注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
継承されたマーキングと組織の削除
現在、stop_propagating 変換プロパティは Pipeline Builder でサポートされていません。まず Code Repositories のリソースで変換プロパティを使用し、その出力を Pipeline Builder グラフに追加してパイプラインの構築を続けることをお勧めします。
マーキング と 組織 は、ユーザーの適格性に基づいてリソースへのアクセスを制限します。
依存リソースを導出する際に制限された内容が削除または難読化されると、ユーザーはその導出リソース上のマーキングおよび/または組織を削除することを希望する場合があります。この継承されたマーキングと組織を削除するプロセスは、stop_propagating および stop_requiring 入力変換プロパティを使用して行うことができます。
stop_propagatingは継承された マーキング (例:PII) を削除するために使用されます。stop_requiringは継承された 組織 (例:Palantir) を削除するために使用されます。
用語
- 組織 は、ユーザーとリソースのグループ間の厳格な壁を保証するプロジェクトに適用されるアクセス要件です。アクセス要件を満たすために、ユーザーはプロジェクトに適用された少なくとも1つの組織のメンバーまたはゲストメンバーである必要があります。
- マーキング は、すべてまたは何もない方式でアクセスを制限するリソースに適用されるアクセス要件です。アクセス要件を満たすために、ユーザーはリソースに適用された すべての マーキングのメンバーである必要があります。
- ロール は、ユーザーが特定のリソースで実行できる特定のワークフローを定義する権限の集合です (例:ビューア、エディタなど)。
知っておくべきこと
stop propagatingおよびstop requiringキーフレーズは、組織とマーキングにのみ適用され、ロールには 適用されません。- リポジトリには、少なくとも1つの保護されたブランチ(例えば、main)が必要です。このブランチでは、少なくとも1人の必須承認者を強制 する必要があります。
- 組織とマーキングの削除は保護されたブランチでのみ可能です。保護されていないブランチ(例:
on_branches=[..., "not-protected-branch"])を指定すると、ビルドが失敗します。 - 組織とマーキングの削除は、Python、Java、および SQL でサポートされています。
