注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Pipeline Builder を使用してメディアセットバッチパイプラインを作成する
このチュートリアルでは、Pipeline Builder を使用して、メディアセットを含む簡単なパイプラインを作成し、PDF からテキストを抽出します。
この例では、Palantir が公開している文書の PDF を使用します。
チュートリアルの最後には、以下のようなパイプラインができあがります。
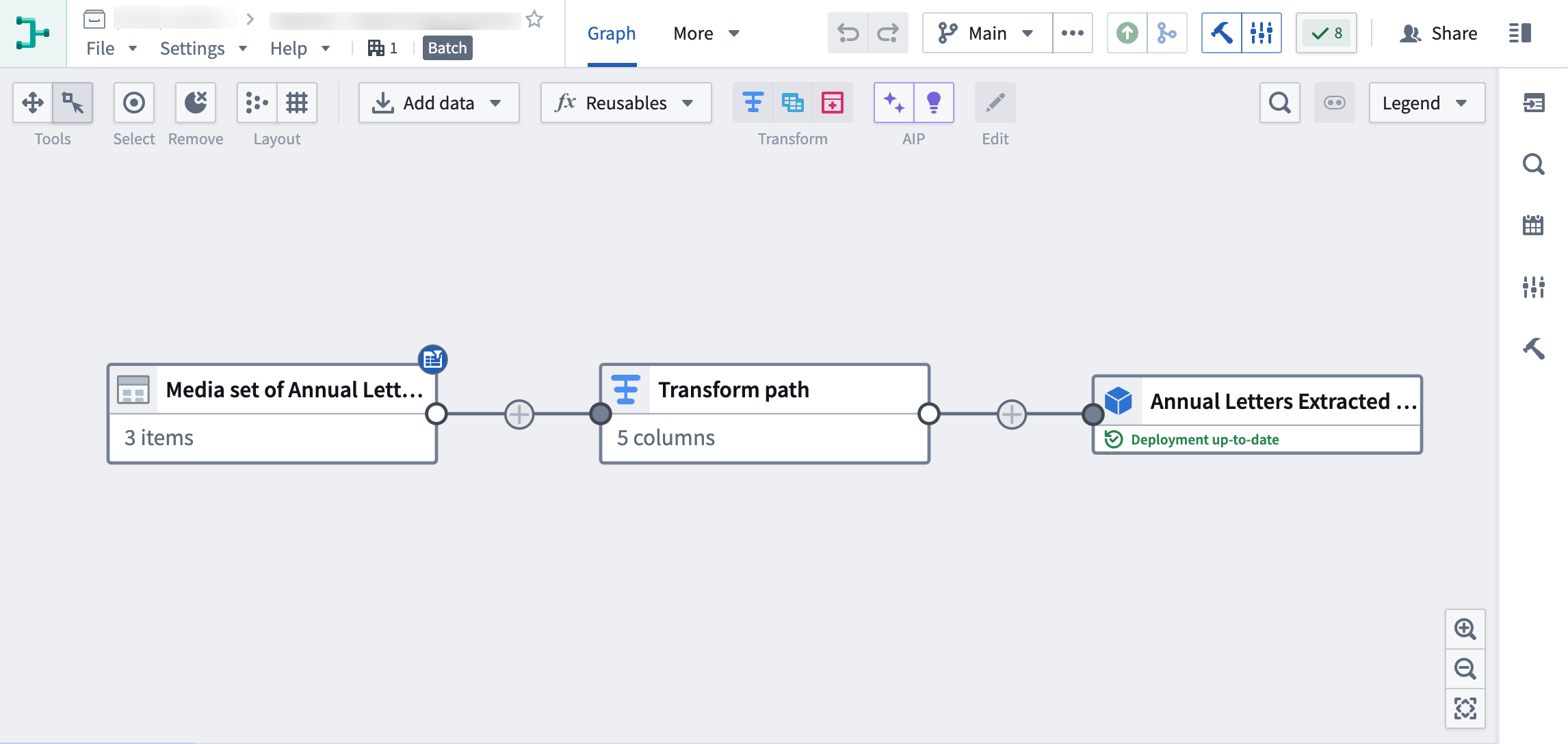
このパイプラインは、抽出された PDF テキストの新しいオブジェクト出力を生成し、さらなる探索に使用できます。
パート 1:初期設定
まず、新しいパイプラインを作成する必要があります。
-
