注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
エージェントのセットアップ
エージェントは、ユーザーの組織ネットワーク内にインストールされ、Foundry の Data Connection インターフェースから管理されるダウンロード可能なプログラムです。エージェントは、組織ネットワーク内のさまざまなデータソースに接続する機能を持っています。これらは、エージェントワーカーランタイムによってそのソースからデータを読み取り、制限付きアクセス トークンで Foundry に安全に取り込むために使用され、また、エージェントプロキシランタイムによってこれらのソースへのネットワーク接続を提供します。
このガイドでは、エージェントを作成するための手順を説明します。まず、以下を完了してください。
- Palantir にログイン後、左側の サイドバーを使用して Data Connection に移動します。
- エージェント タブを選択します。
- 右上の 新しいエージェント を選択します。
新しいエージェントを作成するオプションが表示されない場合は、必要な役割を持っていない可能性があります。Control Panel でエージェント作成ワークフローの管理についてさらに詳しく学びます。
エージェントが稼働し、Foundry にソースを接続したい場合、エージェントがデータを安全に読み取るために使用できるソースシステムの資格情報を取得する必要があります。組織のネットワーク設定によっては、エージェントがソースシステムに到達できるようにネットワーク設定を構成する必要がある場合もあります。
以下のセクションを確認して、エージェントの設定を開始してください。
セットアップ
エージェントホストの作成
エージェントプログラムを正常に実行するには、適切な環境(理想的には Linux をオペレーティングシステムとして使用する環境)にホストする必要があります。
Foundry エージェントに最も一般的に使用されるホスティング方法は、クラウド環境で Linux 仮想マシン(VM)をプロビジョニングすることです。たとえば、AWS、Azure、または GCP で Linux VM をプロビジョニングすることもできますが、組織に属する Linux サーバーにエージェントをホストすることもできます。Foundry エージェントを Windows にホストすることも可能ですが、Palantir はこれを推奨しておらず、Linux 環境にホストできない場合にのみ使用するべきです。
エージェント用に使用するホストは、単一の Foundry エージェントを実行するためだけに使用され、他のサービスやプロセスと共存させないようにしてください。 同じマシンで複数の Foundry エージェントを実行することはサポートされていません。
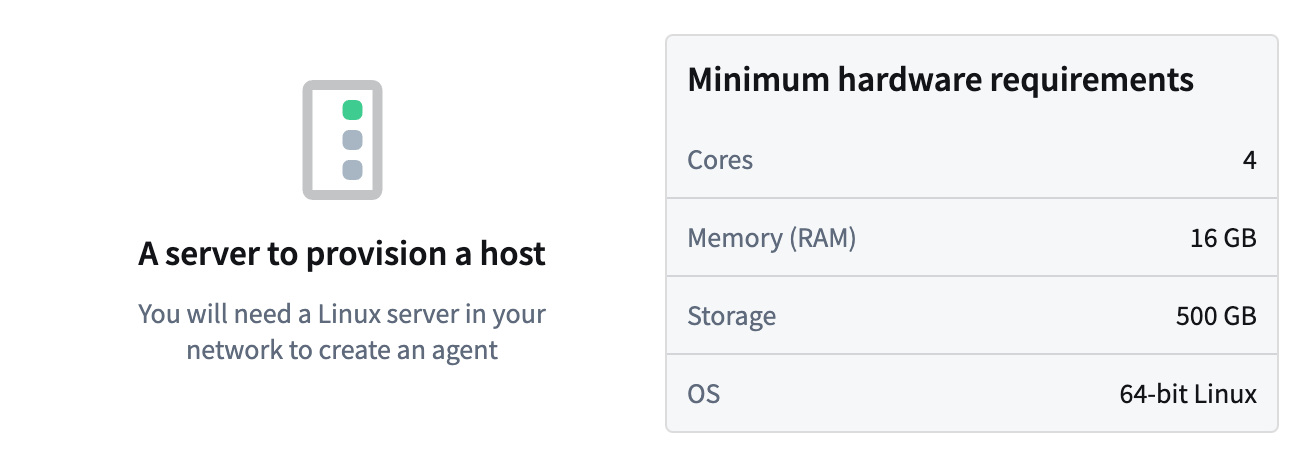
エージェントをホストする適切な場所を確保したら、次のステップは、ホストが Foundry エージェントが動作するために必要なハードウェアおよび OS 要件を満たしていることを確認することです。これらの要件は以下の通りです。
-
64ビット Linux または他の Linux オペレーティングシステム(推奨 RHEL 8、Ubuntu 22.04、または同等)
-
エージェントは Linux/x86-64 用にコンパイルされた独自の JDK 上で実行されます。必要に応じて(たとえば、AWS Graviton や他の ARM ベースの CPU で実行する場合)、
service/bin/launcher-static.yml内のjavaHomeの値を変更することで、別の JDK 上でエージェントを実行することも可能です。一般的には、別の JDK 上でエージェントを実行することは推奨されておらず、将来的にサポートされない可能性があります。
-
-
4 CPU コア
-
16 GB RAM
-
500GB /opt にマウントされた空きディスクスペース(できれば SSD)
推奨制限は以下の通りです:
- コアファイルサイズ: ハードおよびソフトリミット 0
- オープンファイル: ハードおよびソフトリミット 262144
- 実行プロセス: ハードおよびソフトリミット 65536
- スタックサイズ: ハードおよびソフトリミット 32768