- 継承された組織とマーキングの削除を承認するためには、特別なユーザー権限が必要です。ユーザーはマーキングを削除するために
マーキングを削除権限、組織を削除するためにアクセスを拡大権限が必要です。
基本的なワークフロー
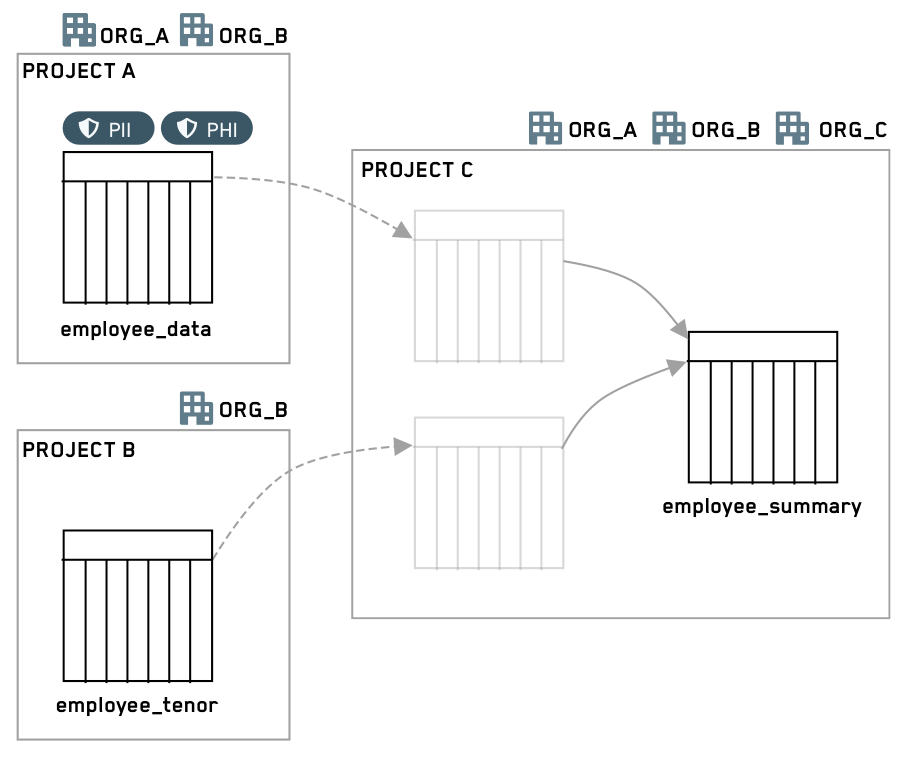
以下の Project C の灰色のデータセットボックスは、すべての入力に対してプロジェクトリファレンスを追加する必要があるという事実を強調しています。
手順
-
保護されたブランチから新しいブランチを作成します (例:main)。
-
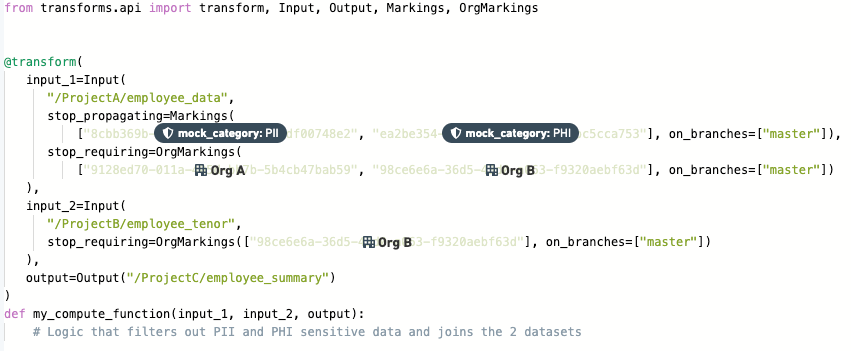
stop_propagatingおよび/またはstop_requiringプロパティを入力変換に追加します。例:
-
このコードを保護されたブランチにマージするためのプルリクエストを作成します。
-
マーキングの
マーキングを削除権限または組織のアクセスを拡大権限を持つユーザーが提案された変更を承認または拒否できます。複数のレビュアーが追加された場合、任意のレビュアーによる拒否はプルリクエスト全体の拒否につながります。 -
承認された場合、コードエディタは PR をマージし、出力データセットをビルドします。出力データセットがビルドされた後、伝播されたマーキングおよび/または組織は存在しなくなります。
内部的には、組織は少し異なる種類のマーキングとして表されているため、stop_requiring に続く変換キーワードは OrgMarkings と呼ばれます。
入力変換プロパティ
継承されたマーキング (例:PII) を削除するには、stop_propagating キーフレーズを使用します。
継承された組織 (例:Palantir) を削除するには、stop_requiring キーフレーズを使用します。
これらのキーフレーズは、マーキングまたは組織の削除を必要とする すべての 入力で指定する必要があります。各削除について、削除を適用する保護されたブランチも指定する必要があります。マーキング ID、組織 ID、およびブランチは常に引用符で指定する必要があります。
上流の組織を少なくとも1つ提供する必要があります。これは、ユーザーが少なくとも1つの組織を満たすだけでよいからです。各リストされた組織について承認が必要になります。以下の 詳細なワークフロー は、この点を示す例を提供します。
Python
Pythonでは、マーキングの削除は入力コンストラクタで指定されます。