Foundry にログインして、左のナビゲーションバーから Pipeline Builder にアクセスします。Pipeline Builder がアプリケーション一覧にない場合は、View all を選択し、Build & Monitor Pipelines セクションの下にある Pipeline Builder を探します。
-
次に、Pipeline Builder のランディングページの右上で、New pipeline を選択して新しいパイプラインを作成します。そして、Batch pipeline を選択します。
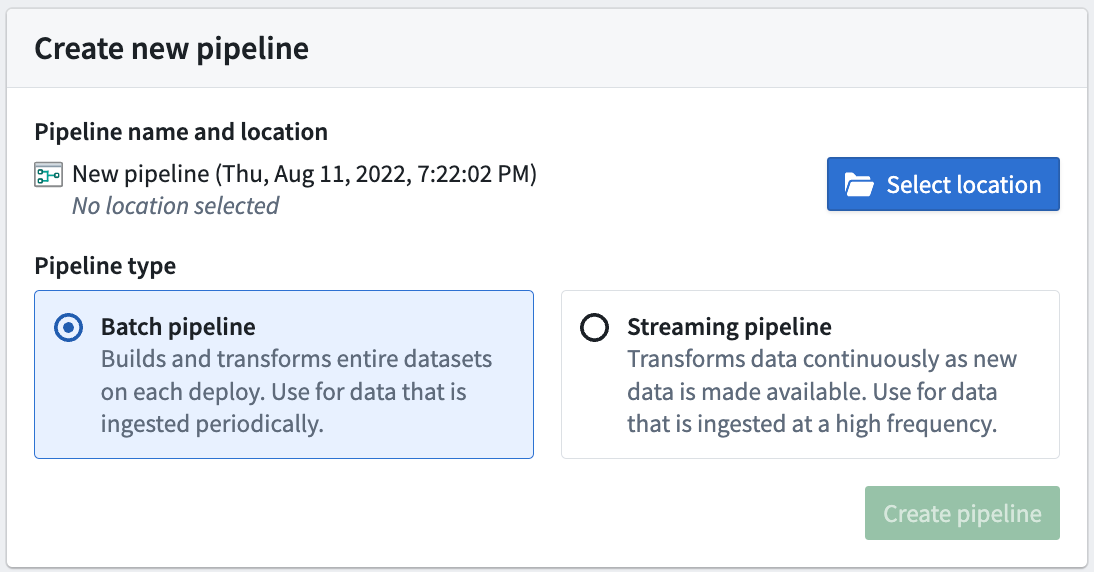
ストリーミングパイプラインを作成する機能は、すべての Foundry 環境で利用できるわけではありません。ユースケースでそれが必要な場合は、Palantir の担当者にお問い合わせください。
-
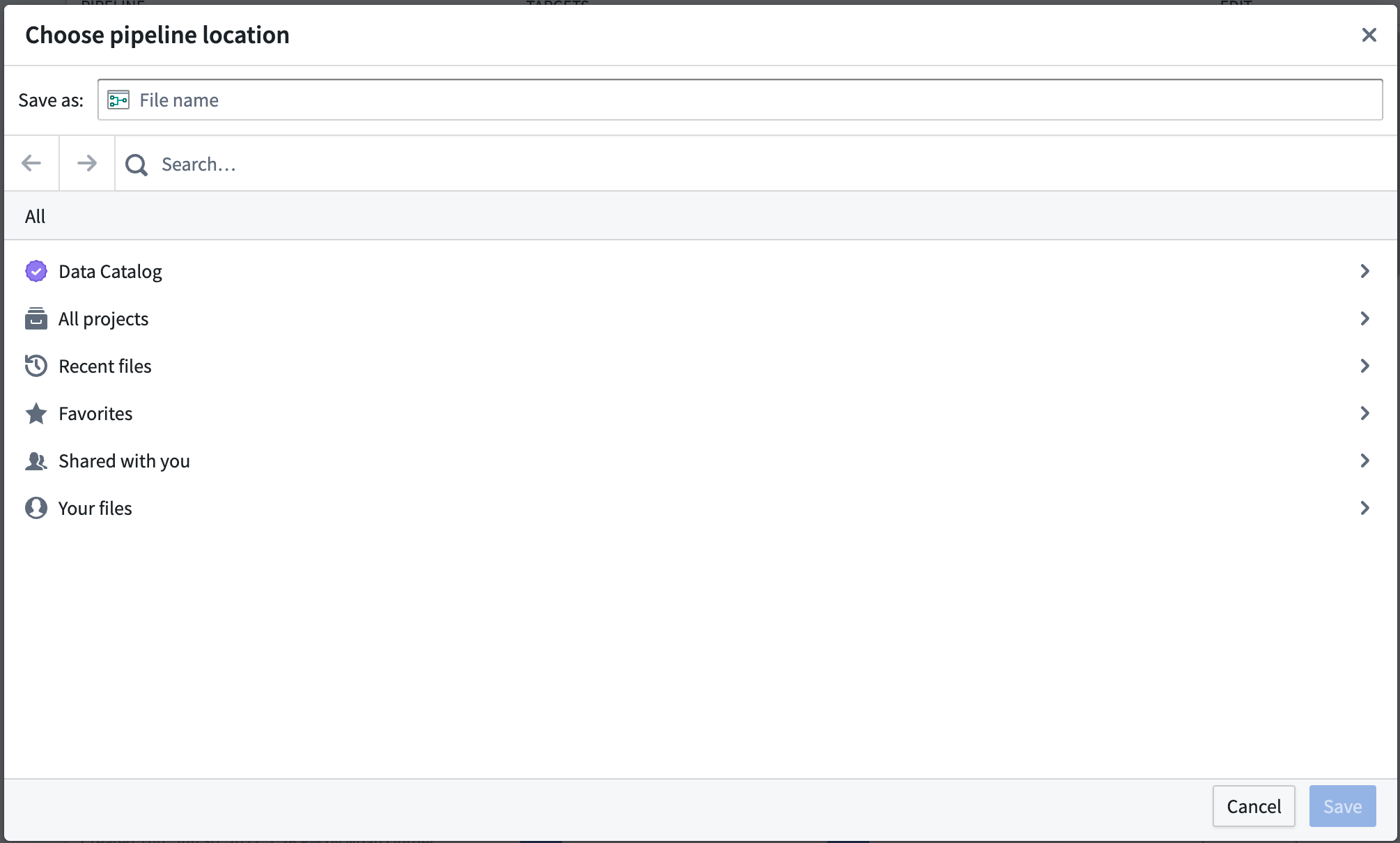
