注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
トランスフォームをプレビューする
Code Repositories のプレビュー ツールを使用して、入力データセットの限られたサンプルでコードを実行し、出力をすばやくプレビューします。プレビューは、変更をコミットしたり、チェックを実行したり、Foundry でデータセットをマテリアライズしたりすることなくサンプル出力を生成します。プレビューは、ビルドをトリガーしてコード変更をテストする必要をなくし、開発サイクルを加速させます。
プレビューの実行
プレビューは Code Repositories 内の 2 か所からトリガーできます。
(1) コードエディターのオプションパネルでプレビューを選択します。
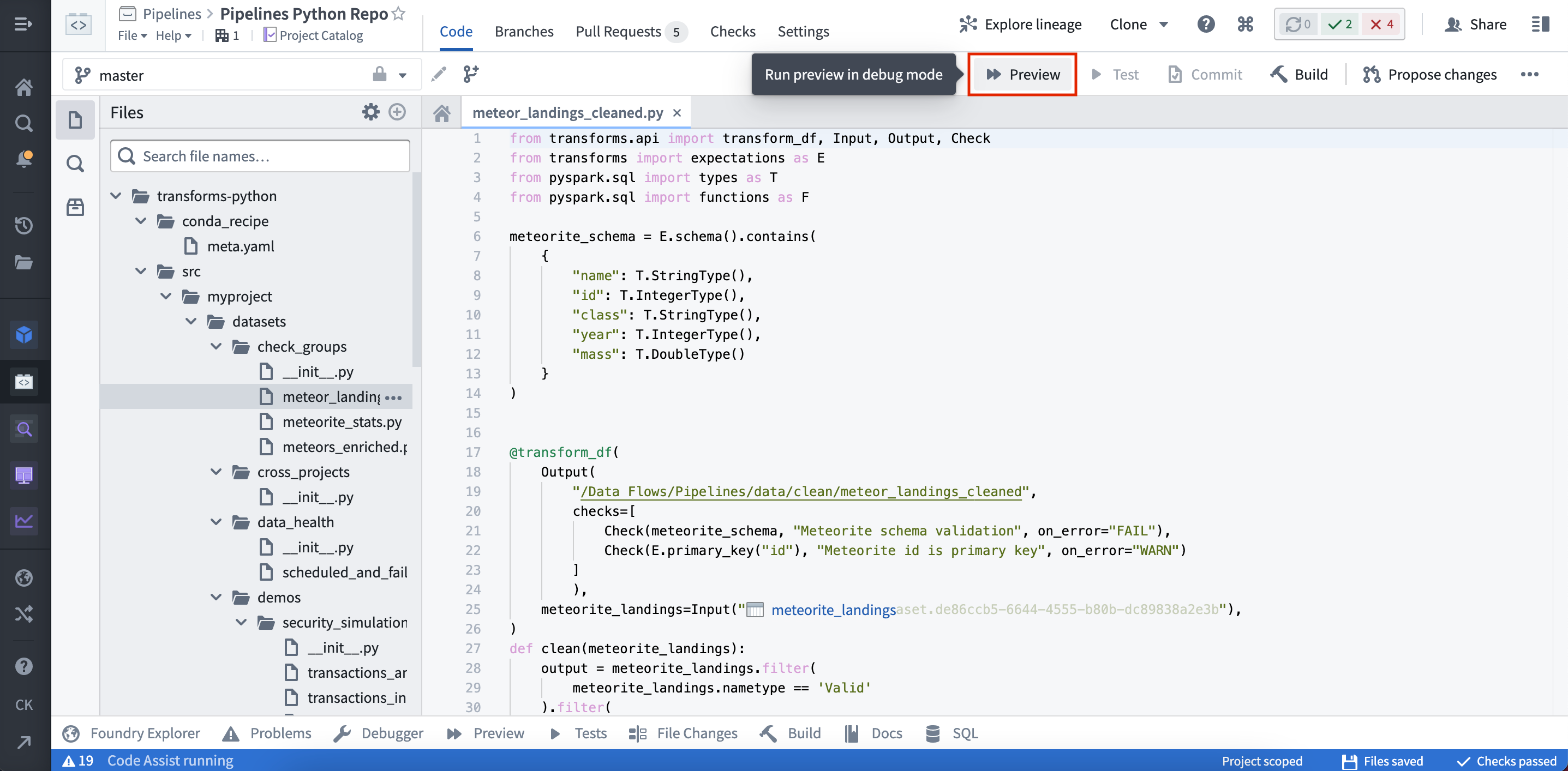
