注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Pipeline Builder でインクリメンタルパイプラインを作成する
このチュートリアルでは、Pipeline Builder を使って、単一のデータセットを出力するシンプルなインクリメンタルパイプラインを作成します。
以下で使用されるデータセットは、インクリメンタル計算が適用可能であることを示すための仮想的な例です。
パート 1:問題の説明
flights という入力データセットがあり、毎週新しいデータが追加されると仮定しましょう。JFK 空港を出発するフライトのみをフィルター処理して、それらのフライトを出力 filtered_flights に追加したいとします。
flights データセットが 2000 万行あるとしましょうが、毎週 100 万行ずつ追加されます。インクリメンタル計算では、パイプラインは flights のすべての行ではなく、最新の未処理トランザクションのみを考慮する必要があります。
パイプラインが定期的に実行される場合、インクリメンタル処理によって各実行のデータスケールが大幅に削減され、時間とリソースが節約されます。
それでは、インクリメンタルパイプラインの設定方法を見ていきましょう。
パート 2:インクリメンタル要件の検証
まず、すべてのインクリメンタル制約が満たされていることを確認します。
- 入力
flightsは、APPENDトランザクションまたは既存のファイルを変更しないUPDATEトランザクションによって更新されます。 flightsからfiltered_flightsを計算するロジックは、後のビルドでfiltered_flightsに書き込まれたデータを変更する必要がありません。- パイプラインロジックを変更したい場合(例:
LGA空港を出発するフライトも含める場合)、パイプラインを更新できます。以前に処理されたフライトにそのロジックを適用したい場合は、パイプラインをリプレイすることを検討してください。
- パイプラインロジックを変更したい場合(例:
- パイプラインにウィンドウ関数、集約、またはピボットが含まれている場合は、これらが現在のトランザクションのみに適用されることを確認してください。
