注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
バッチ同期を設定する
バッチ同期機能により、外部システムからFoundryのデータセットにデータを同期できます。バッチ同期は最も広くサポートされている機能で、ほぼすべてのコネクタで利用可能です。バッチ同期により、スキーマを持つ表形式データとスキーマを持たない生ファイルの両方を同期することができます。
バッチ同期を作成すると、同期されたデータが書き込まれる新しいFoundryデータセットも作成されます。同期が設定されると、手動で実行するか、スケジュールを設定して外部システムからデータを読み取り、出力データセットに書き込むビルドをトリガーすることができます。
以下の手順に従ってバッチ同期を設定してください。この設定ガイドでは、バッチ同期機能をサポートするソース接続を設定していることを前提としています。
新しいバッチ同期を作成する
まず、Data Connectionアプリケーションでソース接続に移動し、概要ページからNew batch syncを選択します。これは新しく設定されたソースである場合、以下のように利用可能な機能が表示され、バッチ同期オプションの横にあるCreateを選択します。
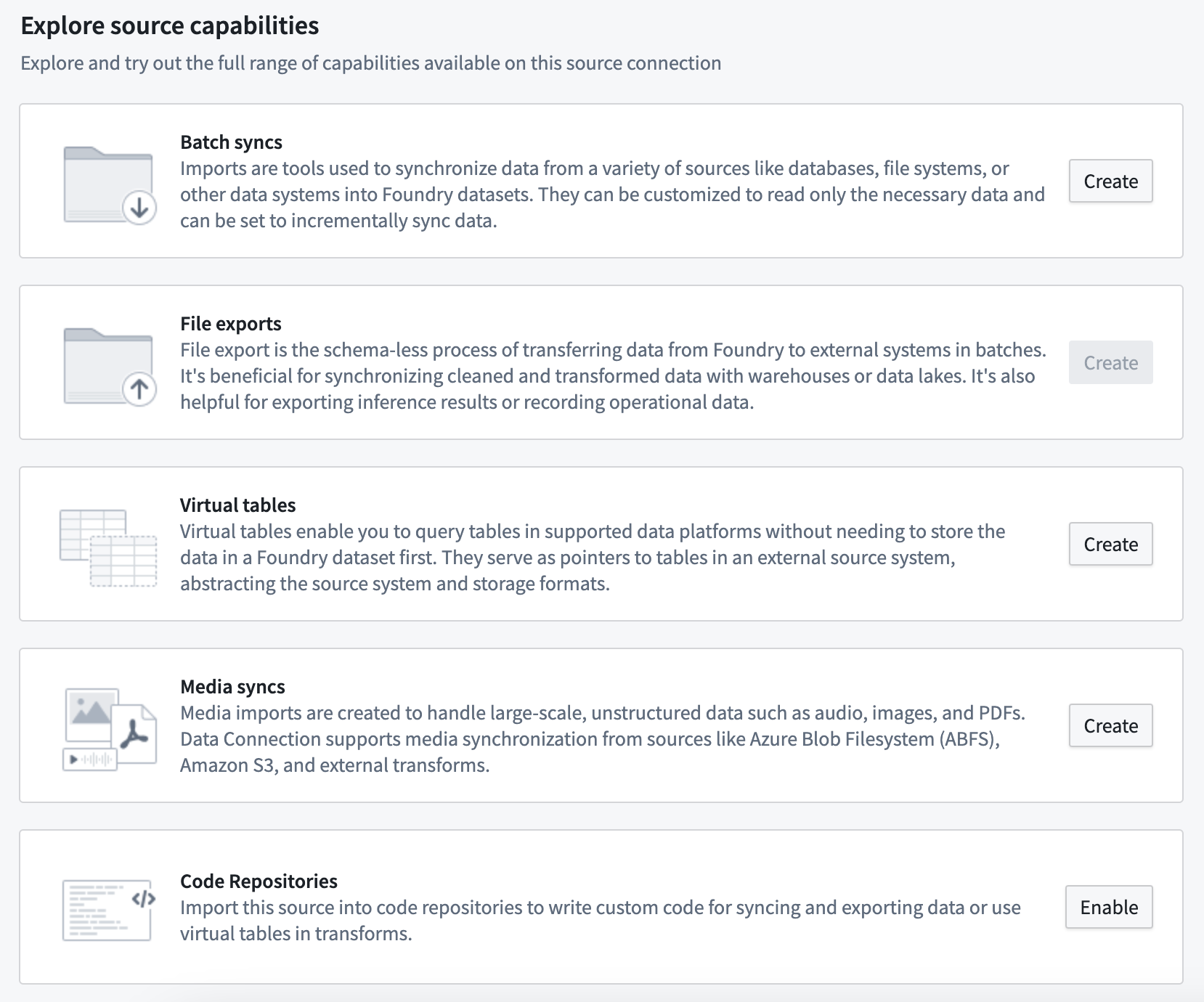
