注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
JDBC 同期の最適化
このガイドでは、JDBC 同期の速度と信頼性を向上させるためのヒントを提供します。
同期がすでに正常に動作している場合、以下の説明に従って行動する必要はありません。新しい同期を設定している場合や、同期に時間がかかりすぎる場合、または信頼性がない場合は、このガイドに従うことをお勧めします。
JDBC 同期を高速化するための主な方法は 2 つあります。まず、同期をインクリメンタルにしてから、インクリメンタル同期が不十分な場合にのみ SQL クエリを並列化に進むことをお勧めします。
インクリメンタル同期
デフォルトでは、バッチ同期では対象テーブルからすべての一致する行が同期されます。それに対して、インクリメンタル同期は、最新の同期に関する状態を維持し、対象から新しい一致する行のみを取り込むために使用できます。これにより、行数の多いテーブルの同期パフォーマンスが劇的に向上します。インクリメンタル同期は、同期されたデータセットにAPPEND トランザクションとしてデータを追加することで機能します。
以下は、インクリメンタルバッチ同期の設定例です。
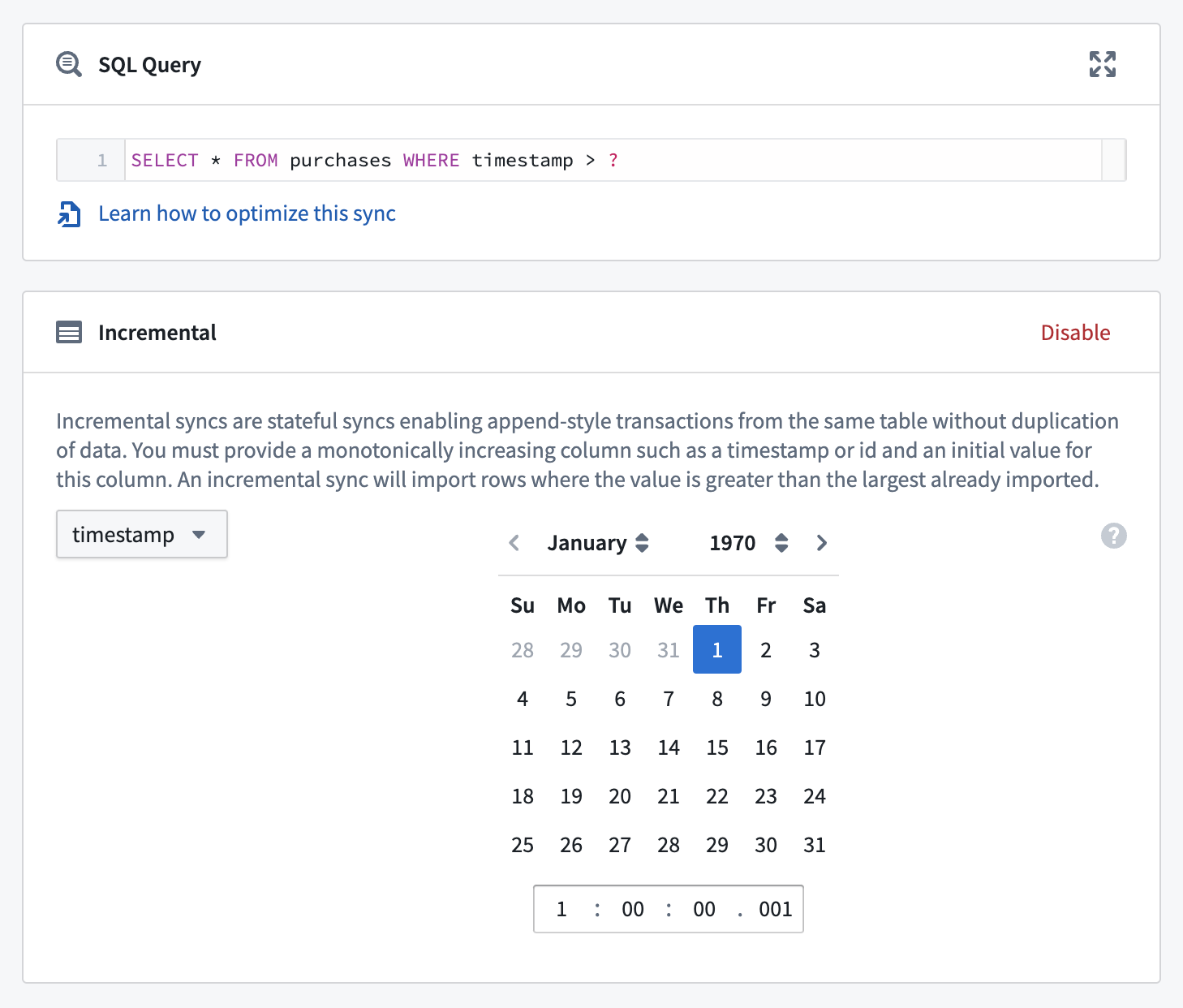
インクリメンタルバッチ同期を設定するには、以下の手順を実行してください。
-
変換したい同期の設定ページに移動し、プレビューが正常に動作していることを確認します。
-
トランザクションタイプを
APPENDに設定します。これは、前回の同期からの行を上書きしないようにするために必要です。 -
インクリメンタルボックスで有効を選択します。同期に対してプレビューが正常に実行されていることを確認します。プレビューが正常に動作している場合、インクリメンタルボックスが展開され、同期の初期インクリメンタル状態を設定できるようになります。
-
同期のインクリメンタル状態を設定します。この状態は、インクリメンタル行と初期値で構成されており、インターフェースで設定できます。これらの値を設定する際に、以下の重要な考慮事項を念頭に置いてください。
- インクリメンタル行は、同期間で 厳密に増加 する必要があります。行が不変(つまり、既存の行をその場で更新できない)である場合、一貫して増加する任意の行(例:自動インクリメント ID、行が追加された時刻を示すタイムスタンプ)で十分です。行が可変(つまり、テーブルが既存の行を更新することを許可し、新しい行が挿入されるだけでない)である場合、データのすべての変更に伴って増加する行(例:
update_time行)が必要です。 - 一度に複数の行を取り込まないようにするために、インクリメンタル行の初期値は、前回の実行で同期された_すべての行_ よりも大きくなければなりません。たとえば、最新の
SNAPSHOT同期が整数id行の値が1999までの範囲である行を取り込んだ場合、初期値を2000に設定できます。
- インクリメンタル行は、同期間で 厳密に増加 する必要があります。行が不変(つまり、既存の行をその場で更新できない)である場合、一貫して増加する任意の行(例:自動インクリメント ID、行が追加された時刻を示すタイムスタンプ)で十分です。行が可変(つまり、テーブルが既存の行を更新することを許可し、新しい行が挿入されるだけでない)である場合、データのすべての変更に伴って増加する行(例:
既存の行の更新版を取り込むと、Foundry データセットには前回の行のバージョンも含まれます(APPEND トランザクションタイプを使用していることを思い出してください)。各行の_最新の_バージョンのみが必要な場合は、Foundry の別のツール(例:変換)を使用してデータをクリーンアップする必要があります。インクリメンタルパイプラインに関するガイドを参照してください。