Pipeline Builder のインクリメンタル計算に関する制約の完全なリストについては、制約を参照してください。
パート 3:パイプラインの作成
ここで、新しいパイプラインを初期化できます(手順の詳細については、Pipeline Builder でバッチパイプラインを作成するを参照してください)。入力データセットとして flights をインポートしたと仮定します。
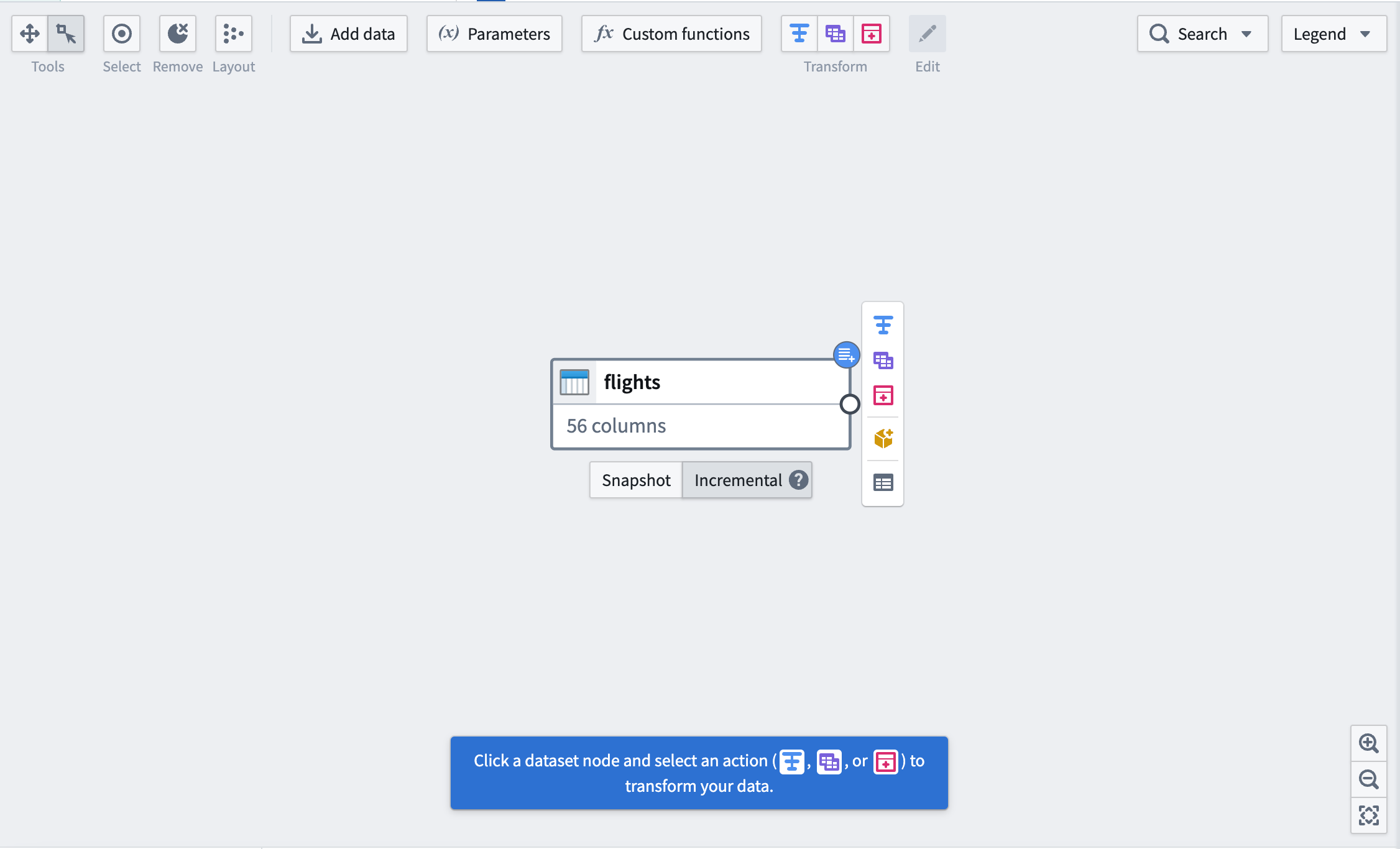
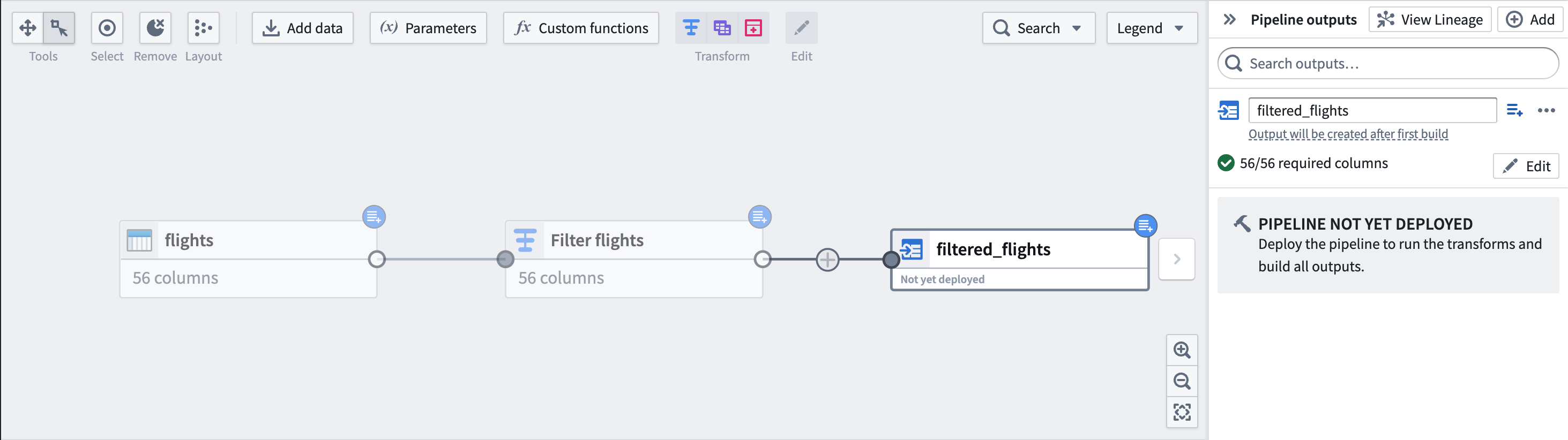
まず、データセットの下にあるボタンを使って、入力データセットを Incremental にマークします。右上隅に青いバッジが表示されることで変更がわかります。