コネクタがソース探索をサポートしている場合、Explore and create syncsを選択してデータソースを探索し、探索ビューから直接同期の作成を開始することもできます。詳細についてはソース探索ドキュメントを参照してください。
出力場所を指定する
出力場所は、同期されたデータセットが作成される場所を定義し、プロジェクトレベルの権限に基づいて、誰が結果データにアクセスできるかを決定します。ソースに対してデフォルトの出力フォルダーが指定されている場合がありますが、必要に応じて各同期ごとに上書きすることができます。
同期データセットをコネクタと一緒に保存することをお勧めします。これにより、特定のコネクタからのすべてのデータに一律に権限を設定するパターンが可能になり、データパイプラインを作成する際に便利です。データパイプラインの推奨プロジェクト構造についてさらに学びましょう。
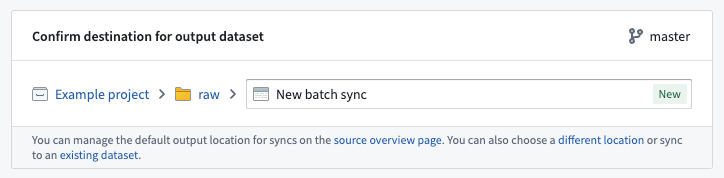
既存のデータセットへの同期はサポートされていますが、選択されたデータセット内の既存データが上書きされる可能性があるため、推奨されません。
バッチ同期を構成する
出力先と同じページで、バッチ同期を構成するためのさまざまな設定が表示されます。
ソースに応じて、異なるオプションが利用可能です。最も一般的なバッチ同期の種類は次の2つです:
ほとんどのシステムはファイルまたはテーブルバッチ同期のいずれかをサポートしていますが、両方をサポートするシステムもあります。
ファイルバッチ同期の例
以下の例は、各ビルドでSNAPSHOT更新を行うS3からのファイルバッチ同期の設定を示しています。オプションでサブディレクトリやフィルターを指定して、出力データセットに同期されるファイルのセットを絞り込むことができます。例ではサブディレクトリやフィルターを指定していないため、ソース接続を設定したときに選択したルートディレクトリの下にあるすべてのファイルが同期されます。
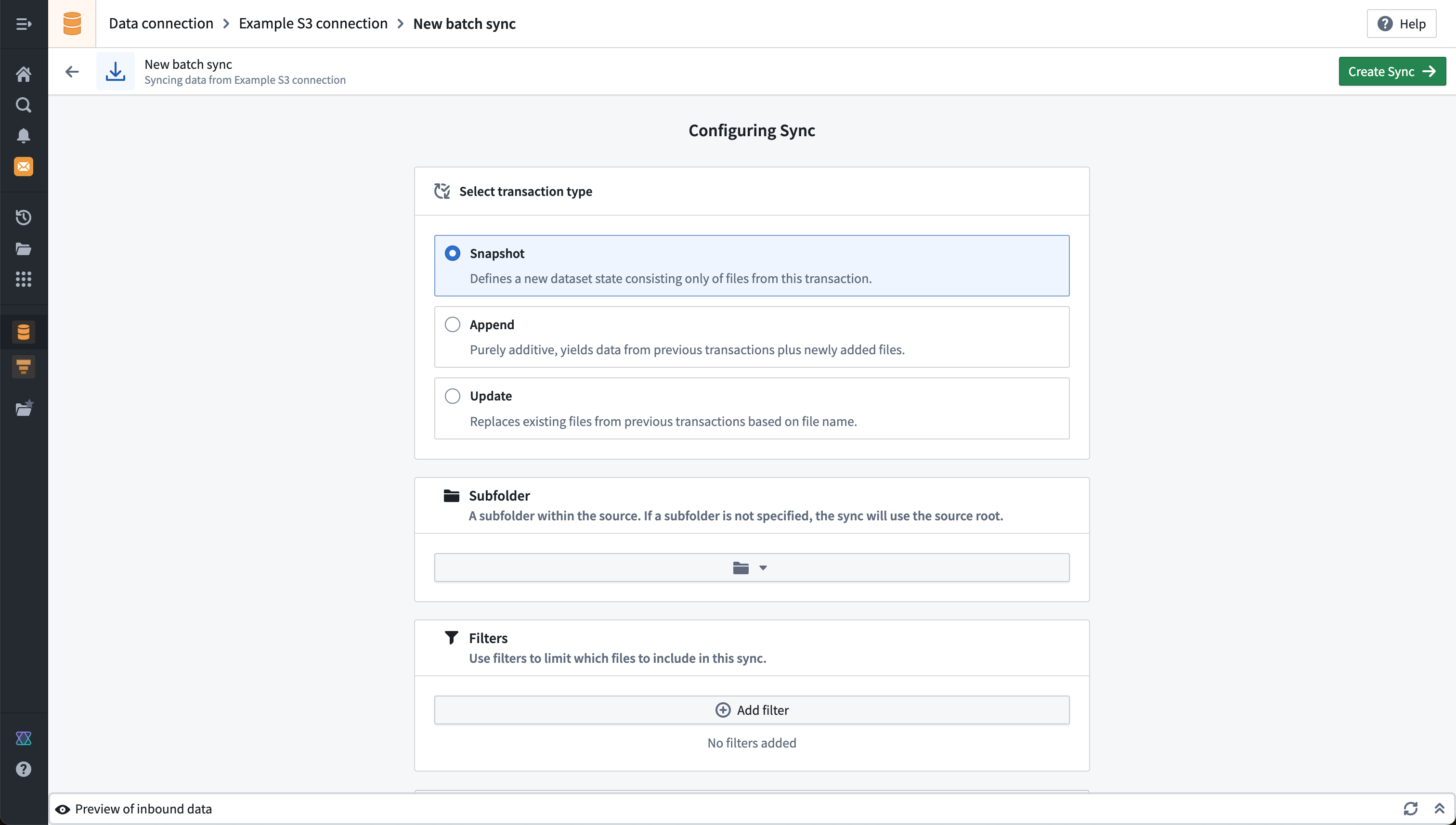
ファイルバッチ同期の追加設定については、ファイルバッチ同期のリファレンスドキュメントに記載されています。利用可能なフィルターの詳細なドキュメントも含まれています。
テーブルバッチ同期の例
この例は、Microsoft SQL Serverからのテーブルバッチ同期の設定を示しています。クエリにより、対象システムから取得されるデータが定義されます。この場合、インクリメンタルバッチ同期設定も有効になっており、単調増加する列に基づいてデータをインクリメンタルに更新することができます。
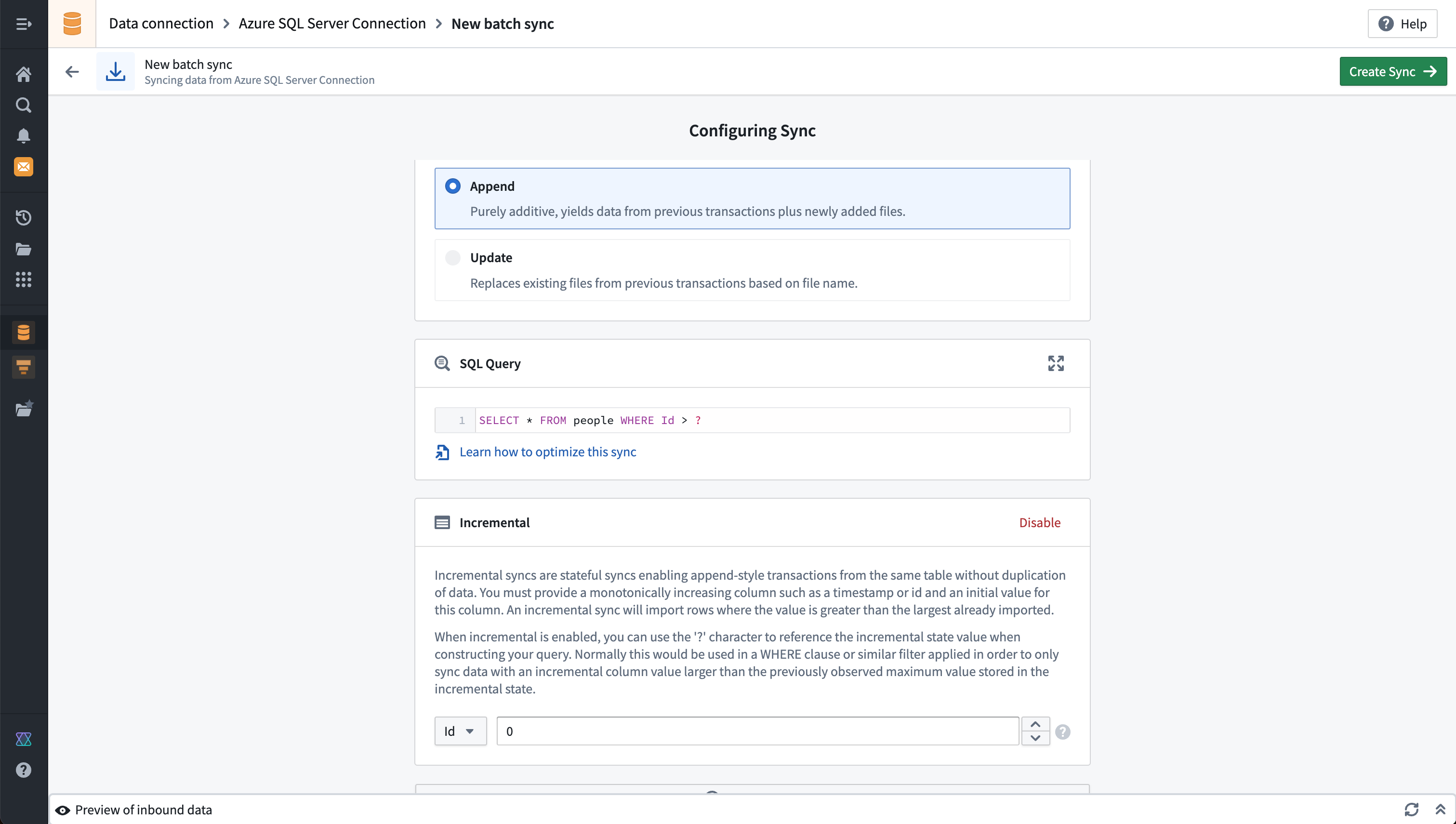
Explore sourceタブでSQLストアドプロシージャを視覚化することはできませんが、SQL Queryフィールドで対応するプロシージャの後にEXECコマンドを実行することで、SQLストアドプロシージャを実行できます。
