foundry ストリーム内のすべてのデータは、数分ごとにホットバッファーからコールドストレージに転送されます。このプロセスを「アーカイブ」と呼び、データを標準の Foundry データセットとして利用可能にします。これにより、ホットバッファーからリアルタイムにデータを処理しない場合でも、すべての Foundry アプリケーションがストリーミングデータを操作できます。Foundry ストリームのデータセットビューは、プラットフォーム内の標準の Foundry データセットとまったく同じように動作します。
ストリーム処理
ストリームからのデータ読み取り
低遅延が有効な Foundry 製品は、データのハイブリッドビューを読み取ることができます。ホットストレージとコールドストレージの両方のレイヤーからデータを読み取ることで、製品はデータの完全なビューを提供できます。このビューにより、製品はホットストレージにまだある低遅延のレコードと、コールドストレージに転送された古いデータにアクセスできます。このようにして、Foundry ストリームはホットストレージの低遅延とコールドストレージの低コストという両方の利点を享受できます。
トランザクション
標準の Foundry データセットとは異なり、ストリーム自体にはトランザクション境界がありません。代わりに、各行は独自のトランザクションとして扱われ、状態は行ごとに追跡されます。これにより、ストリームを細かく読み取ることができ、Foundry はバッチ処理やポーリングを必要とせずにプッシュベースのトランスフォームをサポートできます。
ストリームタイプ
ストリームのスループットニーズに基づいて、各ストリームのタイプを設定できます。これらのストリームタイプ設定は、上記のホットバッファーストレージにデータを書き込む方法に適用されます。ストリームメトリックがホットバッファーストレージに書き込む際にボトルネックが発生していることを示している場合にのみ、ストリームタイプの設定を変更する必要があります。レイテンシーとスループットはトレードオフであり、ストリームメトリックを確認した後に高スループット/圧縮ストリームタイプを設定する必要があります。 以下のストリーム設定をサポートしています:
- 高スループット: これは毎秒大量のデータを送信するストリームに最適です。このストリームタイプを有効にすると、スループットが高い代わりに、非ゼロのレイテンシーが発生する可能性があります。したがって、有効にする前にストリームメトリックを確認する必要があります。平均バッチサイズが最大バッチサイズと同じ場合や、ジョブが Kafka プロデューサーバッチの期限切れで失敗する場合は、高スループット設定を有効にする必要があるかもしれません。
- 圧縮: この設定を有効にすると、ホットストレージバッファーにデータを生成する際にメッセージバッチが圧縮されます。圧縮により、送信されるデータのサイズが縮小され、ネットワーク使用量とストレージが減少しますが、圧縮と解凍のために追加の CPU 使用量が発生します。ストリームに高頻度で繰り返される文字列が含まれており、非ゼロの遅延、予想より低いスループット、またはドロップされたレコードのようなネットワーク帯域幅の症状が発生している場合にのみ、このストリームタイプを有効にすることをお勧めします。
新しいストリームを作成する際に Define ページでストリームタイプを設定できます。また、既存のストリームのストリーム設定でストリームタイプを更新することもできます。これには、Foundry 内のストリーミングデータセットに移動し、ツールバーで Details を選択します。その後、Stream Settings に進みます。ここでストリームタイプを変更したり、圧縮を有効/無効にしたりできます。
パーティション
高スループットを維持するために、Foundry は入力ストリームを複数のパーティションに分割して並行処理を行います。ストリームを作成する際に、スループットスライダーを使用して作成するパーティションの数を制御できます。データはパーティション化されていますが、ストリームへのすべての読み取りおよび書き込みは、単一のパーティションがあるかのように動作します。この動作により、Foundry ストリームの消費者とプロデューサーにとって設計の透明性が提供されます。
特定のストリームの各追加パーティションは、ストリームが処理できる最大スループットを増加させます。各パーティションはスループットを約 5mb/s 増加させるのが良い目安です。
サポートされるフィールドタイプ
Foundry ストリームは、Foundry データセットと同じデータタイプをサポートしています。これには以下が含まれます:
BOOLEANBYTESHORTINTEGERLONGFLOATDOUBLEDECIMALSTRINGMAPARRAYSTRUCTBINARYDATETIMESTAMP