Copied!1 2 3 4 5 6 7 8 9 10@transform( # 入力を定義します。"<input_id>"は入力のIDを表します。 # stop_propagatingは、特定のマーキング(markingId1など)を特定のブランチ(branch1など)に伝播させないようにするためのパラメータです。 # stop_requiringは、特定の組織マーキング(orgMarking1など)を特定のブランチ(branch2など)で必須ではなくするためのパラメータです。 input_1=Input("<input_id>", stop_propagating=Markings([markingId1, ...], [branch1, ...]), stop_requiring=OrgMarkings([orgMarking1, ...], [branch2, ...])), # 出力を定義します。"<output_id>"は出力のIDを表します。 output=Output("<output_id>") )
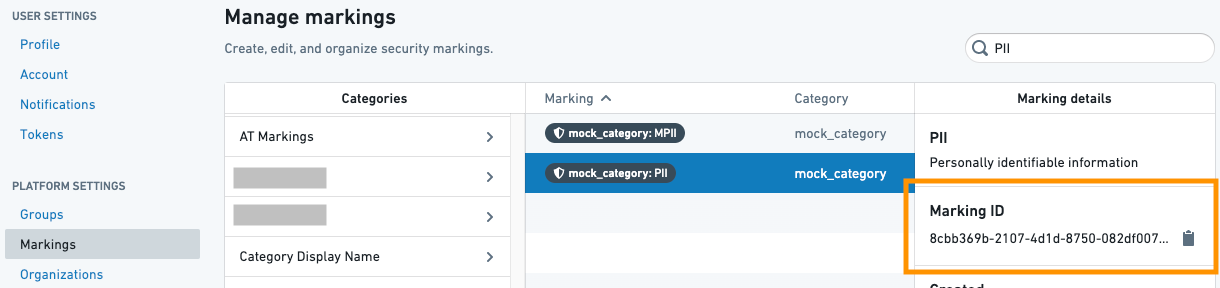
Markings クラスは、マーキング ID のリストと、マーキングの削除を適用する保護されたブランチのリストを受け取ります。マーキング ID は、Settings ページの Markings リストで見つけることができます。
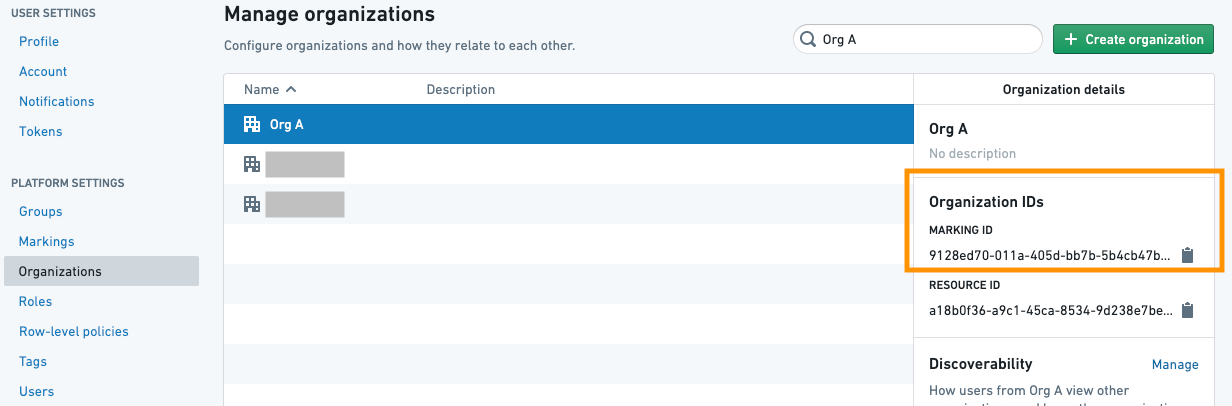
OrgMarking クラスは、組織 ID のリストと、マーキングの削除を適用する保護されたブランチのリストを受け取ります。組織 ID は、Settings ページの Organizations リストで見つけることができます。
Java
Java 自動登録
Java では、マーキングの削除は、自動登録された変換の入力に対するアノテーションを介して指定されます。
構文:
Copied!1 2 3 4 5 6 7 8 9 10 11 12@Compute public void myComputation( // 停止伝播(指定したマーキングおよびブランチに対して) @StopPropagating(markings = {markingId1, ...}, onBranches = {branch1, ...}) // 停止要求(指定した組織マーキングおよびブランチに対して) @StopRequiring(orgMarkings = {orgId1, ...}, onBranches = {branch2, ...}) // 入力IDを指定 @Input("<input_id>") FoundryInput input, // 出力IDを指定 @Output("<output_id>") FoundryOutput output)