追加オプション
ほとんどのバッチ同期で利用可能な他のオプションが多数あり、コネクタによって異なる場合があります。バッチ同期の一般的な設定オプションのいくつかの例を以下に示します:
- トランザクションタイプは、取り込まれたデータが以前に取り込まれたデータを上書きするか(
SNAPSHOT)、インクリメンタルに追加されるか(APPEND)を決定します。インクリメンタル同期についてさらに学びましょう。 - スケジュールを使用して、Foundryのビルドシステムを使用してデータをどのくらいの頻度で同期するかを設定できます。新しく作成された同期のスケジュールを設定することをお勧めします。スケジュールのベストプラクティスについてさらに学びましょう。
- ビルドポリシーにより、設定されたスケジュールに関係なく、同期が許可されるタイミングを制限できます。
- 最大継続時間により、指定された時間制限を超えて実行される同期を自動的にキャンセルできます。すべての同期は約48時間以上実行されると自動的にキャンセルされます。
テーブルバッチ同期のみ利用可能なオプションは以下の通りです:
- タイムゾーンなしのタイムスタンプ設定により、Foundryに同期するときにタイムゾーンなしのタイムスタンプデータをどのように処理するかをカスタマイズできます。デフォルトでは、タイムゾーンなしのタイムスタンプは文字列として同期されますが、手動で指定されたタイムゾーンを持つ