(2) ヘルパーパネルでプレビューを選択します。
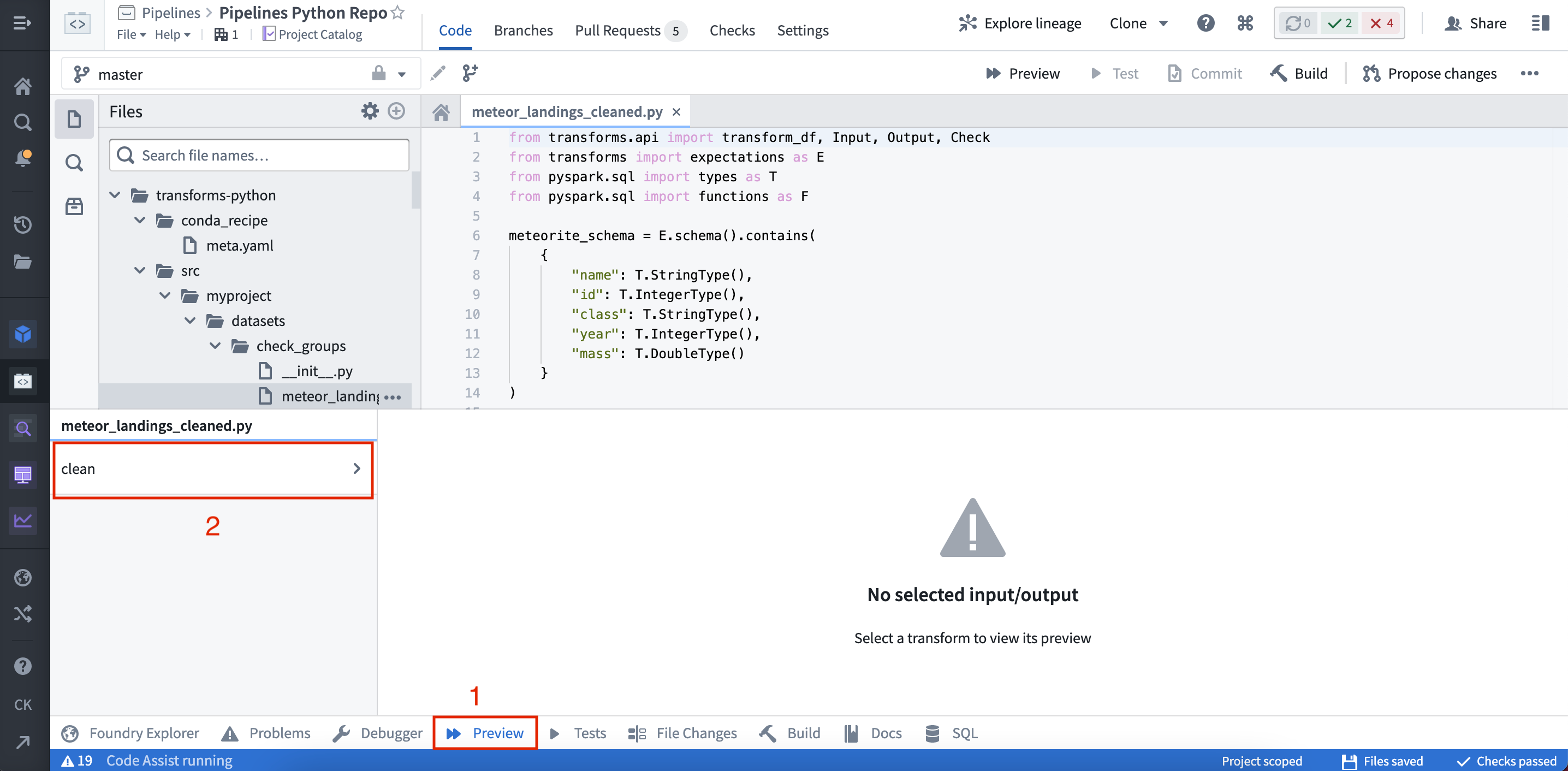
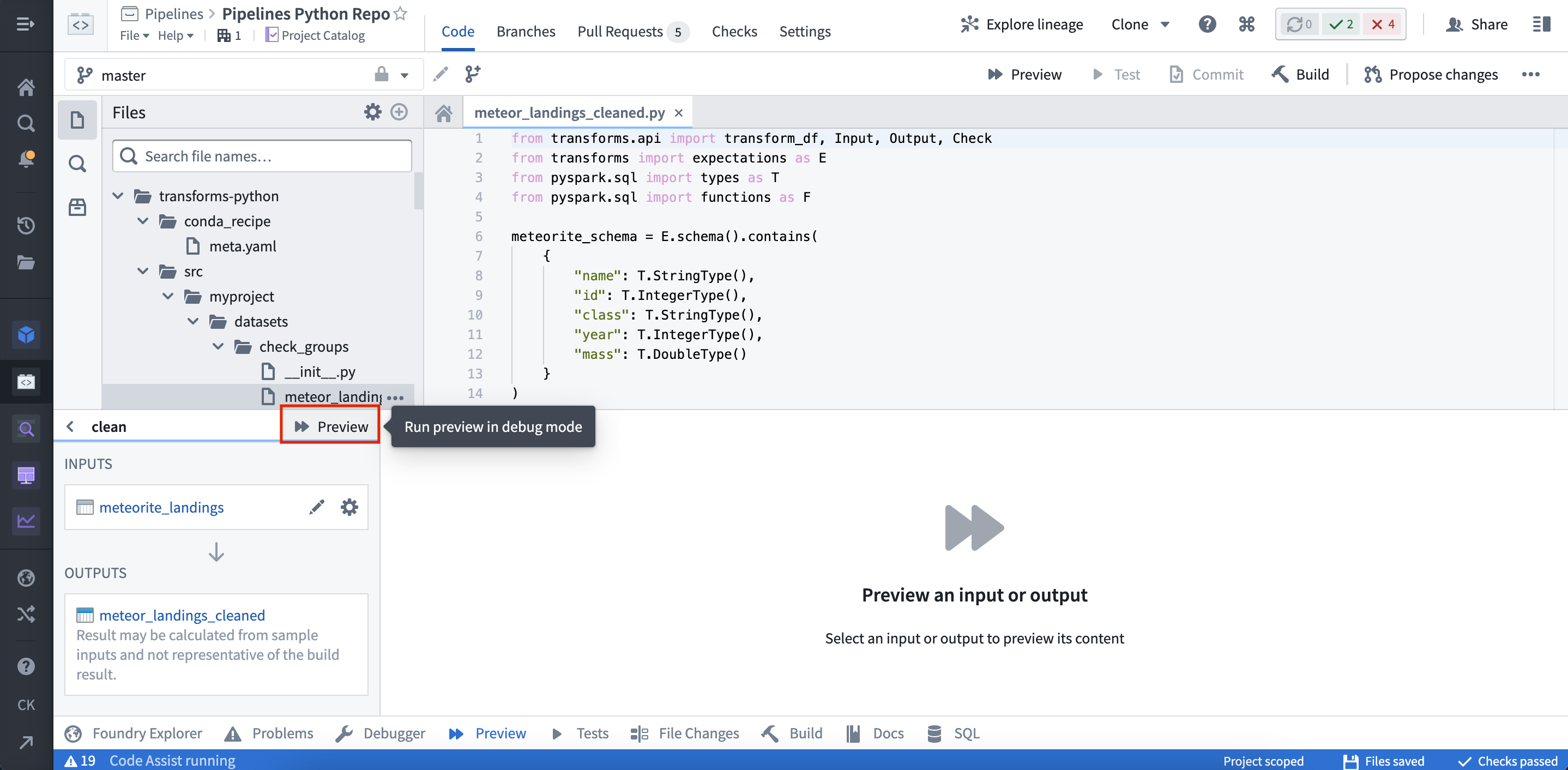
プレビューが実行されると、出力が表示されます。
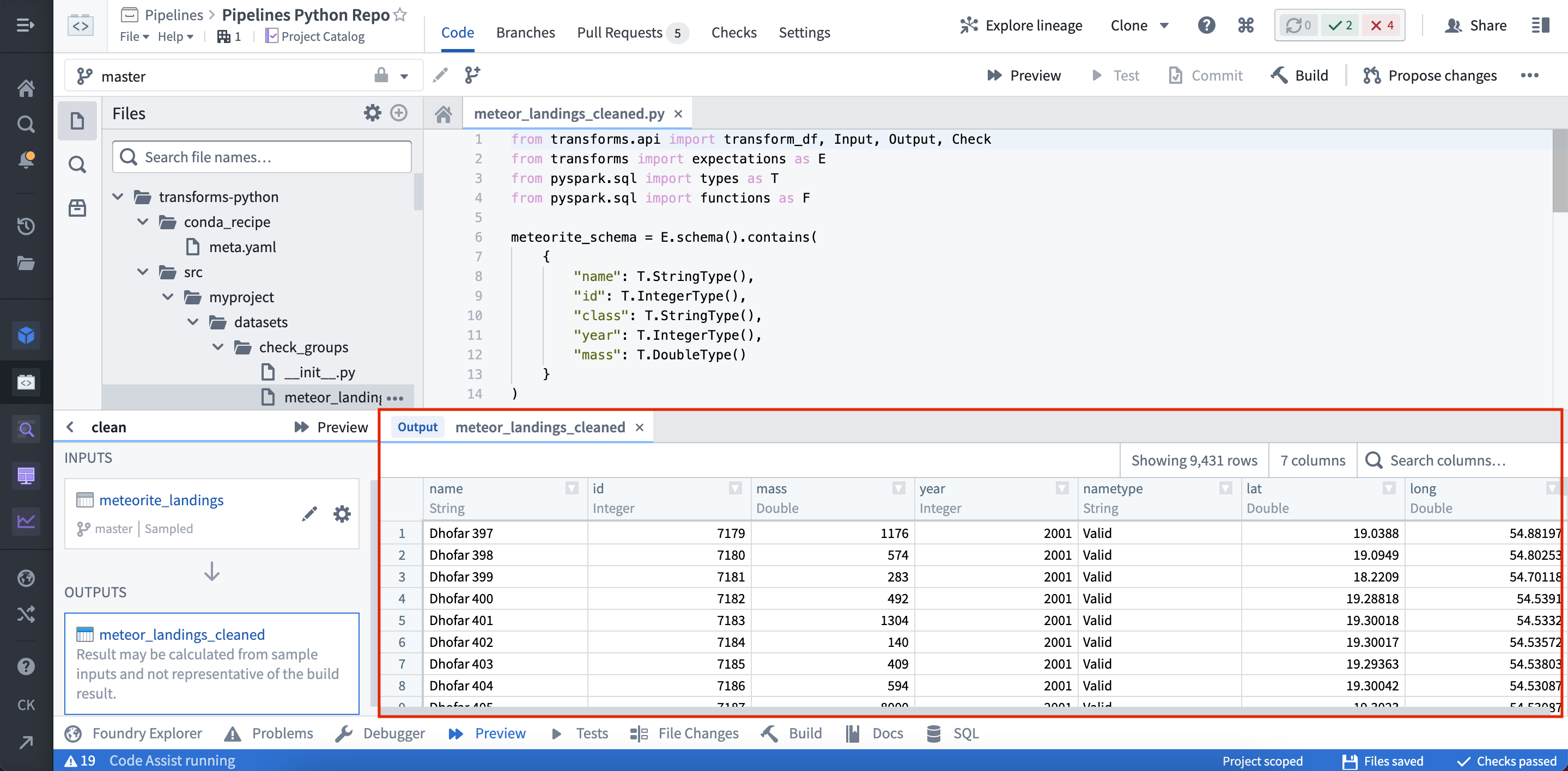
ファイルでプレビューを構成する
プレビューは、非構造化ファイル を含むデータセットで使用できます。ファイルを含むデータセットで初めてプレビューを実行する場合、サンプルで使用するファイルを構成する必要があります。
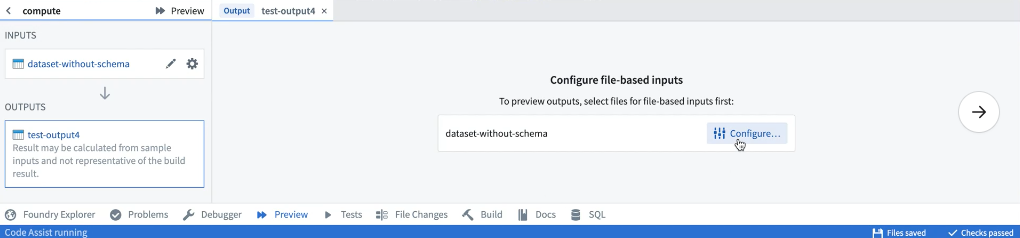
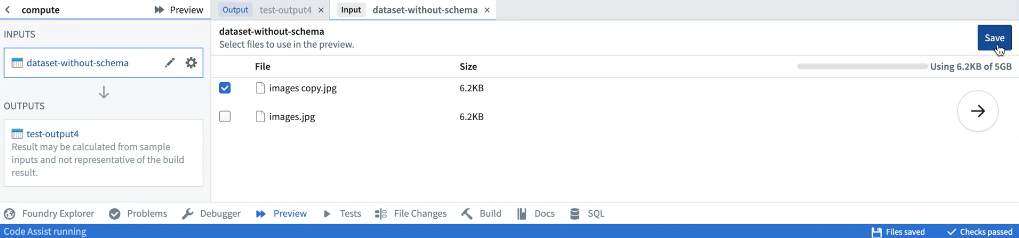