@StopPropagating と @StopRequiring アノテーションは、マーキング削除を適用するマーキングIDのセットと保護されたブランチのセットを取ります。
マーキングまたはブランチが一つだけ指定されている場合、それを {} で囲む必要はありません(例:@StopPropagating(markings = marking1, onBranches = "my-branch"))。
Java 手動登録
手動で登録された Java 変換のために、MyPipelineDefiner.java ファイル内で登録時に unmarking を指定するための以下の構文を使用します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31@Override public void define(Pipeline pipeline) { // 高レベルの手動変換を定義 HighLevelTransform highLevelManualTransform = HighLevelTransform.builder() // 高レベルの手動関数インスタンスを設定 .computeFunctionInstance(new HighLevelManualFunction()) // 入力エイリアスにパラメータを設定 .putParameterToInputAlias("myInput", "/path/to/input/dataset") // 出力エイリアスを設定 .returnedAlias("/path/to/output/dataset") // 希望されるマーキング解除を設定 .desiredUnmarkings(Set.of( Unmarking.builder() .branch("branch1") .input(alias("/input1")) .output(alias("/output")) // マーキングIDを設定 .markingId(MarkingId.valueOf("markingId")) .build(), Unmarking.builder() .branch("branch1") .input(alias("/input1")) .output(alias("/output")) // 組織IDを設定 .markingId(MarkingId.valueOf("orgId1")) .build() )) .build(); // パイプラインに高レベルの手動変換を登録 pipeline.register(highLevelManualTransform); }