timestampとして同期するか、longとして同期することもできます。 - スキーマの変更を許可。この設定により、外部システムでスキーマが変更された場合にバッチ同期を実行しないようにすることができます。デフォルトでは、スキーマの変更は許可されていません。
同期出力のプレビュー
続行する前に、設定した内容に基づいて同期されるデータのプレビューを実行できます。これを使用して、同期が期待どおりに設定されていることを確認してください。
- ファイルバッチ同期の場合、プレビューにはファイルのリストが表示されます。
- テーブルバッチ同期の場合、プレビューには選択されたテーブルの結果が最初の20行に限定されて表示されます。
以下に、csv_filesというサブフォルダーへのフィルターを使用したS3ファイルバッチ同期のプレビュー例を示します:
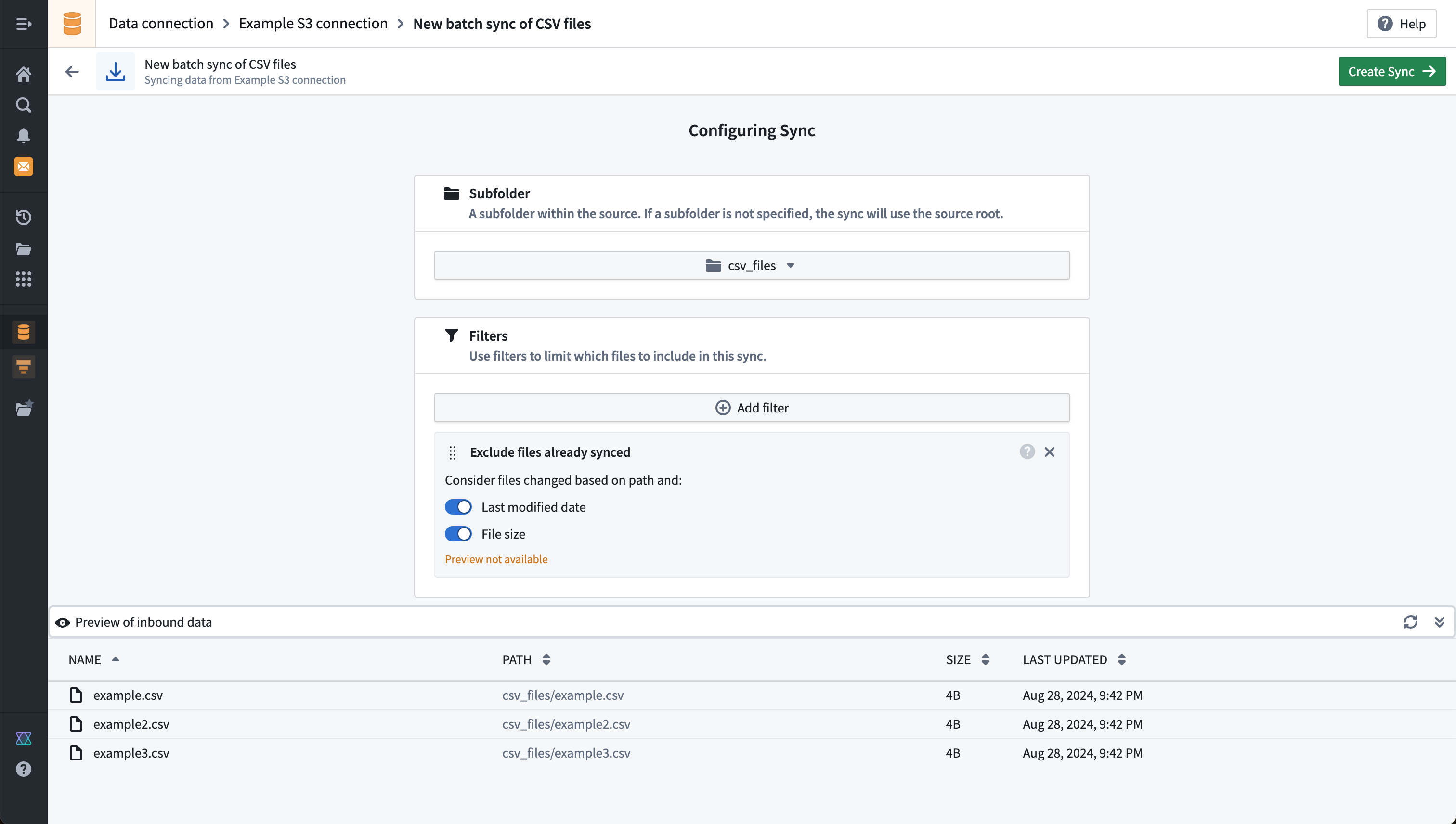
上記の例では、Exclude files already syncedフィルターを使用する際のPreview not available警告が表示されています。これは、このフィルターがプレビュー結果に反映されず、同期がスケジュールまたは手動で実行されたときにのみ適用されるためです。