ストリーミングジョブ
すべてのストリーミングジョブは内部的にジョブグラフとして表されており、ユーザーのストリーミングパイプラインの視覚表現を提供します。データが処理されると、ジョブグラフの指示されたエッジに従ってデータシンクに到達するまでフローします。
チェックポイント
Foundry ストリーミングは、チェックポイントでアクティブな状態と現在の処理位置の両方を保存することで、データ処理中のフォールトトレランスを提供します。
チェックポイントはデータソースによって定期的に生成され、データソースからのデータと共にジョブグラフを通過します。 チェックポイントがジョブグラフのすべてのデータシンクに到達すると、そのチェックポイントがソースから送信されたすべての行もシンクに到達している必要があります。
チェックポイントにより、すでに見たデータを再処理することなく、最新のチェックポイントからストリーミングジョブを再開できます。チェックポイントはジョブグラフ内の各オペレーターの状態と、ストリーム内の最後に処理されたデータポイントを保存します。ストリーミングジョブの Job Details ページでは、ストリームの最後のいくつかのチェックポイントのステータス、サイズ、および期間をリアルタイムで確認できます。
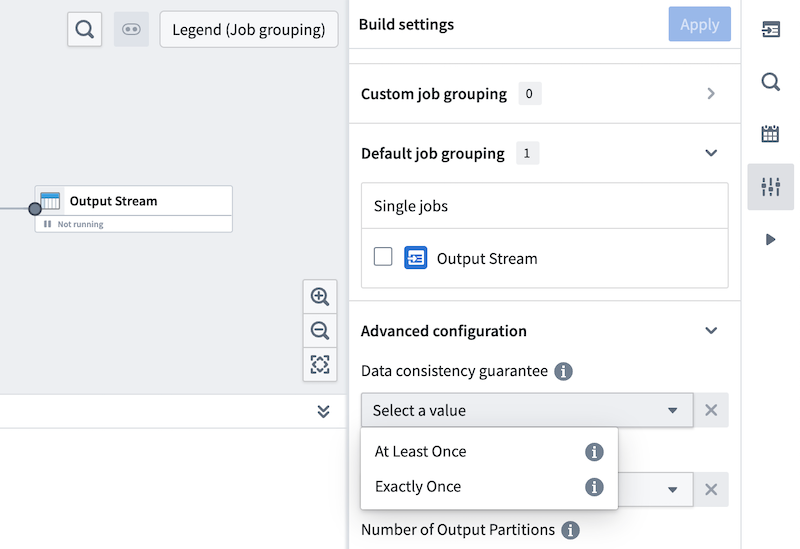
ストリーミングの一貫性保証
Foundry におけるストリーミングは、AT_LEAST_ONCE および EXACTLY_ONCE の2つの一貫性保証で動作します。
AT_LEAST_ONCE セマンティクス
AT_LEAST_ONCE セマンティクスは、メッセージが下流に少なくとも一度は配信されることを保証しますが、チェックポイントの失敗や再試行の場合にはメッセージが複数回配信されることがあります。これは重複が発生する可能性があることを意味し、消費アプリケーションは重複メッセージを処理または許容できるように設計する必要があります。
AT_LEAST_ONCE セマンティクスの利点
- メッセージが失われることなく、高いメッセージ耐久性を提供します。
EXACTLY_ONCEセマンティクスに比べて一般的に低遅延を提供し、記録の簿記に依存せずにメッセージを配信できます。
AT_LEAST_ONCE セマンティクスの欠点
- 下流の消費アプリケーションが重複メッセージを処理できる必要があります。
EXACTLY_ONCE セマンティクス
EXACTLY_ONCE セマンティクスは、各メッセージが正確に一度だけ配信および処理されることを保証し、重複や欠落メッセージがないことを保証します。これは最も強力なメッセージ配信保証であり、消費アプリケーションの設計を大幅に簡素化できます。
EXACTLY_ONCE セマンティクスの利点
- メッセージが失われることなく、高いメッセージ耐久性を提供します。
- 消費アプリケーションが重複メッセージを処理したり、冪等処理を実装する必要がなくなります。
- 各メッセージが正確に一度処理されるため、処理結果の一貫性を確保します。
EXACTLY_ONCE セマンティクスの欠点
AT_LEAST_ONCEセマンティクスに比べて一般的に高い遅延を引き起こし、メッセージが重複しないことを確保するための追加の調整と追跡が必要です。Foundry ストリーミングはチェックポイントを通じてこの問題を解決します。
レイテンシーのトレードオフ
AT_LEAST_ONCE と EXACTLY_ONCE セマンティクスの選択は、通常、レイテンシーと処理の複雑さのトレードオフを伴います。AT_LEAST_ONCE セマンティクスは、複雑な調整や追跡メカニズムを必要としないため、一般的に低遅延を提供しますが、重複を処理し、一貫性を維持する責任が消費アプリケーションにあります。EXACTLY_ONCE が有効な場合、各チェックポイントが完了した後にのみレコードが下流に表示されます(デフォルトは 2 秒)。特に、レコードはストリーミング速度で処理されていますが、「確定」するときにのみ下流に表示されます。
一方、EXACTLY_ONCE セマンティクスはより強力な保証を提供し、各メッセージが正確に一度処理されることを保証することで消費アプリケーションの設計を簡素化できます。しかし、この保証は、追加のオーバーヘッドが必要なため、レイテンシーが高くなるというコストがかかります。
Foundry のストリーミングソースは現在、抽出とエクスポートに対して AT_LEAST_ONCE セマンティクスのみをサポートしています。ストリーミングパイプラインは AT_LEAST_ONCE と EXACTLY_ONCE の両方のセマンティクスをサポートしており、これは Pipeline Builder の Build settings セクションで設定可能です。