SQL
SQLでは、マーキングの削除はSparkSQLのヒントステートメントを使用して指定されます:
Copied!1 2 3 4 5 6 7CREATE TABLE <output_id> AS SELECT /*+ foundry_stop_propagating(markingId1, ...) foundry_stop_requiring(orgMarkingId1, ...) foundry_on_branches(branch1, ...) */ * FROM <input_id> -- このクエリは、新しいテーブルを作成し、その中に入力IDからのデータをコピーします。 -- foundry_stop_propagating: 伝播を止めるマーキングを指定 -- foundry_stop_requiring: 必要とされなくなるマーキングを指定 -- foundry_on_branches: このクエリが適用されるブランチを指定
マーキングと組織の削除は、任意の SELECT ステートメントに追加できます。例えば:
Copied!1 2 3 4CREATE TABLE <output_id> AS SELECT * FROM <input_1_id> CROSS JOIN (SELECT /*+ foundry_stop_propagating(markingId1) foundry_on_branches("my-branch") */ /*+ foundry_stop_propagating(markingId1)は特定のマーキングIDの伝播を停止します。foundry_on_branches("my-branch")は特定のブランチ上での操作を可能にします。*/ * FROM <input_2_id>)
削除権限
一般的に、プルリクエストを承認し、コードを表示するためには、承認者がプロジェクトとリポジトリ自体の組織とマーキングを通過し、基本的な Stemma の リポジトリを表示する ワークフローが含まれている役割を持つ必要があります(デフォルトでは、Viewer 役割に含まれています)。ユーザーはまた、承認モードを設定したり、これらの組織とマーキングを削除するプルリクエストを承認したりするために、各組織とマーキングに対する権限を持つ必要があります。ユーザーが組織やマーキングのメンバーである必要は必ずしもありません。
マーキングの承認には、承認するユーザーがマーキングに対して マーキングを削除する 役割を持っている必要があります。
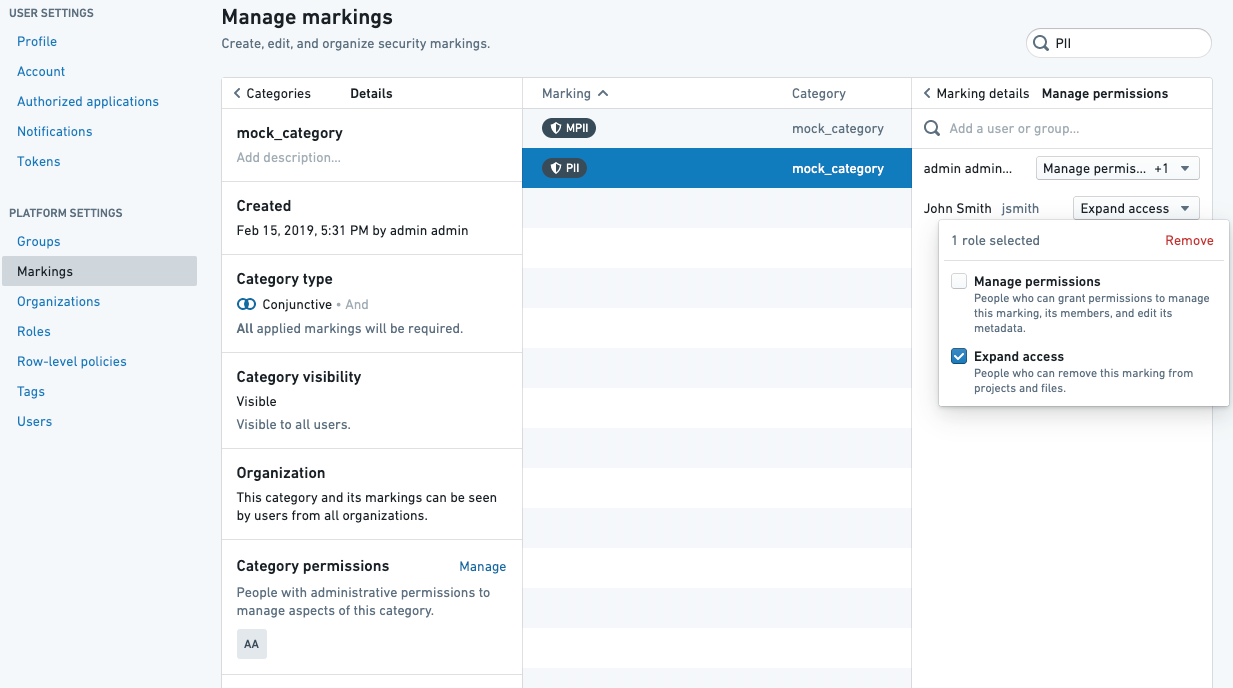