バッチ同期をビルドまたはスケジュールする
バッチ同期を保存した後、実行するタイミングと方法を選択できます。
概要ページに表示されるRunボタンを使用してバッチ同期を手動で実行します。

バッチ同期を定期的に実行するようにビルドスケジュールを設定します:
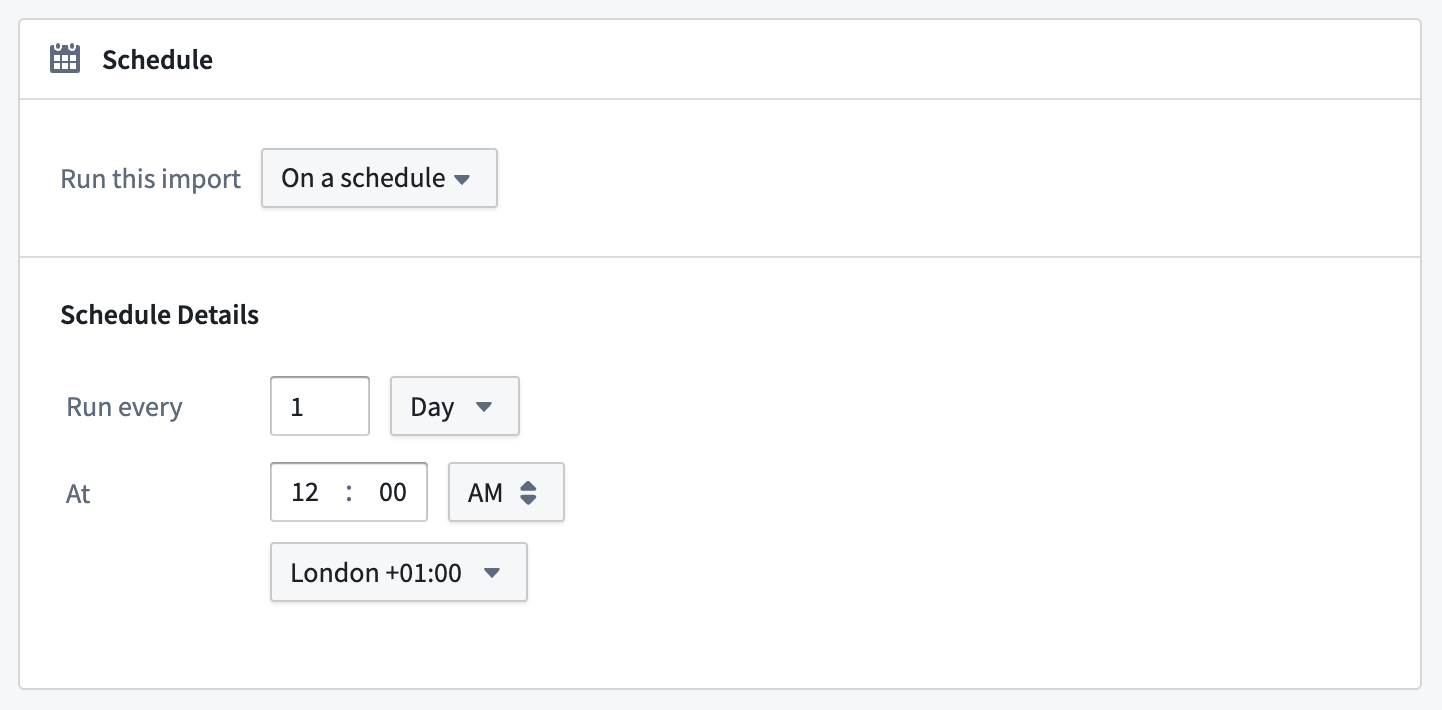
Data Lineageアプリケーションを使用して、複数の同期に対してスケジュールを設定します。
同じバッチ同期に対してData ConnectionとData Lineageの両方からスケジュールを設定するべきではありません。Data Lineageから設定されたスケジュールは、常にForce buildオプションを使用してData Connectionの同期をビルドする必要があります。
次のステップ
この設定ガイドでは、コネクタからFoundryデータセットにデータを取り込むためのバッチ同期の作成方法を学びました。以下のその他のリソースもご覧ください:
- 変更データキャプチャ同期、エクスポート、およびメディアセット同期など、他の機能についてさらに学びましょう。
- Foundryでデータセットをトランスフォームする方法を学ぶために、パイプラインの構築を参照してください。
- 各コネクタタイプの構成オプションについて学ぶために、ソースタイプリファレンスを参照してください。