注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ブランチング
ソフトウェア開発者は通常、コードベースでの作業を調整するためにバージョン管理システムを使用します。これにより、複数のエンジニアが同じコードに安全に貢献することが可能になります。
Foundry 内では、データについてソフトウェア開発者がコードを考えるのと同じように考えます:多くの人々が同じデータに変更を加えたり、それとやりとりしたりする方法が必要であり、それが他の誰かの作業に干渉しないようにする必要があります。ソフトウェア開発からベストプラクティスを取り入れ、それをデータパイプラインの作成に適用しました。これにより、バージョン管理システムの一般的な機能である ブランチング を活用しました。
概念的には、ブランチング は道路を分けて自分のブランチでデータを処理することを可能にします。そして、変更に満足したら、ブランチから主要な道路に変更をプッシュできます。
ブランチングワークフロー
Foundry でデータパイプラインのコードに変更を加えるためのブランチングワークフローの使用方法は以下の通りです:
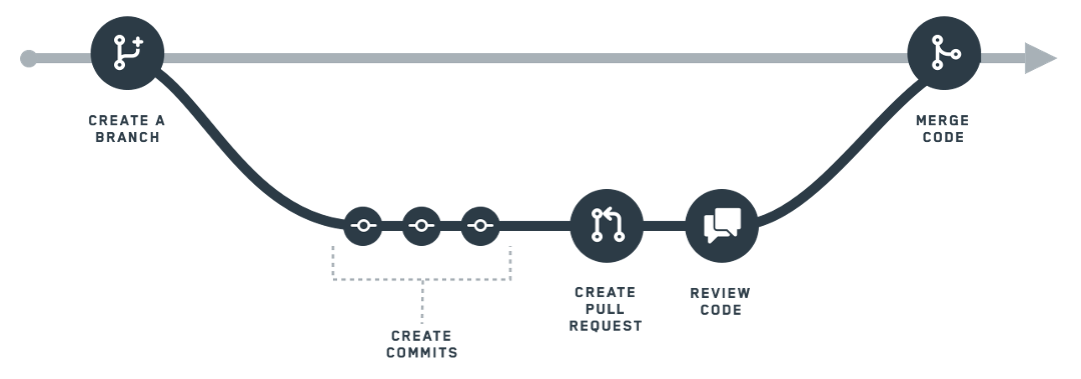
- ブランチを作成する。Foundry では、
masterブランチ は主要なデータパイプラインを指します。自分の変更を行いたい場合は、自分のブランチを作成します。これにより、masterブランチに影響を与えることなく、アイデアを試したり実験したりするための環境が作成されます。 - コミットを作成する。自分のブランチ内で、データ変換に変更を加えることができます。これらの変更(追加と削除を含む)は コミット と呼ばれ、自分のブランチで行ったすべての変更の明確な履歴が追跡されます。
- プルリクエストを作成する。単独での作業が終了したら、変更を master ブランチにプッシュしたくなるでしょう。このプロセスを開始するために、プルリクエスト を作成します。プルリクエストは、チームに対して
masterデータパイプラインの検証とレビューを希望する変更を行ったことを伝える信号です。 - コードをレビューする。プルリクエストを作成した後、チームはコミットをレビューする機会を持つことになります。プルリクエストのレビューを行うプロセスやチームは、各組織によって異なります。
Foundry のブランチングは、業界標準の Git のようなバージョン管理パラダイムを実装しています。そのため、Code Repositories アプリケーションは、ファイルごとに各個人のブランチでアクティブな開発者を持つように設計されています。他のユーザーがユーザーの personal ブランチ で作業している場合、ユーザーの変更は上書きされる可能性があります。これを避けるために、各人が別のブランチで作業することを強く推奨します。
このページの残りの部分では、Foundry でのブランチの動作に関する技術的な詳細を説明します。ブランチングを実際に使用する方法を学びたい場合は、Pipeline Builder または Code Repositories でシンプルなバッチパイプラインを作成するチュートリアルを参照してください。
ブランチングの技術的詳細
Foundry では、データのブランチングは、2つの異なるレベルでの機能を使用して実装されています:個々のデータセット 内のブランチング、および データセットの構築時 のブランチング。
データセットのブランチ
データセット のページで議論したように、データセットには トランザクション の形式でバージョン履歴が存在します。概念的には、データセットのブランチは Git のブランチに似ており、データセット、ブランチ、および トランザクション は Git の リポジトリ、ブランチ、および コミット に対応します。
Git のブランチと同様に、データセットのブランチはそのブランチの最新のトランザクションを指すポインタに過ぎません。その結果、ブランチはコミット時間で順序付けられたトランザクションの線形のシーケンスとして解釈することができます。ブランチ上のデータセットがトランザクションをコミットすることで変更されると、他のすべてのブランチのトランザクションとビューは変更されません。Git とは異なり、データセットのブランチをマージするサポートはありません。