- 最大ロックメモリ: ハードおよびソフトリミット "無制限"
エージェントのネットワークアクセスの構成
エージェントがユーザーの組織ネットワーク内のホストにインストールされていると仮定すると、エージェントはインターネットを介してアクセスされる Foundry VPC(仮想プライベートクラウド)に到達するためにネットワークイグレスを必要とします。ネットワークがデフォルトでイグレスを許可していない場合、エージェント(および/またはそのホスト)からユーザーの Foundry インスタンスへのアウトバウンド接続を許可するために、ファイアウォールの開放や プロキシの構成 などの特定の構成が必要になる場合があります。
最初のステップとして、サーバーから Foundry へのイグレスが可能であることを確認します。プラットフォームのエージェントセットアップワークフローの サーバー設定 タブからドメイン名とポートをコピーして、ネットワークアクセスを適切に構成します。

ホストが Foundry VPC と通信できることを確認するために、VM 上で次のコマンドを実行します。
Copied!1 2# curlを使って特定のドメイン名にHTTPSリクエストを送信します。成功すれば"pass"、失敗すれば"fail"を出力します。 curl -s https://<あなたのドメイン名>/magritte-coordinator/api/ping > /dev/null && echo pass || echo fail
すべてが期待通りに機能していれば、出力として pass を見るはずです。
ただし、ping は Foundry VPC への接続テストが不完全を示しています。
エージェントホストのセキュリティ強化
ユーザーがネットワーク内の限定された一連の目的地にのみ接続できるようにするには、エージェントホストのファイアウォールを設定して、望ましい目的地へのトラフィック以外はすべてブロックすることをお勧めします。ただし、エージェントホストが Palantir と通信できるようにすることを忘れないでください。
自動再起動の設定
自動再起動が設定されていない場合、エージェントがクラッシュしたり、エージェントホストが再起動したりするたびに中断が発生します。
エージェントマネージャーがクラッシュした場合の自動再起動を設定するには、VM またはマシンの端末上のエージェントマネージャーのサービスディレクトリから、コマンド ${AGENT_MANAGER_DIR}/service/bin/auto_restart.sh を cron ジョブを作成する権限を持つユーザーとして実行します。
自動再起動を停止する必要がある場合 (たとえば、エージェントマネージャーをアップグレードするときなど) は、${AGENT_MANAGER_DIR}/service/bin/auto_restart.sh clear を実行することで停止できます。
プロジェクトにエージェントリソースを保存する
次に、新しいエージェントに名前を付け、それを保存するプロジェクトを選択する必要があります。Foundry では、エージェントは リソース と見なされ、プロジェクトに保存されて、高度に設定可能な権限を許可します。
エージェントを保存する新しいプロジェクトを作成することをお勧めします。
Foundry の権限は広範なトピックです。詳しく知りたい場合は、以下のリソースを参照してください:
エージェントのダウンロードとインストール
エージェント用のハードウェアを手配したら、次のステップは、Foundry からエージェントソフトウェアをダウンロードし、ホストにインストールすることです。パッケージをダウンロードし、解凍し、エージェントを起動するためのプラットフォーム内ガイドに記載されている手順に従ってください。
プロキシを設定する必要がある場合は、 プロキシ設定のドキュメンテーション に詳細が記載されています。
エージェントが正常に起動したら、エージェントが更新され続けることを確認するために、自動アップグレードの設定 の手順に従ってください。
次のステップ
エージェントの作成、インストール、起動が完了したら、Data Connection のエージェントページに移動し、エージェントの権限、健康状態、接続性の設定と監視 を行います。
エージェントの設定が完了したら、ユーザーの組織のデータソースとエージェントを接続するために、ソースの設定 に進むことができます。