組織の承認には、承認するユーザーがマーキングに対して アクセスを拡大する 役割を持っている必要があります。
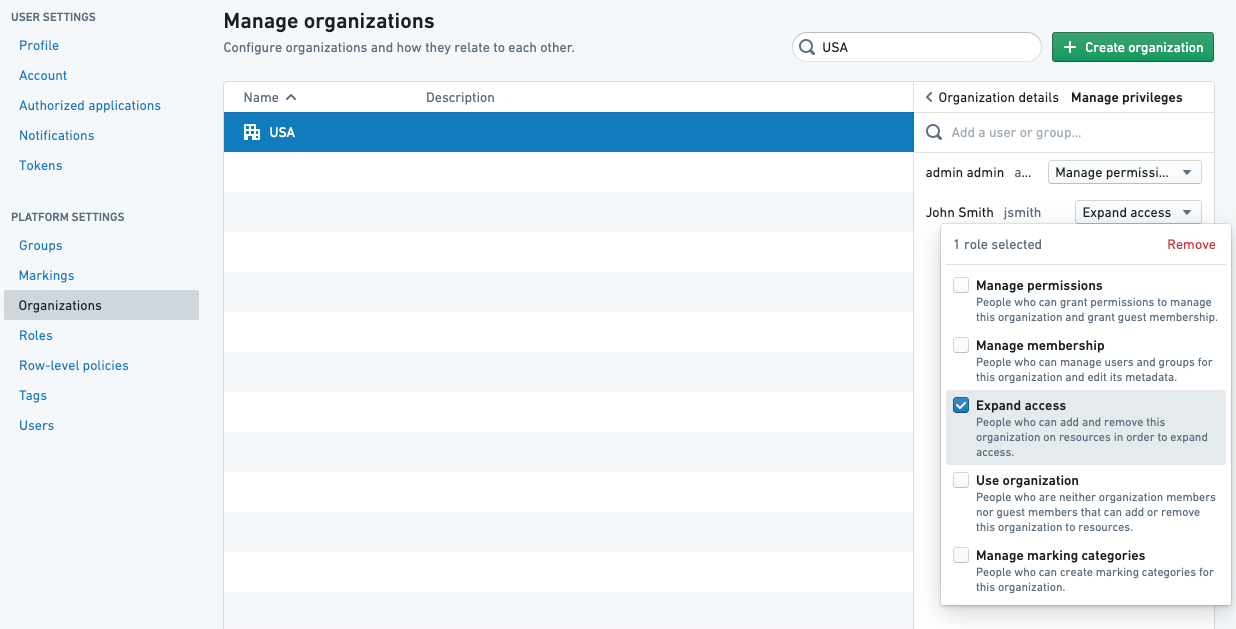
承認モード
データガバナンスユーザーは、各リポジトリと各組織とマーキングについて、新たな承認をトリガーするためのモードを定義できます:
- 再承認を必要とする: これは、すべての組織とマーキングに対するデフォルトのモードです。リポジトリは、この組織とマーキングが削除されたブランチに対して行われたすべてのプルリクエストに対して、常にセキュリティ承認を必要とします。このモードは、ロジックの変更に対する保護を提供し、組織とマーキングが安全に削除されることを保証します。
- 再承認を必要としない: この組織および/またはマーキングが、指定の入力に対して初めて変換で削除されると、承認が必要となります。ロジックの後続の変更は、セキュリティ承認にブロックされません。
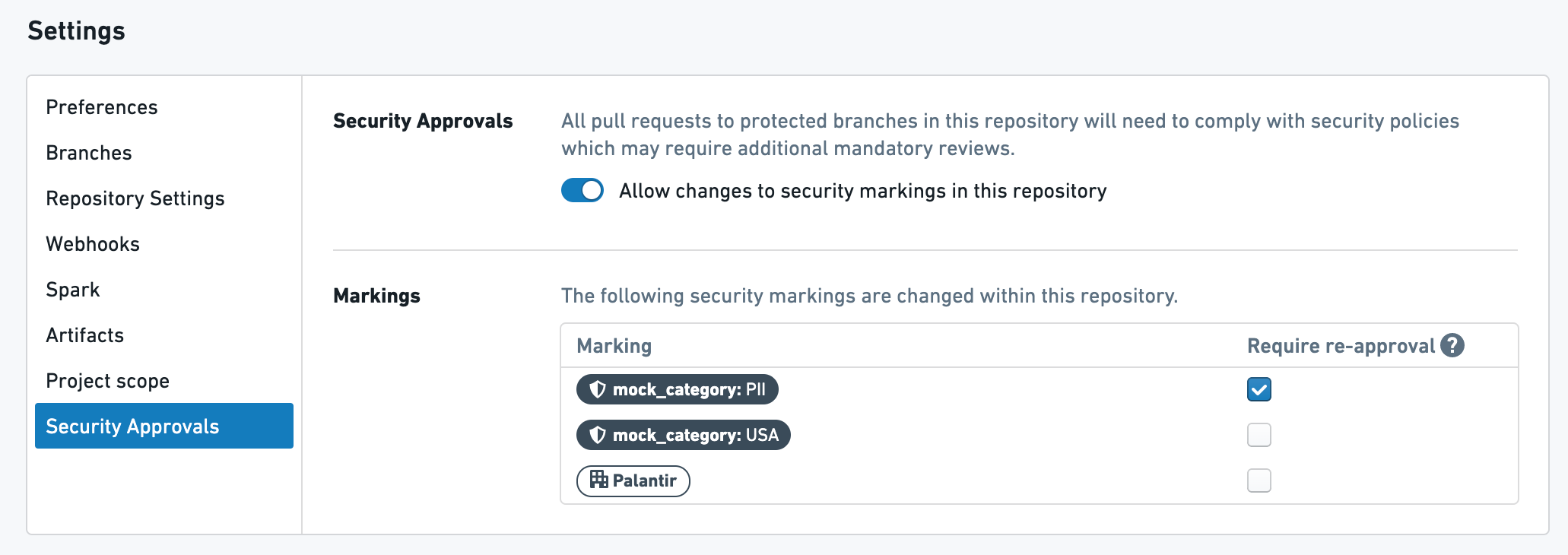
例 1
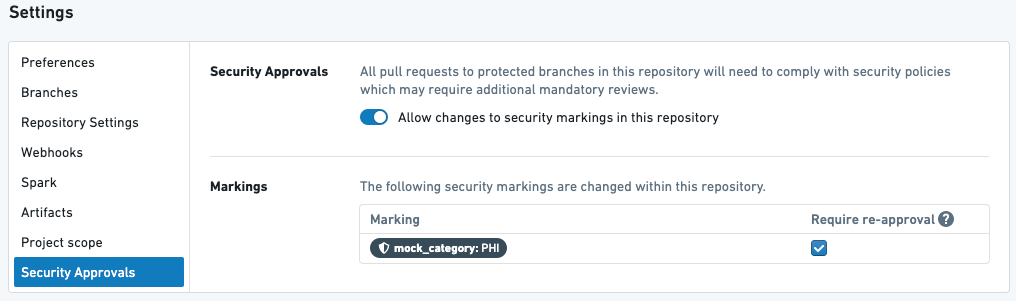

上記は、再承認が必要なマーキング PHI が1つあるリポジトリ内の変換です。
上記の設定を考えると、以下のようなことが起こります:
- ユーザーが最初の PR を作成して PHI マーキングの伝播を止めると、PHI マーキングに
削除役割を持つユーザーからの承認が必要となります。 - ユーザーが次の PR で上記の変換を後で修正すると、再度承認を求められます。
- ユーザーがリポジトリ内の何かを修正すると – このファイルまたは他の任意のファイル – 再度 PHI マーキングのための承認を求められます。
例 2
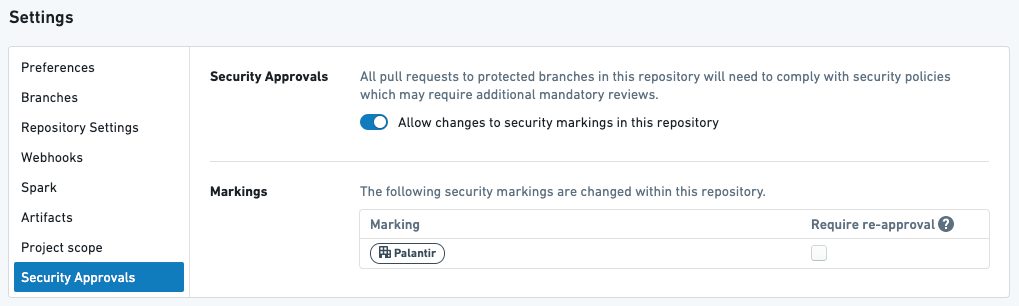

上記は、再承認を必要としない組織 PALANTIR が1つあるリポジトリ内の変換です。
上記の設定を考えると、以下のようなことが起こります:
- ユーザーが最初のプルリクエストを作成して
PALANTIR組織の要求を止めると、PALANTIR組織にアクセスを拡大する役割を持つ人からの承認が必要となります。 - ユーザーが次のプルリクエストで上記の変換を後で修正すると、承認を求められることはありません。
- ユーザーがこのリポジトリ内の何かを後で修正すると、承認を求められることはありません。
例 3

変換 1:上記は、マーキング PII と組織 PALANTIR が1つある変換です。PII マーキングは再承認を必要とし、PALANTIR 組織は再承認を必要としません。