各データセットのブランチには、親ブランチ が1つだけ存在します。ただし、それが ルートブランチ である場合を除きます。実際には、Foundry のほとんどのデータセットには master と呼ばれる単一のルートブランチが存在し、子ブランチはこの単一のルートブランチから作成されます。
データセットのブランチに関連するすべてのサポートされている操作は以下の通りです:
- 新しいブランチを作成する。親ブランチとトランザクションがない状態でルートブランチを作成することができます。
- 子ブランチを作成する。子ブランチは、別のブランチまたは任意のトランザクションから作成することができます。新しいブランチは親ブランチと同じトランザクションを指します。その後、親と子の両方のブランチでトランザクションを開始することができ、そのトランザクションのポインタはそれぞれ独立して移動します。
- ブランチで新しいトランザクションを開始する。トランザクションを開始し、ブランチのポインタを新しいトランザクションに移動します。
- ブランチを削除する。ブランチのポインタを削除しますが、ブランチ上のトランザクションはいずれも削除されません。以下の保証に関する親ブランチの注を参照してください。
データセットのブランチの保証
Foundry はデータセットのブランチに対して以下の保証を維持します:
- ブランチごとに1つの開いたトランザクション。各ブランチは最大で1つの開いた(つまり、開始されていてコミットまたは中止されていない)トランザクションを持つことができ、このトランザクションは常にブランチの最新のトランザクションです。1つのブランチを持つデータセットはしたがって最大で1つの開いたトランザクションを持つことができます。ブランチが開いたトランザクションを指している場合、このブランチから新しいブランチを作成することはできますが、トランザクションが閉じられるまで他のトランザクションを開始することはできません。
- すべてのブランチで、トランザクションは開始時間とコミット時間で順序付けられています。この保証は前述の制約の結果です。ただし、異なるブランチのトランザクションの時間順序については保証されません。
- すべての非ルートブランチは親ブランチを1つだけ持ちます。"中間" ブランチ(子ブランチを持つブランチ)が削除された場合、子ブランチは削除されたブランチの親(またはルートブランチであった場合は親なし)に再親指定されます。このプロセスではトランザクションは再配置されません。再親指定はブランチの系譜レコードを変更するだけです。
ビルド内のブランチ
データセットのブランチングは、データのバージョニング のための基礎的なセマンティクスを提供します。Foundry はデータセットのブランチングと Git のブランチングを組み合わせて、データエンジニアがデータパイプラインの変更を安全に試すことができるように、ロジックとデータの両方でのブランチングをサポートします。
Git のロジックのブランチとデータセットのデータのブランチを結びつけることは、Foundry の ビルド システムを通じて行われます。すべてのビルドはユーザーが指定したブランチで実行され、ビルド内のジョブはそのブランチのデータセットのみを変更します。その結果、ビルド内のブランチは、異なるユーザーの変更を互いに分離する方法を提供します。
Foundry のビルドは、ブランチに関与する2つの主要な機能を実行します。これらについては以下で説明します:
- 最初に、ビルドはジョブの仕様、または JobSpecs を適切なブランチから収集して ビルドグラフをコンパイルします 。
- 次に、ビルドはユーザー定義のビルドブランチと一連の フォールバックブランチ に関して ジョブの入力と出力を解決します 。
ジョブグラフのコンパイル
Foundry の Code Repository のブランチでデータ変換を作成すると、コードをコミットすると、そのチェックインはビルドシステムの適切なブランチに JobSpecs を公開します。そのブランチでビルドを実行すると、ビルドはユーザーのブランチの JobSpecs とその依存関係をトラバースして、どのロジックを実行するべきかを決定します。