パイプラインを保存する場所を選択します。パイプラインは個人用フォルダーには保存できません。
-
Create pipeline を選択します。
パート 2:メディアセットの追加
これで、パイプラインワークフローにデータセットを追加できます。このチュートリアルでは、Palantir から公開されている文書の PDF を使用します。
-
Pipeline Builder ページから、ホームページの Add Foundry data を選択します。
上部のパネルで Add data アクションを選択することもできます。

また、コンピュータからファイルをドラッグアンドドロップしてメディアセットとして使用することもできます。
-
Add data または Add Foundry data を選択した場合、希望するメディアセットを選択するオプションが表示されます。
-
すべてのメディアセットが選択されたら、Add data を選択します。
-
メディアセットをインポートすると、サムネイルプレビューが表示されます。
パート 3:メディアセットの変換
生のメディアセットを追加した後、いくつかの基本的な変換を実行できます。このワークフローでは、これらの PDF ファイルからテキストを抽出します。
PDF からテキストを抽出する
まず、Media set of Annual Letters メディアセットを変換します。メディアセット内のメディアアイテムの media references を選択します。
メディアリファレンスの取得
-
グラフ内の
Media set of Annual Lettersノードを選択します。 -
Transform を選択します。

-
ドロップダウンから Convert media set to table rows 変換を検索して選択し、ボードを開きます。