サンプルファイルが選択されると、入力リストから関連する入力を選択して再構成できます。構成を保存すると、プレビューは選択したサンプルファイルでコードを実行します。プレビューを再度実行する場合、入力ファイルを再構成する必要はありません。プレビューが実行されると、出力サンプルを行またはファイルとして表示できます。必要な権限がある場合、出力ファイルをダウンロードすることもできます。
モデルでプレビューを構成する
モデルアセット
追加の構成を必要とせずに、Foundry でトレーニングされた モデルアセット 、事前トレーニング済みのファイルを利用したモデル、またはインポートされた言語モデル のプレビューがサポートされています。
コンテナを利用したモデル および 外部ホストモデル は現在プレビューをサポートしていません。
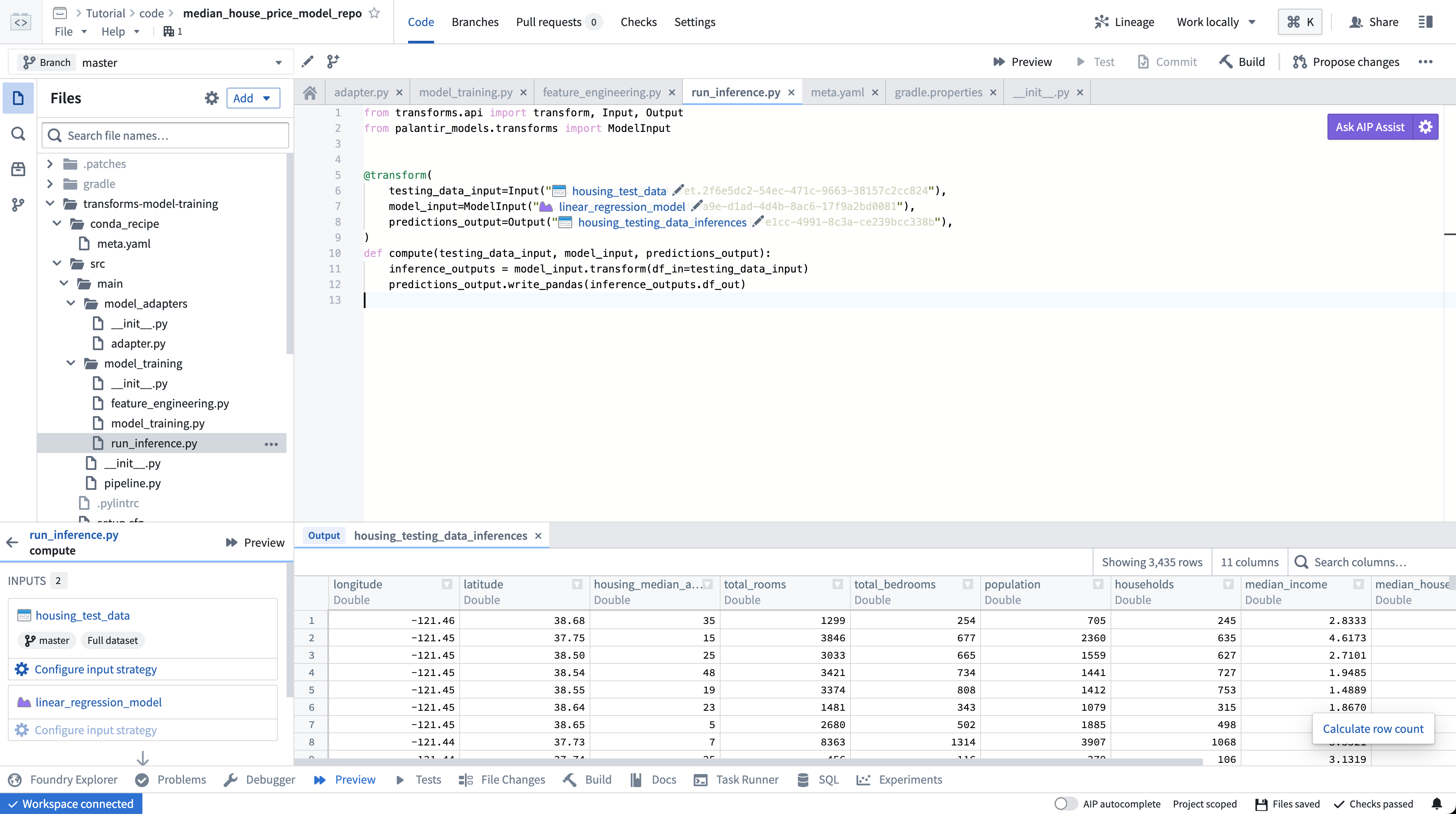