変換 2:上記は、再承認を必要としないマーキング USA が1つある変換です。
上記の設定を考えると、以下のようなことが起こります:
- ユーザーが変換 1 の最初のプルリクエストを作成すると、
PIIマーキングにマーキングを削除する役割を持つユーザーと、PALANTIR組織にアクセスを拡大する役割を持つユーザーからの承認が必要となります。 - ユーザーが次のプルリクエストで変換 1 を後で修正すると、
PIIマーキングにマーキングを削除する役割を持つユーザーからのみ承認を求められます。 - ユーザーが変換 2 の最初のプルリクエストを作成すると、
USAマーキングとPIIマーキングにマーキングを削除する役割を持つユーザーからの承認が必要となります。 - ユーザーが次のプルリクエストで変換 2 を後で修正すると、
PIIマーキングにマーキングを削除する役割を持つユーザーからのみ承認を求められます。 - ユーザーがこのリポジトリ内の何かを後で修正すると、
PIIマーキングにマーキングを削除する役割を持つユーザーからのみ承認を求められます。
詳細なワークフロー
この例のシナリオでは、コードエディターは、敏感な上流プロジェクトから2つのデータセットを使用し、特定の情報を削除し、結果のデータセットに広範な視聴者がアクセスできるようにしたいと考えています。2つのデータセットにはそれぞれ2つのマーキングがあり、下流のプロジェクトのリファレンスとして追加されています。コードエディターは、4つのマーキングのうち3つが伝播を停止するようにしたいと考えています。つまり、これらが出力データセットに表示されないようにすることです。さらに、上流プロジェクトは OrgA または OrgB のユーザーに制限されており、下流データを OrgC のユーザーに配布することを目指しています。
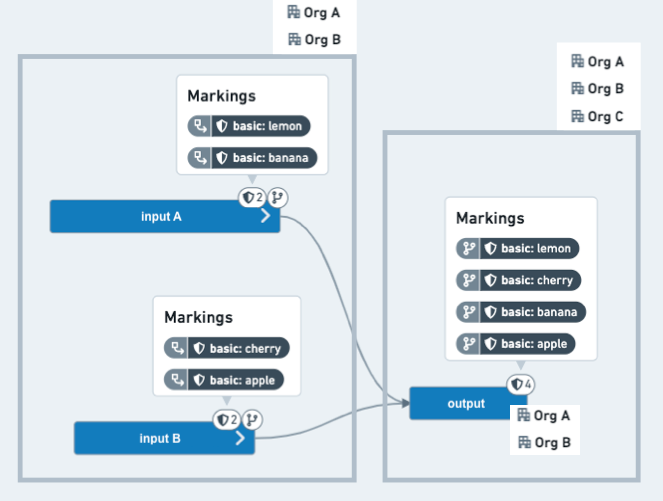
前:コードエディターのブランチ上の 出力 データセットはすべてのマーキングを継承し、まだ OrgA または OrgB のユーザーに制限されています。
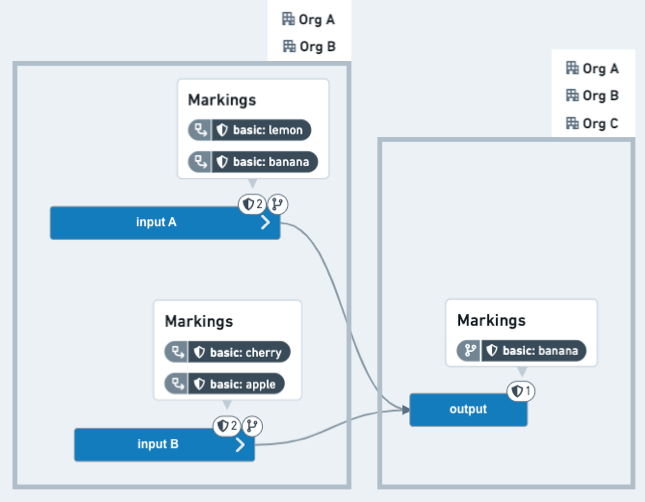
後:出力 データセットは、保護されたブランチ(たとえば、main)にマージされた後、1つだけ継承されたマーキングを持ち、ユーザーが OrgA または OrgB のメンバーであることを要求しません。
手順
- コードエディターは、下流プロジェクトのリポジトリの
feature/clean-dataブランチ上で新たな変換を書きます。
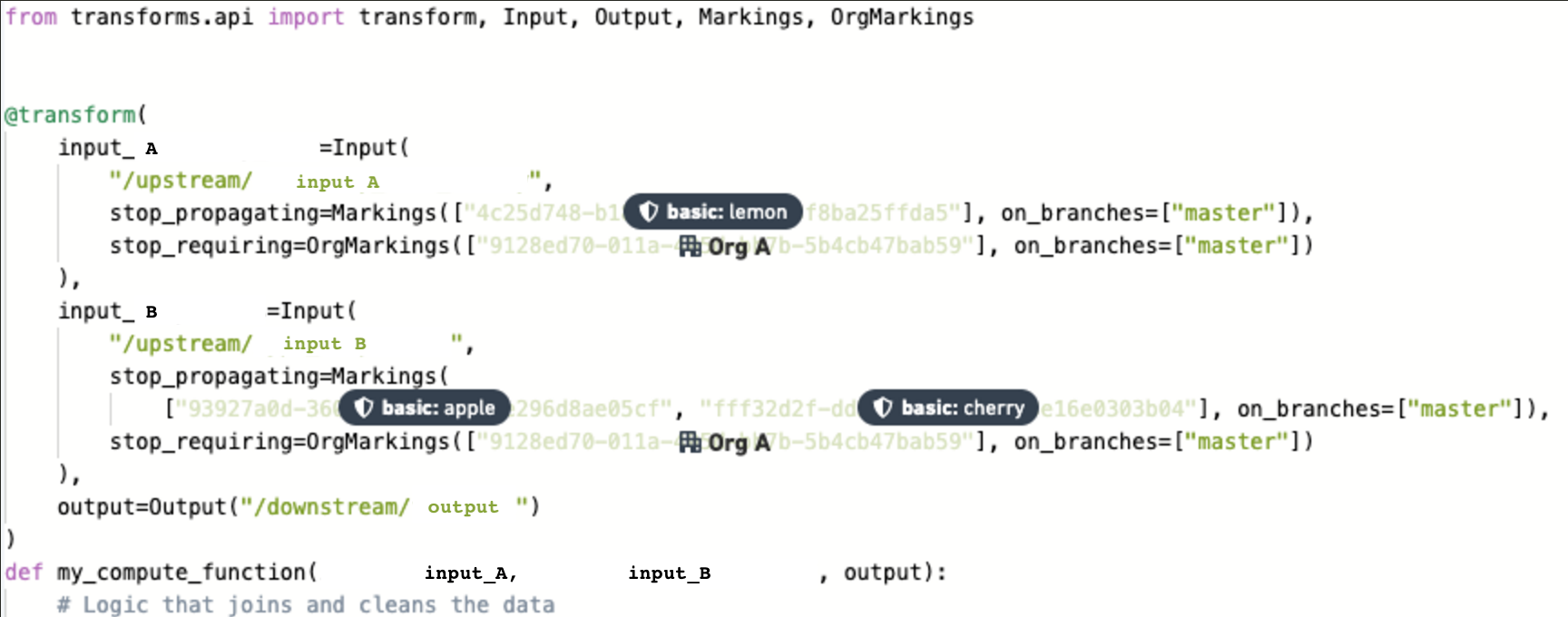