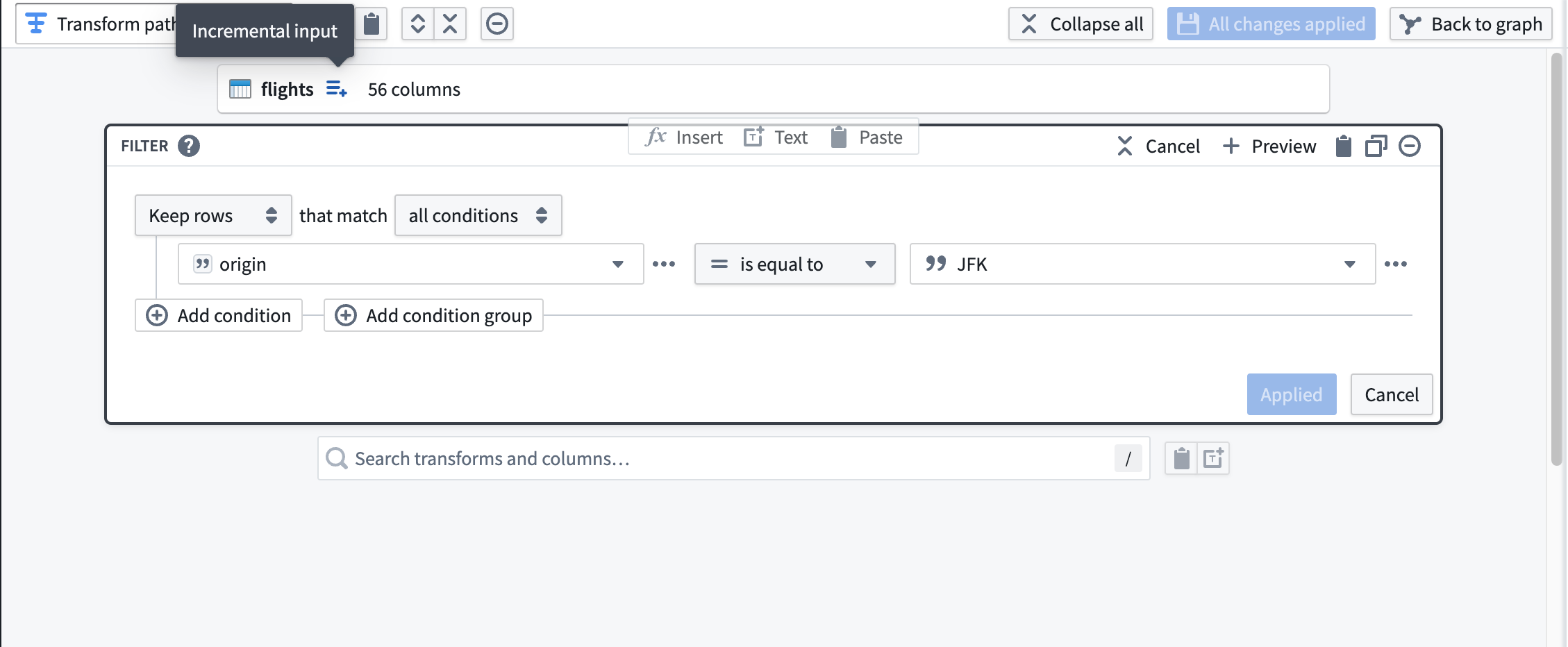
次に、JFK 空港を出発するフライトに flights をフィルター処理する変換を追加します。データセット入力の右にある Incremental input のツールチップでラベル付けされたアイコンに注意してください。下流の変換には、インクリメンタル処理されていることを示すこのアイコンが表示されます。
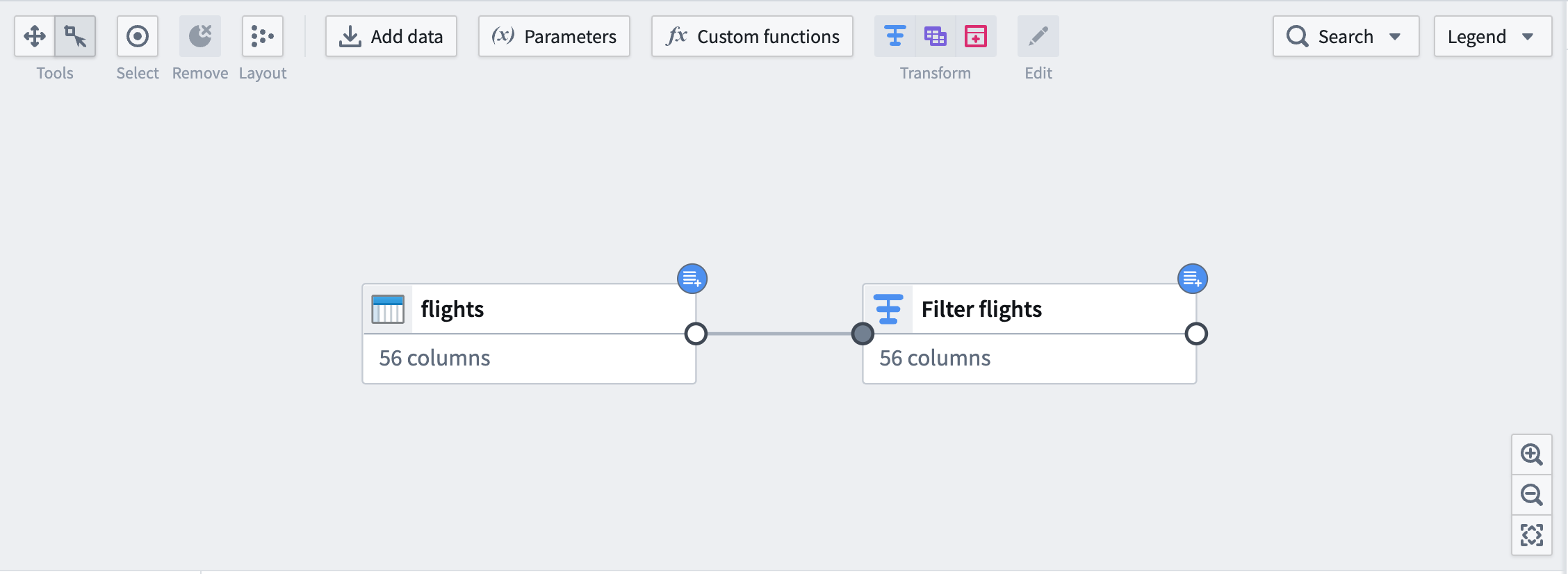
グラフ上では、下流のノードに入力と同じ青いバッジが表示されます。
最後に、出力データセット filtered_flights を追加します。
パート 4:出力データセットのデプロイ
これで、パイプラインをデプロイする準備が整いました。