データセットを利用したモデル
データセットを利用したモデル でプレビューを構成する手順は、ファイルでプレビューを構成する 手順と同じです。プレビューが正常に実行できるように、すべての必要なモデリング専用ファイルを選択することを確認してください。Code Repositories でのモデル開発の詳細については、モデルアセットのトレーニング を参照してください。
トランスフォームジェネレーターで作成されたトランスフォームのプレビュー
トランスフォームジェネレーター で作成されたトランスフォームは関数の名前を共有します。プレビューのために意図したトランスフォームを選択しやすくするために、生成されたトランスフォームの __name__ 属性を変更して意味のある名前を生成します。たとえば:
Copied!1from transforms.api import transform_df, Output 2 3 4def generate_transforms(): 5 transforms = [] 6 for output_dataset_name in ["One", "Two", "Three"]: 7 @transform_df( 8 Output(f"/output/path/{output_dataset_name}")) 9 def my_transform(ctx, output_dataset_name=output_dataset_name): 10 # デフォルトでは、生成された変換は `my_transform (1)`, `my_transform (2)` などと名前が付けられます。 11 cols = ['id', 'value'] 12 vals = [ 13 (0, f'{output_dataset_name}'), 14 (1, f'{output_dataset_name}'), 15 (2, f'{output_dataset_name}') 16 ] 17 # Spark DataFrameを作成します 18 df = ctx.spark_session.createDataFrame(vals, cols) 19 return df 20 transforms.append(my_transform) 21 transforms[-1].__name__ = f'{output_dataset_name}_{transforms[-1].__name__}' # 変換の名前を上書きします 22 return transforms 23 24 25TRANSFORMS = generate_transforms()