-
すべてのマーキングの変更が
masterブランチに対して求められているため、feature/clean-data上で作業するための承認は必要ありません。つまり、出力データセットがfeature/clean-dataブランチ上で構築されるとき、すべての上流マーキングがまだ継承されます。 -
コードエディターは、main ブランチへのプルリクエストを作成し、データガバナンスユーザーからの承認を求めます。これらのユーザーは、
lemon、apple、cherryマーキングによって制限されたデータを管理します。また、コードエディターは、OrgA のデータが他の組織と共有される必要があるときに承認できる OrgA のアクセスを拡大する組織管理者からの承認を求めます。
継承された組織を削除することによるアクセスの拡大は、すべての継承された組織を削除する効果がありますが、承認は変換にリストされた組織に対する適切な権限を持つユーザーからのみ必要とされます。すべての組織から承認を必要としたい場合は、stop_requiring コンポーネントにすべての ID をリストする必要があります。この例では、OrgA が上流プロジェクトのデータを主に管理しているため、エディターは組織間の承認プロセスのために OrgA を選びました。したがって、エディターは継承された組織を削除するために OrgA の管理者からの承認だけが必要です。エディターがどの組織の承認を求めたいかによって、エディターは stop_requiring を選ぶことができます:
(1) OrgA(OrgA の管理者による承認により)、
(2) OrgB(OrgB の管理者による承認により)、または
(3) OrgA と OrgB の両方(両組織の管理者からの承認により)。
結果として、出力データセットは入力から組織を継承せず、それが位置しているプロジェクトからの組織だけを尊重します。
-
データガバナンスユーザーと組織管理者は Foundry の通知を受け取り、承認が求められていることを知ります。
-
PR が承認されると仮定して、コードエディターはそれをマージし、上記の After 画像に示されているように出力データセットを構築します。
-
翌週、別のコードエディターが別のコードファイルに変更を加え、
masterにマージするための PR を開きます。
すべてのマーキングが再承認を必要としない場合、PR はセキュリティレビューを経ずに承認できます。任意のマーキングが承認を必要とする場合、この新しい PR は、そのマーキングを管理するデータガバナンスまたは組織管理者によるセキュリティレビューが必要となります。