- 最後に、ワイルドカード記号
?を使用してクエリを更新します。ワイルドカードをクエリにどのように含めるかは、クエリのロジックによって異なります。以下に簡単な例を示し、次のことに注意してください。- 最初のインクリメンタル実行では、このワイルドカードは前の手順で指定した初期値に置き換えられます。
- その後の実行では、ワイルドカードは前回の実行でインクリメンタル行の_最大_同期値に置き換えられます。
上記で述べたように、インクリメンタル状態インターフェースは、同期のプレビューが正常に実行された場合にのみ機能します。つまり、インクリメンタル同期をゼロから作成する場合や、既存のインクリメンタル同期を複製する場合は、クエリのワイルドカード ? 演算子を使用せずにプレビューを実行する必要があります。
例
employees というテーブルを取り込んでいるとしましょう。トランザクションタイプは SNAPSHOT に設定されており、以下の単純な SQL クエリがあります。
Copied!1 2 3 4SELECT * -- 全てのカラムを選択します FROM employees -- "employees"テーブルからデータを取得します
時間 T1 に、テーブルは次のようになります:
| id | name | surname | update_time | insert_time |
|---|---|---|---|---|
1 | Jane | Smith | 1478862205 | 1478862205 |
2 | Erika | Mustermann | 1478862246 | 1478862246 |
そして、このテーブルが変更可能であると仮定すると、後の時間 T2 では次のようになります:
| id | name | surname | update_time | insert_time |
|---|---|---|---|---|
1 | Jane | Doe | 1478862452 | 1478862205 |
2 | Erika | Mustermann | 1478862246 | 1478862246 |
3 | Juan | Perez | 1478862438 | 1478862438 |
この同期を増分的に変換したいため、トランザクションタイプを APPEND に更新します。
増分カラムとして何を使用するべきでしょうか?重要な点は、id カラムも insert_time カラムも増分カラムとして使用するのは適切ではないということです。なぜなら、これらは更新を見逃す可能性があるからです。たとえば、Jane の行の surname カラムの変更などです。代わりに、増分カラムとして update_time を使用すべきです。
初期値として何を選択するかは、このテーブルから以前に行を同期したかどうかによります。時間 T1 に SNAPSHOT 同期を実行し、update_time の値が 1478862246 までの行をすでに同期していると仮定すると、重複を避けるために初期値として 1478862247 を使用すべきです。このテーブルから行を一度も同期していない場合は、初期値として 0(または日付を設定する場合は 01/01/1970)を使用できます。
最後に、SQL クエリを変更します。
Copied!1 2 3 4 5 6SELECT * -- 全ての列を選択します FROM employees -- "employees" テーブルからデータを取得します WHERE update_time > ? -- "update_time" が指定した値より大きいレコードのみをフィルタリングします