-
Include timestampとDeduplicate by pathを選択するかどうかを選択します。
-
パイプラインに変換を追加するには、Apply を選択します。
-
出力は次のようになります。
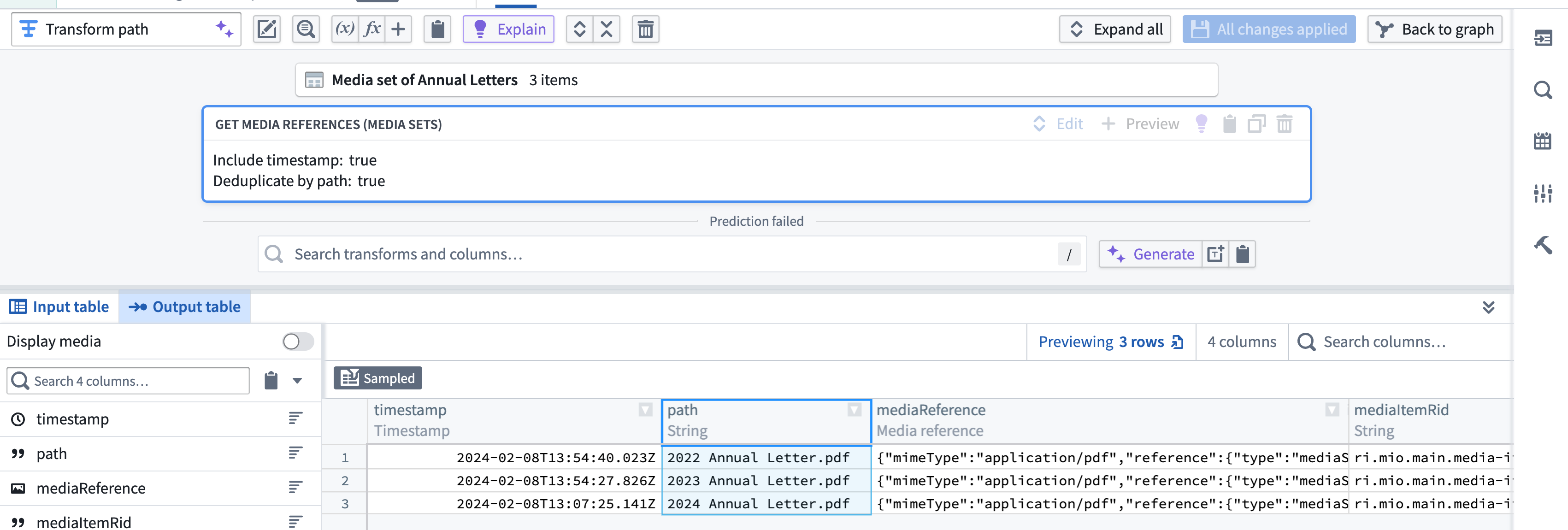
メディアリファレンスの例:
{"mimeType":"application/pdf","reference":{"type":"mediaSetItem","mediaSetItem":{"mediaSetRid":"ri.mio.main.media-set.xxx","mediaItemRid":"ri.mio.main.media-item.xxx"}}}メディアアイテム RID の例:
ri.mio.main.media-item.xxx-xxx-xxx-xxx-xxxx
