注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ストリーミング同期の設定
同期は、特定のデータをソースから読み取り、それをFoundryに取り込むタスクです。例えば、複数のテーブルを含むリレーショナルデータベースソースを持っている場合、特定のテーブルをFoundryに取り込むために同期を設定するかもしれません。
ストリーミング同期は非ストリーミング(すなわち、バッチまたは増分)同期と似ていますが、いくつかの違いがあります。主な違いは、バッチや増分の同期が定期的に実行されるのに対し、ストリーミング同期は可能な限り低いレイテンシでFoundryにデータを引き込むために一貫して実行されます。
以下に、同期を作成するために必要な手順を説明します:
このチュートリアルでは、同期を設定するためにKafkaソースを使用します。
パート 1. データの定義
まず、Foundryに同期したいデータを決定します。Data Connectionでストリーミングソースを選択し、右上の角にある利用可能なアクションを選択します:
- 同期の探索と作成: ソースタイプがソース探索をサポートしている場合、このオプションが表示され、同期を作成しながらデータソースを探索できます。
- 同期の作成: ソースタイプがソース探索をサポートしていない場合にこのオプションが表示されます。

同期の探索と作成
ソースタイプがソース探索をサポートしている場合、Data Connectionのソースを探索ページに移動し、同期可能なデータが表示されます。探索ビューインターフェースは、使用しているソースタイプによって異なります。例えば、Kafkaソース探索では、Kafkaブローカー上に存在するトピック ↗を見ることができ、それらのトピックに含まれるデータをプレビューすることができます。
Kafkaの探索ビューからは、ページの左側のリストにある既存のトピックを見ることができます。
トピックを選択すると、そのトピックからのデータのサンプルをプレビューすることができます。