変換が完了しました。インクリメンタル同期を実行した後、データセット内に複数のJane行があることに注意してください(それぞれの更新に対して1つずつ)。前述のように、これらの重複を下流のロジックで処理する必要があります。例えば、ContourやTransformsで処理します。
インクリメンタルJDBC同期に問題が発生した場合、トラブルシューティングガイドのこのセクションが役立つかもしれません。
SQLクエリの並列化
並列機能は、対象データベースに対して別々のクエリを実行するため、若干異なるタイミングでのクエリによって、ライブ更新テーブルが異なる方法で扱われるケースを慎重に考慮してください。
並列機能を使うと、SQLクエリを複数の小さなクエリに簡単に分割して、エージェントが並列に実行できるようになります。
この動作を実現するために、SQL文を次の構造に変更する必要があります。
Copied!1 2 3 4 5 6 7 8 9 10 11SELECT /* FORCED_PARALLELISM_COLUMN({{column}}), FORCED_PARALLELISM_SIZE({{size}}) */ /* 強制的な並列化の列({{column}})、強制的な並列化のサイズ({{size}}) */ column1, column2 FROM {{table_name}} WHERE {{condition}} /* ALREADY_HAS_WHERE_CLAUSE(TRUE) */ /* 既にWHERE句が存在します(TRUE) */
クエリの主要な部分は次のとおりです:
FORCED_PARALLELISM_COLUMN({{行}})- これにより、テーブルが分割される行が指定されます。
- できるだけ均一な分布を持つ数値の行(または数値の行を生成する行式)である必要があります。
FORCED_PARALLELISM_SIZE({{size}})- 並列性の度合いを指定します。たとえば、
4とすると、指定した並列行の値を分割する4つのクエリと、並列行のNULL値のためのクエリの5つのクエリが同時に実行されます。
- 並列性の度合いを指定します。たとえば、
ALREADY_HAS_WHERE_CLAUSE(TRUE)- すでに
WHERE句があるのか、それとも生成する必要があるのかを指定します。これがFALSEの場合、WHERE 行%サイズ = Xが生成された各クエリに追加されます。これがTRUEの場合、この条件は代わりにANDで追加されます。
- すでに
例
employeesという名前のテーブルを同期しているとします。このテーブルには次のデータが含まれています:
| id | name | surname |
|---|---|---|
1 | Jane | Smith |
2 | Erika | Mustermann |
3 | Juan | Perez |
NULL | Mary | Watts |
基本クエリは次のようになります:
Copied!1 2 3 4 5 6SELECT id, -- 社員のIDを選択 name, -- 社員の名前を選択 surname -- 社員の姓を選択 FROM employees -- employeesテーブルから
これはデータベースで単一のクエリを実行し、テーブルからすべてのレコードを取得しようとします。
並列メカニズムを利用するためには、クエリを以下のように変更できます:
Copied!1 2 3 4 5 6 7 8SELECT /* FORCED_PARALLELISM_COLUMN(id), FORCED_PARALLELISM_SIZE(2) */ /* 強制並列化カラム(id)、強制並列化サイズ(2) */ id, name, surname FROM employees /* ALREADY_HAS_WHERE_CLAUSE(FALSE) */ /* 既にWHERE句がある(FALSE) */
次の三つのクエリを並行して実行します:
Copied!1 2 3 4 5 6SELECT id, name, surname -- 従業員のID、名前、姓を選択します FROM employees -- "employees"テーブルから WHERE id % 2 = 1 -- IDが奇数のレコードのみを抽出します
抽出:
| id | 名前 | 姓 |
|---|---|---|
1 | Jane | Smith |
3 | Juan | Perez |
そして
Copied!1 2 3 4 5 6 7 8 9-- 選択 SELECT id, -- ID name, -- 名前 surname -- 苗字 FROM employees -- 従業員テーブル WHERE id % 2 = 0 -- 偶数ID
抽出:
| id | name | surname |
|---|---|---|
2 | Erika | Mustermann |
そして
Copied!1 2 3 4 5 6 7 8SELECT id, -- 従業員のID name, -- 名前 surname -- 苗字 FROM employees -- 従業員テーブル WHERE id % 2 IS NULL -- 偶数のIDを持つ従業員のみ抽出
抽出:
| id | name | surname |
|---|---|---|
NULL | Mary | Watts |
OR 条件を含む WHERE 句を持つ並列処理
OR 条件を含む WHERE 句を持つ並列処理を使用する場合、条件を丸括弧で囲んで、条件の評価方法を示す必要があります。例えば、以下の同期を調べてください:
Copied!1 2 3 4 5 6 7SELECT /* FORCED_PARALLELISM_COLUMN(col1), FORCED_PARALLELISM_SIZE(32) */ -- 強制的な並列処理を設定します(col1)、その並列処理のサイズは32です col1, col2 FROM tbl -- tblテーブルから選択します WHERE -- 条件を設定します condition1 = TRUE OR condition2 = TRUE -- condition1かcondition2のいずれかが真であれば該当します /* ALREADY_HAS_WHERE_CLAUSE(TRUE) */ -- 既にWHERE節が存在します(TRUE)
この例の同期は、次のように変換されます:
Copied!1condition1 = TRUE OR condition2 = TRUE AND col1 % X = 0 -- condition1がTRUE、またはcondition2がTRUEかつcol1がXで割り切れる場合にTRUEとなります
ただし、そのステートメントは condition1 = TRUE OR (condition2 = TRUE AND col1 % X = 0) と論理的に解釈される可能性がありますが、望ましいのは (condition1 = TRUE OR condition2 = TRUE) AND col1 % X = 0 です。ユーザーは、WHERE 句全体を括弧で囲むことで、意図した解釈を確実にします。上記の例では、次のようになります:
Copied!1 2 3 4 5 6 7SELECT /* FORCED_PARALLELISM_COLUMN(col1), FORCED_PARALLELISM_SIZE(32) 強制並列処理の列(col1)とサイズ(32) */ col1, col2 FROM tbl WHERE (condition1 = TRUE OR condition2 = TRUE) -- 条件1が真または条件2が真の場合 /* ALREADY_HAS_WHERE_CLAUSE(TRUE) すでにWHERE句がある(真) */