テキストの抽出
-
メディアリファレンスがあるので、メディアリファレンスを利用した新しいボードを選択できます。ドロップダウンから Text Extraction 変換を検索して選択します。
-
抽出方法(
Raw text(PDF 解析)またはOCR)、Media Referenceカラム、OCR output format(OCR を選択した場合)、Languages/Scriptsを選択します。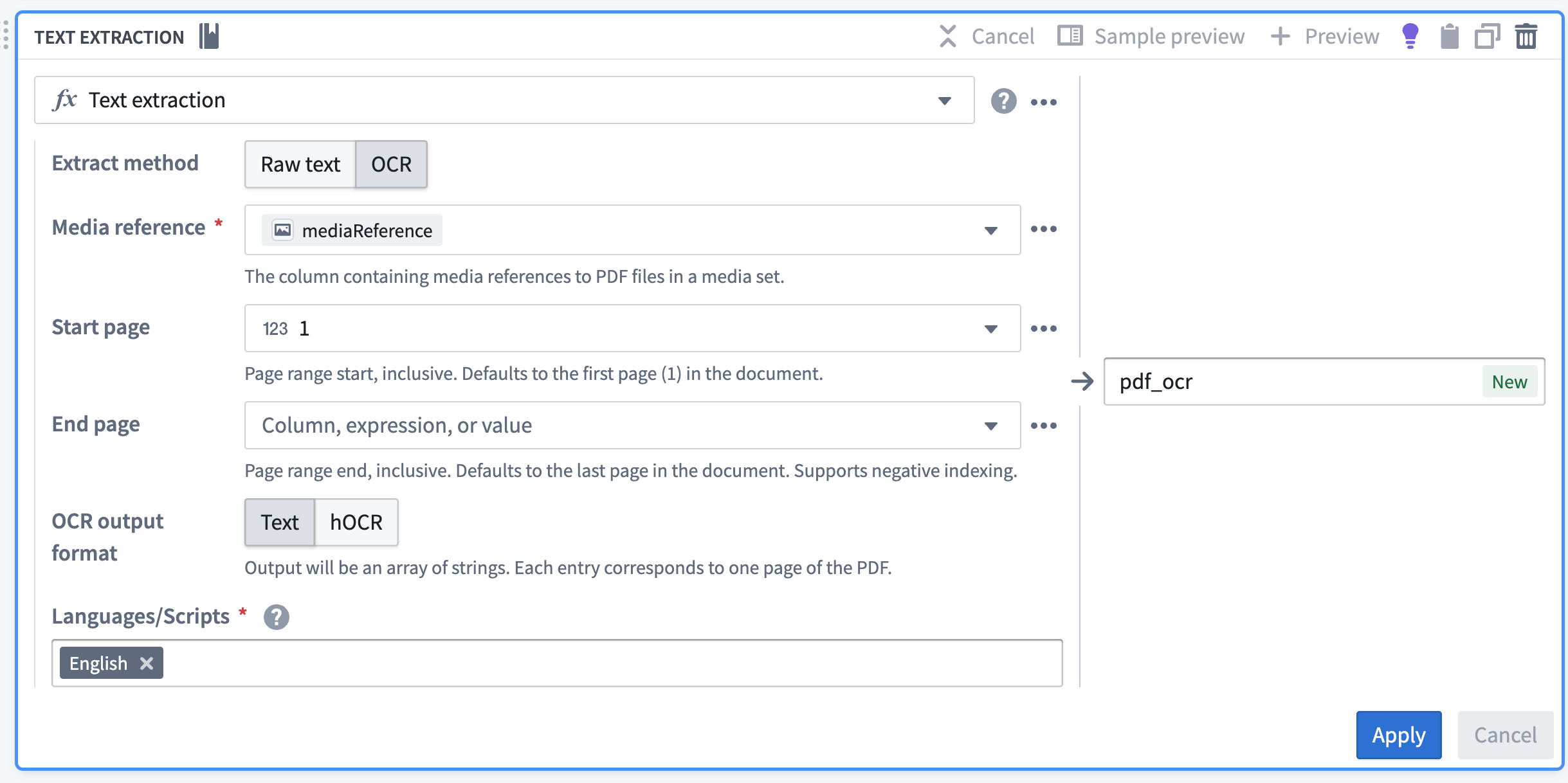
-
パイプラインに変換を追加するには、Apply を選択します。
-
抽出されたテキストにマウスを合わせると、出力は次のようになります。
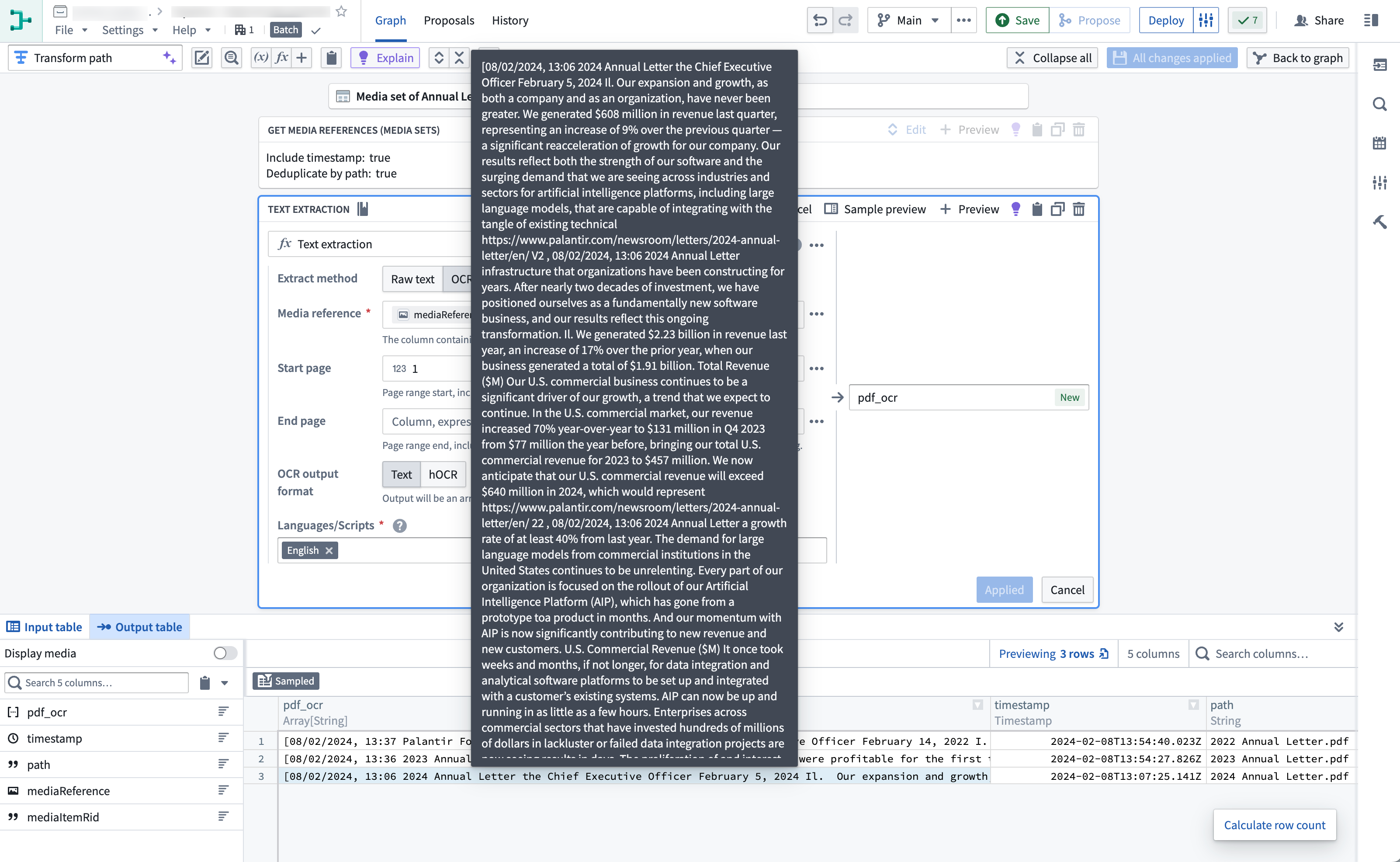
これで、抽出されたテキストカラムで利用可能な文字列変換を実行できます。
-