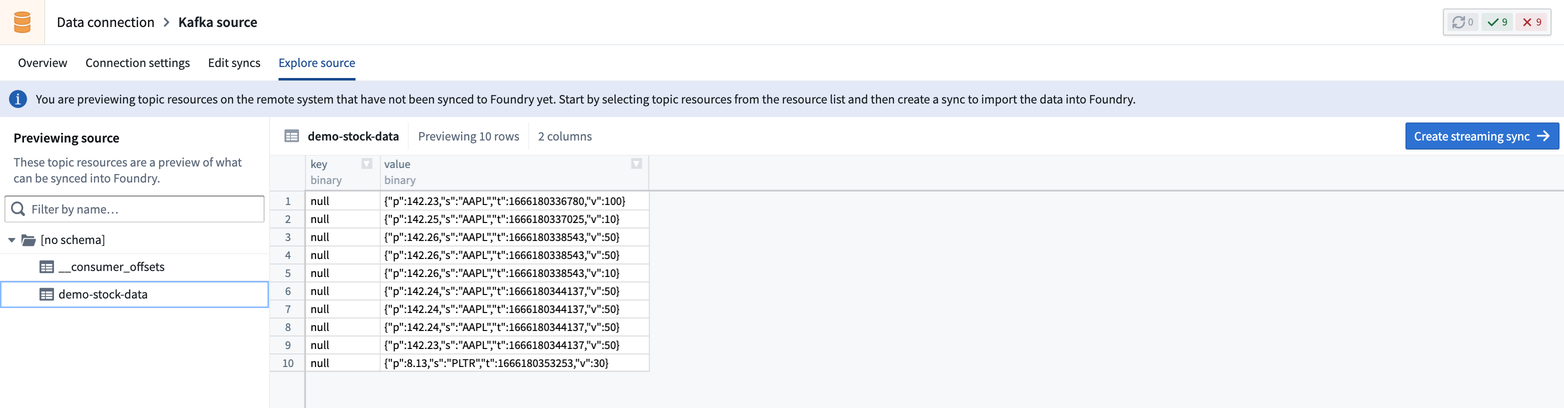
パート 2. 同期の場所の定義
次に、同期したデータセットをFoundryのどこに保存するかを決定する必要があります。データセットの場所は、プロジェクトレベルの権限に基づいて、結果のデータセットにアクセスできるユーザーを決定します。
同期したデータセットをそのソースと同じプロジェクトの隣に保存することをお勧めします。これにより、同じ権限を持つことができます。データパイプラインを作成する際には、データセットとソースの権限が一致していると便利です。データパイプライン用の推奨プロジェクト構造については、こちらをご覧ください。
同期の場所を選んだら、右上の角にあるストリーミング同期の作成をクリックします。
パート 3. ストリーミング同期の設定
次に、Data Connectionの同期作成ページに移動します。ここでソース特有の設定とコアストリーミング設定を同期に定義できます。
