注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
データセットをダウンロードのために準備する
次のエクスポートプロセスは高度なワークフローであり、Foundry インターフェースの Actions メニューを使用してデータを直接ダウンロードできない場合、または他の Foundry アプリケーションからエクスポートする場合にのみ実行する必要があります。
このガイドでは、Code Repositories でトランスフォームを使用して CSV をダウンロードのために準備する方法を説明します。場合によっては、Foundry インターフェースの Actions メニューを使用して Download as CSV を選択することなく、CSV 形式でデータのサンプルをダウンロードする必要があるかもしれません。これらのケースでは、Actions メニューを使用する代わりに、ビルド中にエクスポートファイルを準備することをお勧めします。
データを準備する
CSV をダウンロードのために準備する最初のステップは、フィルター処理されたクリーンなデータセットを作成することです。次のステップを実行することをお勧めします:
- データサンプルをエクスポートできることを確認し、データエクスポート制御ルールに従います。具体的には、エクスポートがユーザーの組織のデータガバナンスポリシーに準拠していることを確認する必要があります。
- 必要な目的を達成するために、データを可能な限り小さくフィルター処理する。一般的に、CSV 形式のデータの非圧縮サイズはデフォルトの HDFS ブロックサイズ (128 MB) 未満であるべきです。これを達成するために、必要な列のみを選択し、行数を最小限に抑えるべきです。特定の値でフィルター処理するか、任意の行数 (たとえば 1000 行) のランダムサンプルを取得することで、行数を減らすことができます。
- 列の型を
stringに変更する。CSV 形式はスキーマを持たないため (列の型とラベルが強制されない)、すべての列を文字列にキャストすることをお勧めします。特にタイムスタンプ列については重要です。
次のサンプルコードは、ニューヨークのタクシーデータセットからのもので、データをダウンロードのために準備するのに役立つかもしれません:
```python
def prepare_input(my_input_df):
from pyspark.sql import functions as F
filter_column = "vendor_id"
filter_value = "CMT"
df_filtered = my_input_df.filter(filter_value == F.col(filter_column)) # "vendor_id" が "CMT" のレコードをフィルタリング
approx_number_of_rows = 1000
sample_percent = float(approx_number_of_rows) / df_filtered.count() # サンプル抽出の割合を計算
df_sampled = df_filtered.sample(False, sample_percent, seed=0) # サンプルを抽出
important_columns = ["medallion", "tip_amount"]
return df_sampled.select([F.col(c).cast(F.StringType()).alias(c) for c in important_columns]) # 重要なカラムを選択し、文字列型に変換
同様のロジックとSparkの概念を使用して、SQLやJavaなどの他のSpark APIでもPreparationを実装できます。
出力フォーマットの設定とパーティションの結合
データがエクスポート用に準備されたら、出力フォーマットをCSVに設定できます。出力フォーマットをCSVに設定することで、データの基盤フォーマットがFoundryにCSVファイルとして保存されます。また、出力フォーマットをJSON、ORC、Parquet、テキストに設定することもできます。最後に、結果を1つのCSVファイルに保存するためには、データをダウンロード用に単一のパーティションに結合する必要があります。
Python
以下のサンプルコードは、Pythonでデータを結合する方法を示しています:
Copied!1 2 3 4 5 6 7 8 9from transforms.api import transform, Input, Output @transform( output=Output("/path/to/python_csv"), # 出力パスを指定 my_input=Input("/path/to/input") # 入力データのパスを指定 ) def my_compute_function(output, my_input): # 入力データフレームを1つのパーティションにまとめ、CSV形式で出力する output.write_dataframe(my_input.dataframe().coalesce(1), output_format="csv", options={"header": "true"})
SQL
以下のサンプルコードは、SQLでデータをコアレースする方法を示しています:
CREATE TABLE `/path/to/sql_csv` USING CSV AS SELECT /*+ COALESCE(1) */ * FROM `/path/to/input`
-- `/path/to/sql_csv`という名前のテーブルをCSV形式で作成します。
-- テーブルの内容は`/path/to/input`から全てのデータを選択してコピーします。
-- COALESCE(1) ヒントは、Spark SQLにおいて1つのパーティションにデータを集約するよう指示します。
公式 Spark ドキュメント ↗ を参照して、追加の CSV 生成オプションを確認してください。
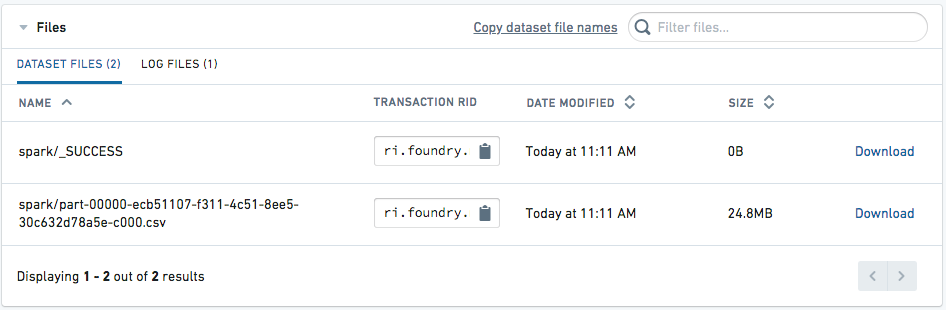
ダウンロード用ファイルへのアクセス
データセットが構築されたら、データセットページの Details タブに移動します。CSV がダウンロード可能として表示されるはずです。