パイプライングラフに戻るには、右上の Back to graph を選択します。
(オプション)セマンティック検索ワークフロー
必要に応じて、抽出されたテキストでセマンティック検索ワークフローを実行できます。
パート 4:出力の追加
PDF からテキストを抽出し、追加の文字列変換を実行した後、出力を追加できます。このチュートリアルでは、オブジェクト出力を追加します。
-
変換を完了した
Transformsノードで、Add output を選択します。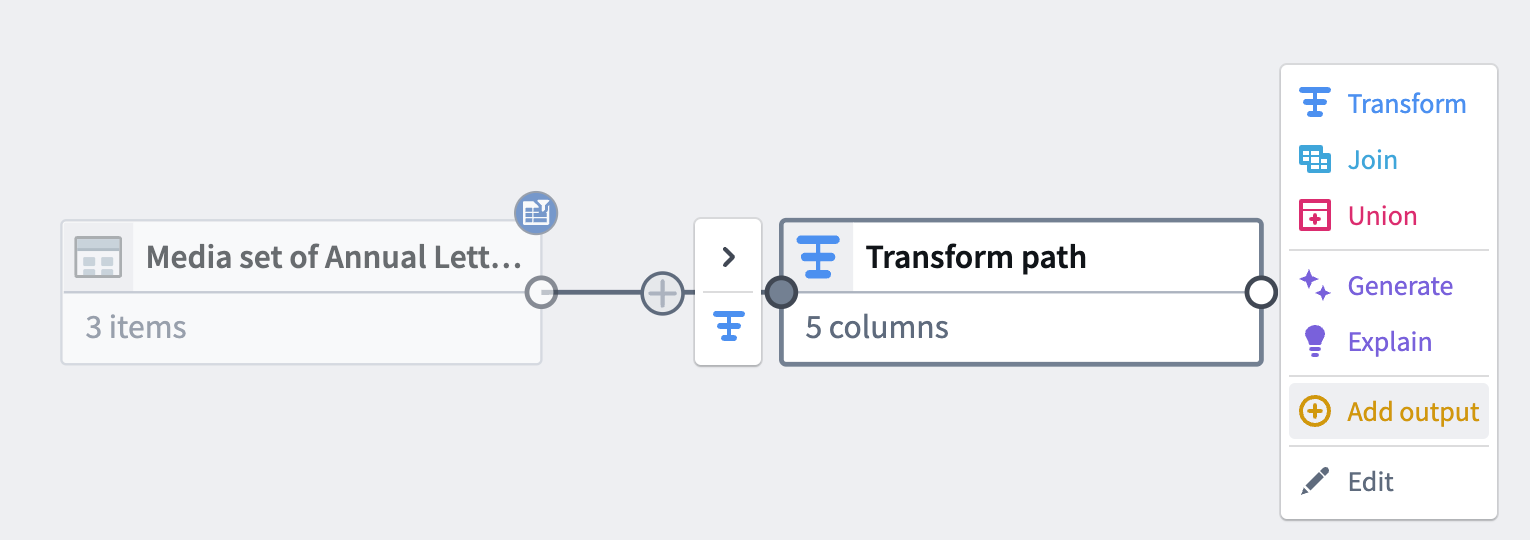
-
New object type を選択します。

-
オブジェクトタイプの名前を付けて、オントロジーを設定します。Please select an ontology を選択してください。
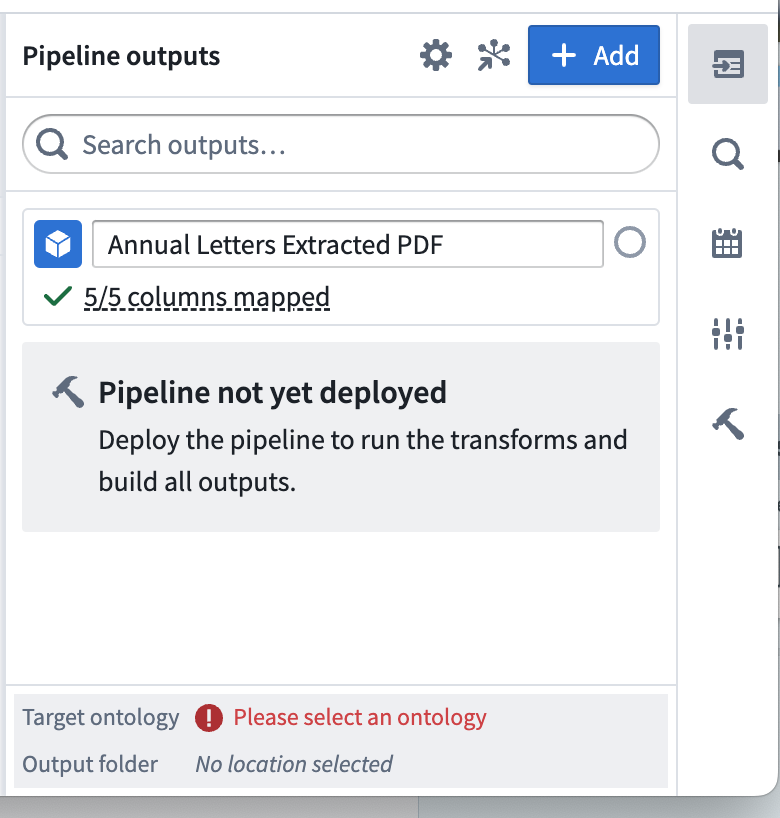
-