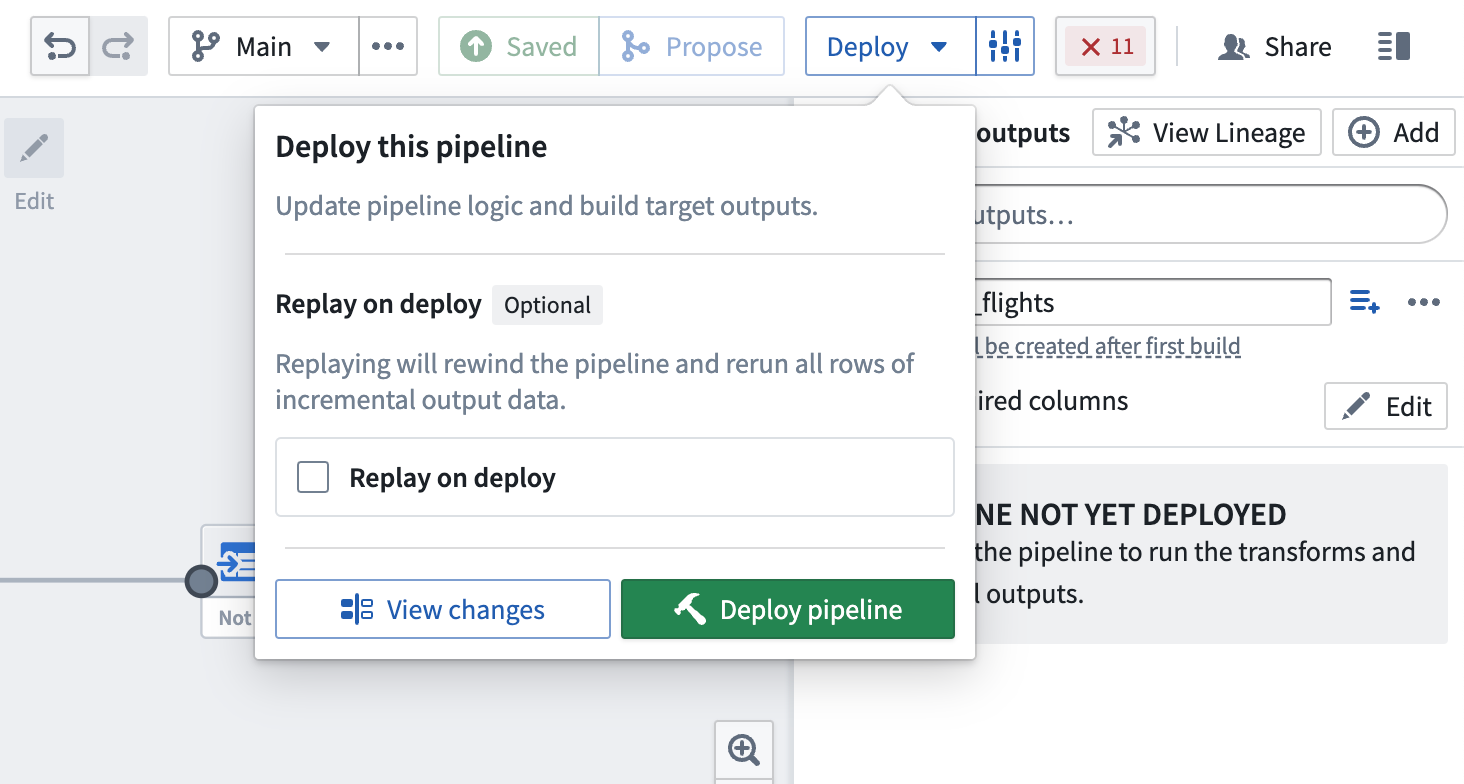
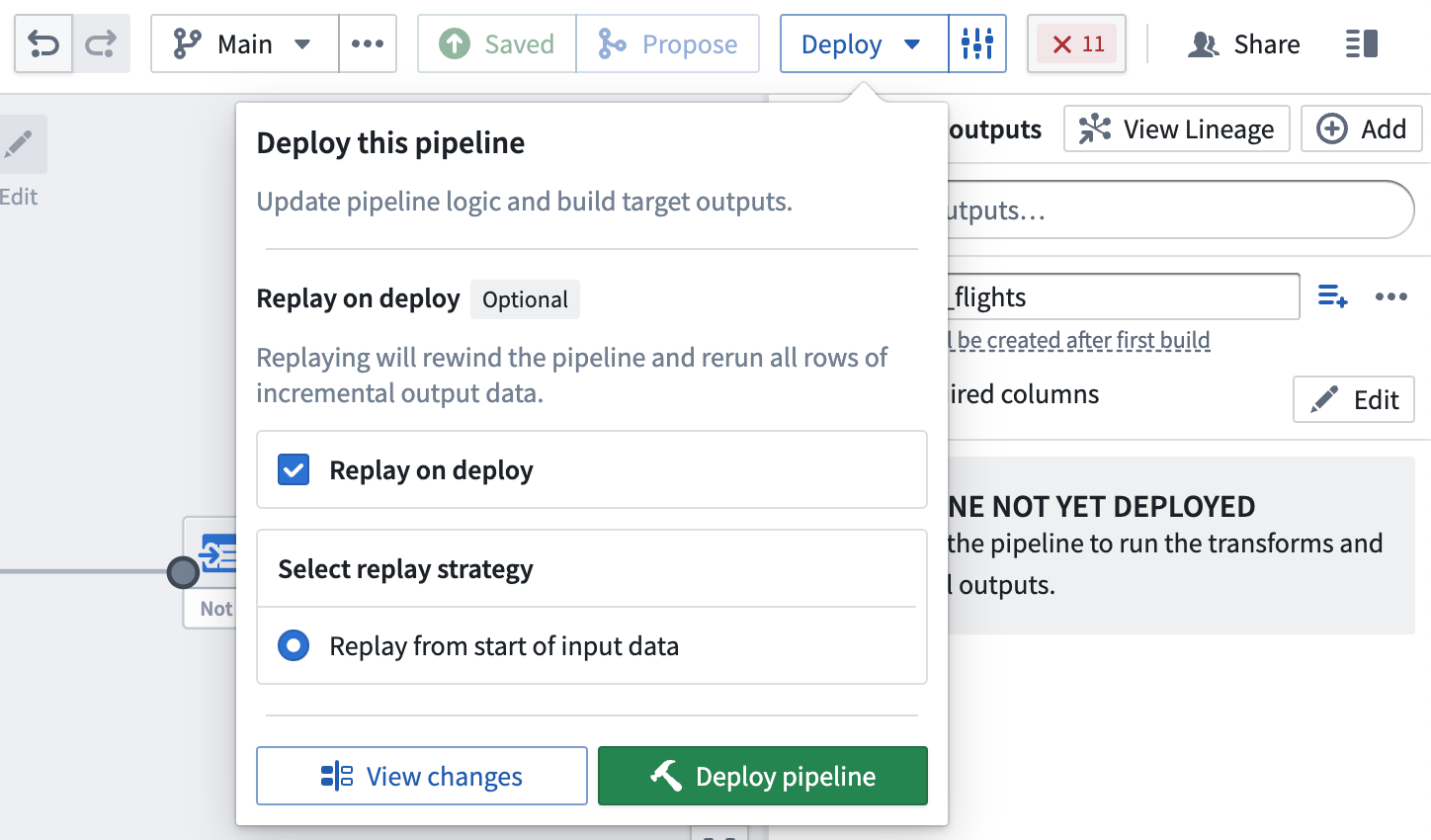
デプロイ時のリプレイ
場合によっては、以前の入力トランザクションを再処理する必要があります(たとえば、ロジックが変更され、以前のバージョンの出力データが古くなった場合)。このような場合、Replay on deploy を選択して、入力全体をパイプラインロジックに通すことができます。リプレイ後、パイプラインは入力に新しい追加トランザクションが追加されると、インクリメンタル計算を続ける必要があります。
デプロイ時のリプレイは、出力データセットに SNAPSHOT トランザクションを生成します。