- ソース特有: 設定ページの上部に位置し、これらのオプションはソースタイプに依存し、接続している特定のソースに渡されるパラメーターを設定します。
- コアストリーミング: ソース特有の設定の下に位置し、これらのオプションはすべてのストリーミング同期に共通です。コア設定には、スループット、スキーマ、同期先が含まれます。
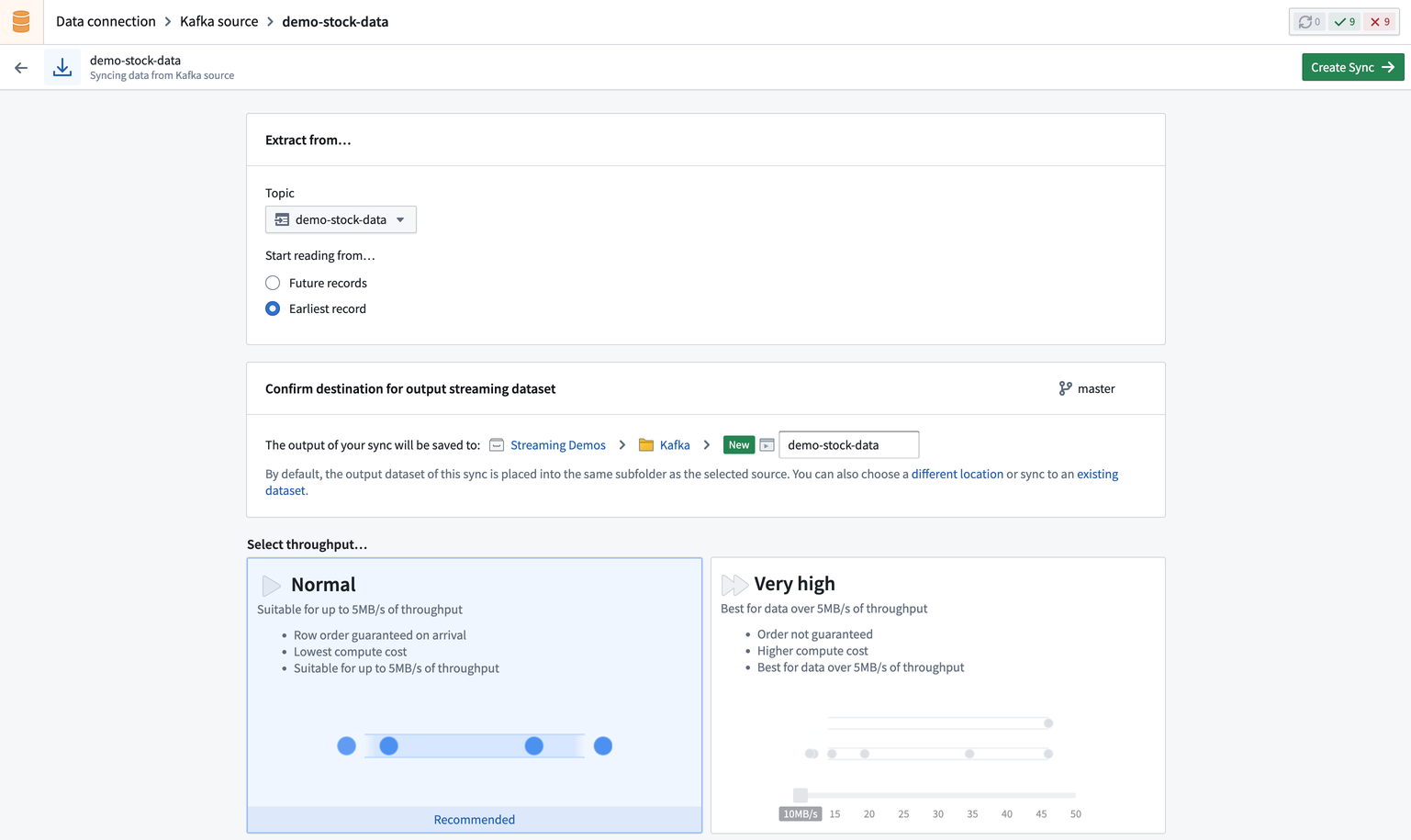
次に、ストリームのスループットを選択します。スループットは、作成されるパーティションの数を決定します。より多くのパーティションを選択するとスループットが高くなります。Normalスループットを選択すると、そのストリームの上限は5 MB/sまでとなります。
次に、入力データのスキーマを指定します。デフォルトではこれはソースから推測されますが、必要に応じて上書きすることができます。
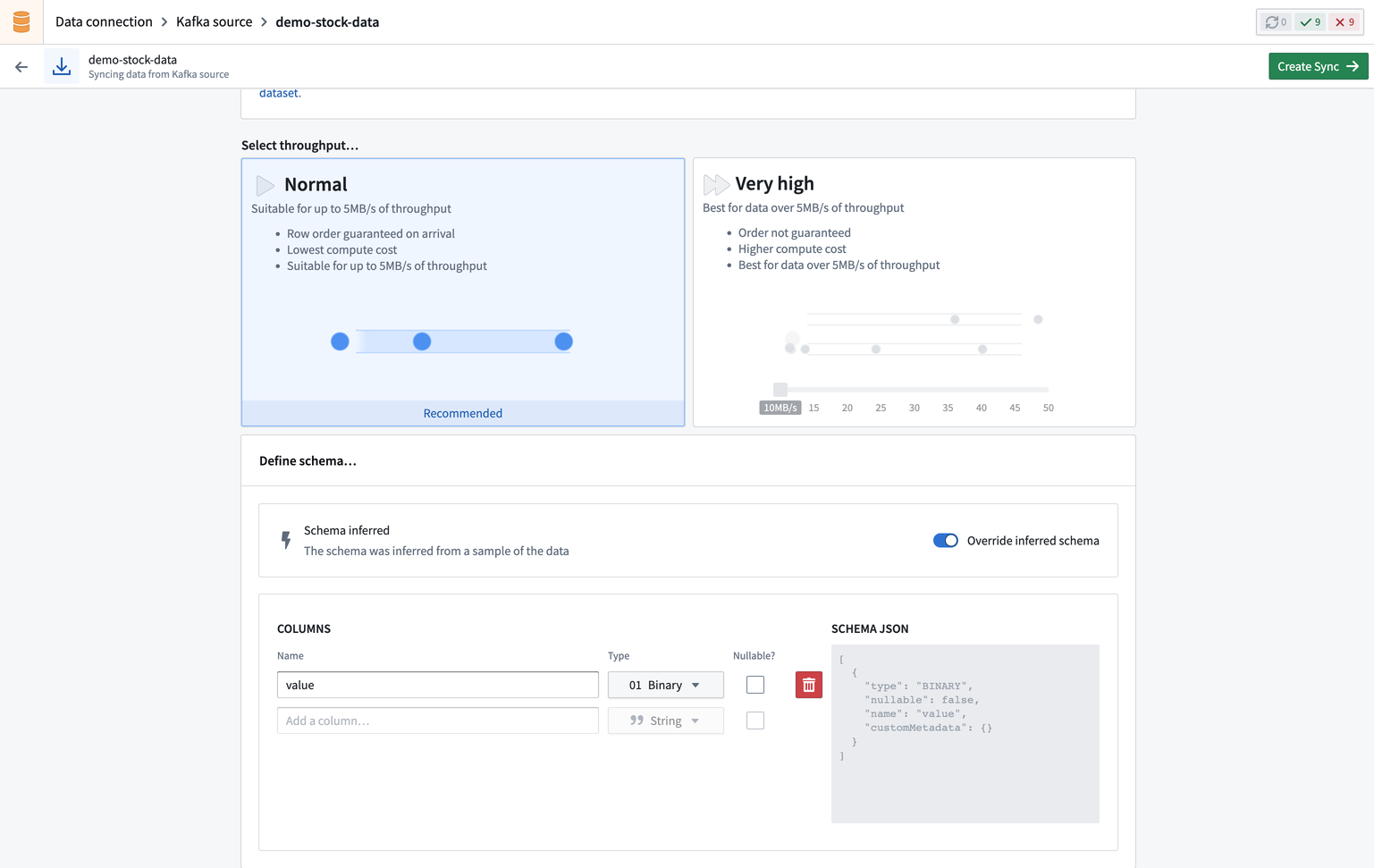