ビルドは通常、ビルドブランチに JobSpec が設定されていない場合に、どのブランチから JobSpecs を取得するかを管理する ブランチフォールバック を指定します。たとえば、develop --> master のフォールバックチェーンで develop 上でビルドを実行すると、特定の出力データセットに対して公開された JobSpec がない場合、JobSpec は代わりに master ブランチから読み取られます。
データセットのアイコンの色は、JobSpecs とブランチングに関する情報を提供します。データセットのアイコンが灰色の場合、これは master ブランチに JobSpec が存在しないことを示します。データセットのアイコンが青色の場合、JobSpec は master ブランチで定義されています。
入力と出力の解決
ビルド内の JobSpecs によって 出力 として指定されたすべてのデータセットに対して、ビルドブランチでトランザクションが開始されます。このブランチがデータセットに存在しない場合、それはフォールバックチェーンの最初のブランチから作成されるか、フォールバックブランチが存在しない場合はルートブランチとして作成されます。ジョブの入力は可能な限りビルドブランチから読み取られますが、それ以外の場合はフォールバックチェーンの最初の既存のブランチを使用します。
例:ブランチでのビルド
ビルドのブランチがどのように動作するかを理解するために、以下のワークフローの例を見てみましょう:
- データセット A、B、C が
masterブランチに存在するとします。 - データエンジニアが Code Repository で
featureという名前のブランチを作成します。これにより、基礎となる Git リポジトリにブランチが作成されます。 - データエンジニアは、データセット B と C を生成するコードを変更します。データエンジニアがコードをコミットすると、リポジトリのチェックインは
featureブランチの両データセットに JobSpecs を公開します。 - データエンジニアは
featureブランチでビルドを開始します。featureブランチは Git リポジトリのmasterブランチから作成されたため、このビルドのフォールバックチェーンはfeature --> masterです。ステップ (3) で公開された JobSpecs が読み取られ、ユーザーのコードに対応する2つのジョブが開始されます。データセット B と C のfeatureブランチでトランザクションが開始されます。2つのジョブは次のように順番に実行されます:- ジョブ 1:データセット A の
masterブランチがブランチフォールバックのための入力として使用されます。計算により新しいデータが生成され、これが現在開いているトランザクションのデータセット B に書き込まれます。トランザクションはコミットされます。 - ジョブ 2:次に、このジョブが開始されます。データセット B の
featureブランチが入力として使用されます。計算により新しいデータが生成され、これが現在開いているトランザクションのデータセット C に書き込まれます。トランザクションはコミットされます。
- ジョブ 1:データセット A の
- 最終的に、ビルド内のすべてのジョブが成功したため、ビルドは成功します。
コードを変更し、コミットし、ビルドを実行した後、データエンジニアはデータセット B と C の feature ブランチに新しいデータを生成しました。データセット A はこのプロセスに全く影響を受けていないことに注意してください。また、データセット B と C の master ブランチも変更されていません。
ビルドブランチの保証
Foundry のビルドは、ブランチに対して以下の保証を提供します:
- ビルド解決は、指定されたブランチフォールバックシーケンスが関与するデータセットのブランチ系譜と互換性がある場合にのみ成功します。
- ビルドはビルドブランチ以外のデータセットのブランチを決して変更しません。
- ビルドは入力データセットのブランチを作成しません。