同期を設定したら、右上の同期の作成を選択します。
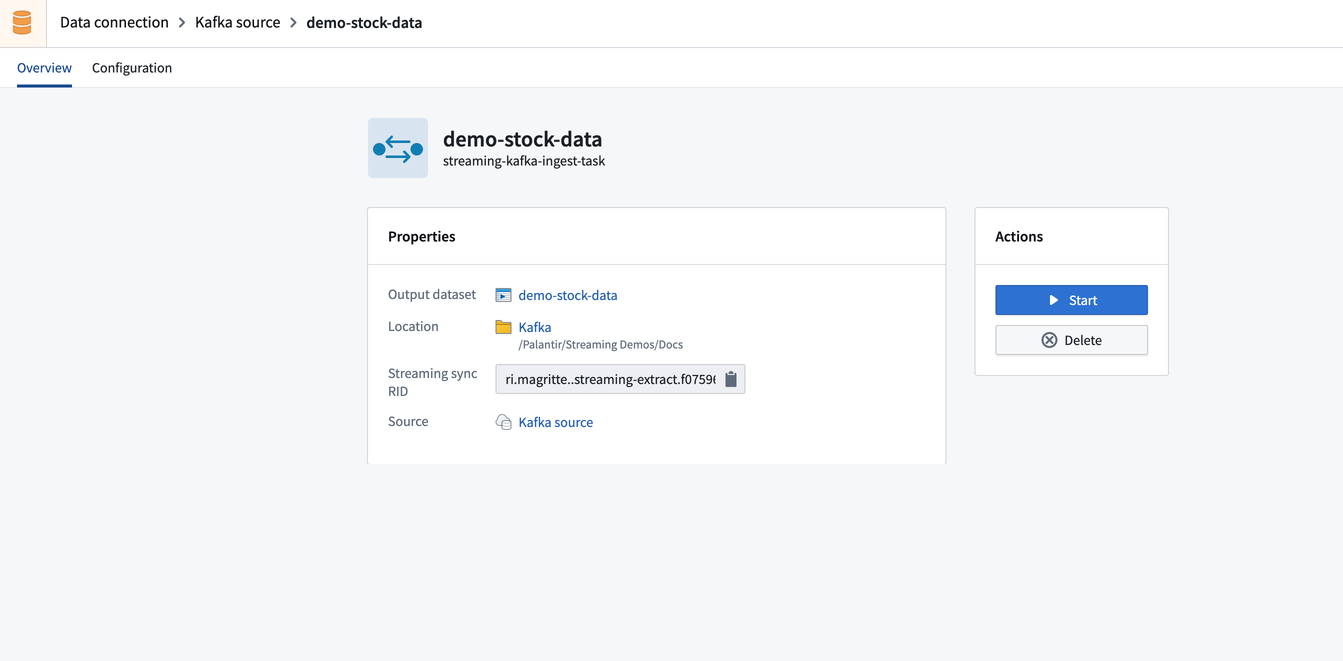
同期が作成されたら、概要タブに移動します。
パート 4. 同期の実行
これで、同期を実行する準備が整いました。概要タブを選択して、新しい同期の概要、出力データセット、場所、利用可能なアクションを表示します。
開始をクリックして、外部ストリームからのデータ同期を開始します。
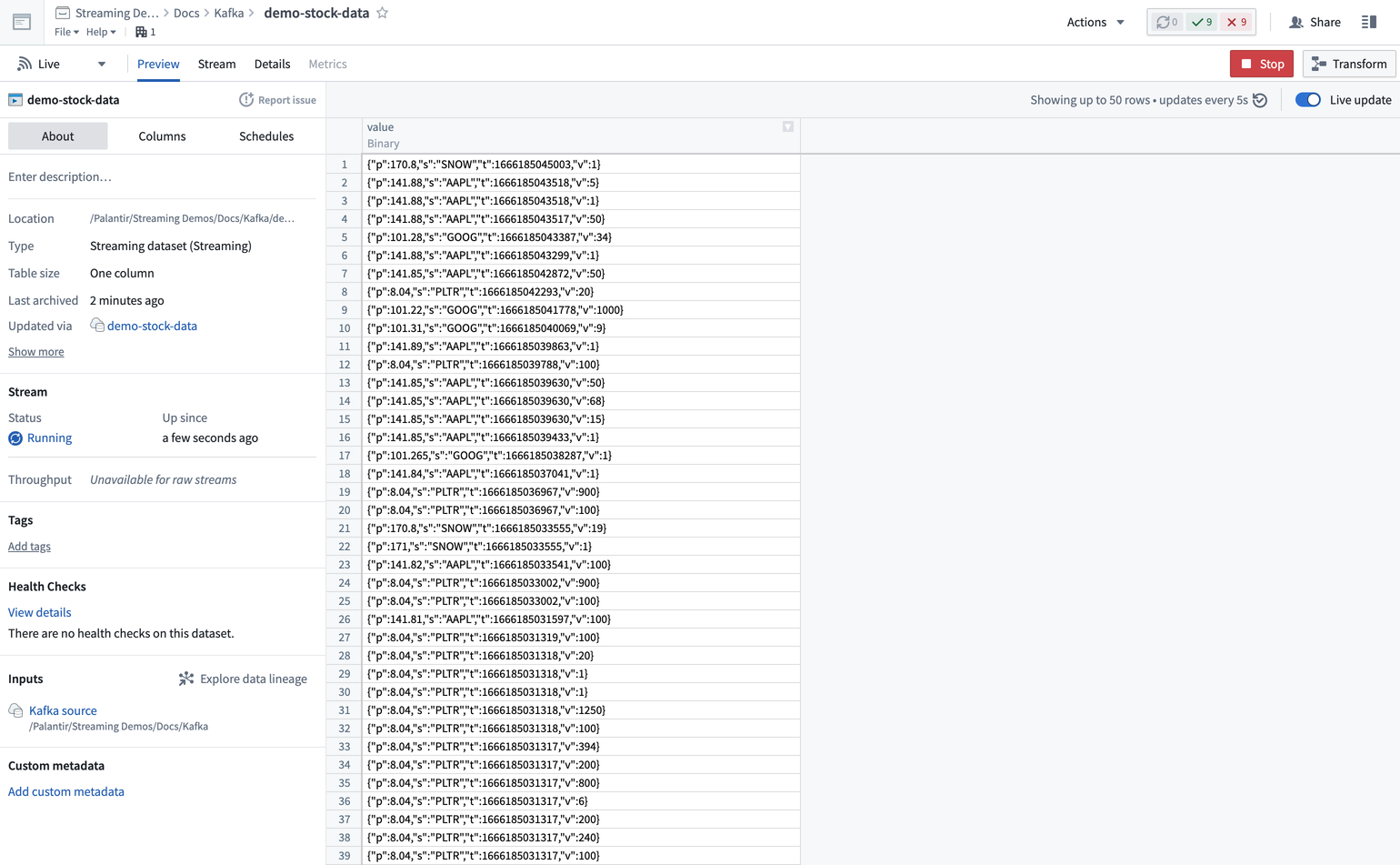
ストリームデータを表示するには、同期の作成中に設定したストリームに移動し、ストリームプレビューページを表示します。ストリームでKafkaトピックからレコードが流れてくるのが見えるはずです。
次のステップ
同期の実行に成功したら、失敗するストリームのデバッグ、プッシュベースの取り込みによるストリームへのデータプッシュ、またはストリームとオントロジーの統合の方法を学んでみてください。