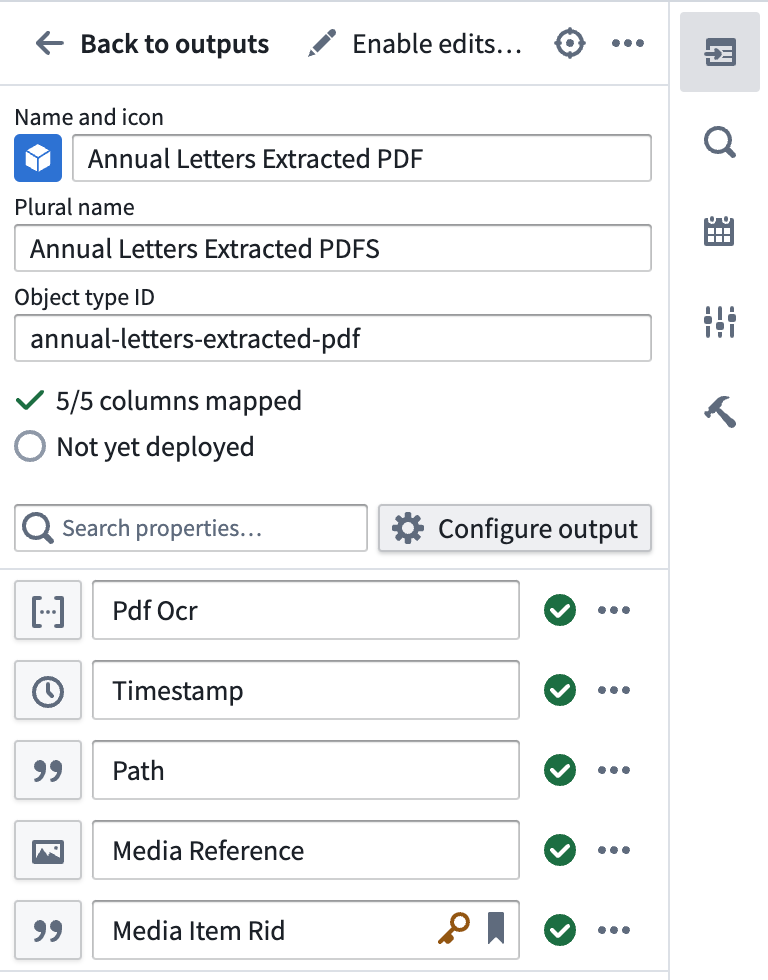
Edit を選択し、カラムマッピングを編集します。プライマリキーとして有効なカラムを選択してください。
パート 5:パイプラインの構築
-
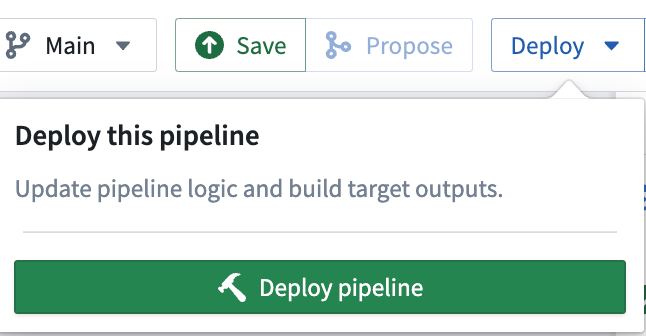
パイプラインを構築するには、Save を選択し、次に Deploy > Deploy pipeline を選択します。
-
Deploy Pipelineサイドバーオプションの下にIntializing deploymentが表示されるはずです。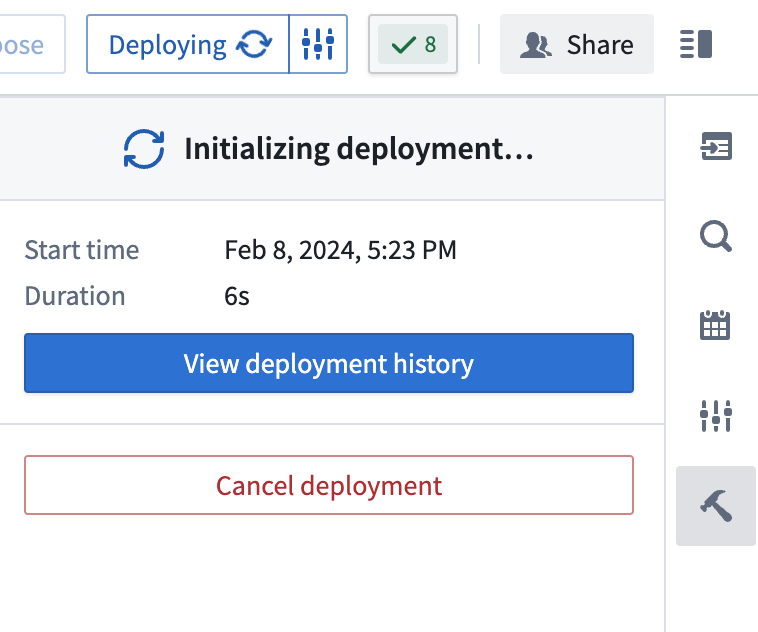
-
デプロイメントの進行状況を追跡するには、View deployment history を選択します。パイプラインの
Historyタブに移動し、デプロイメントのステータスと履歴を表示できます。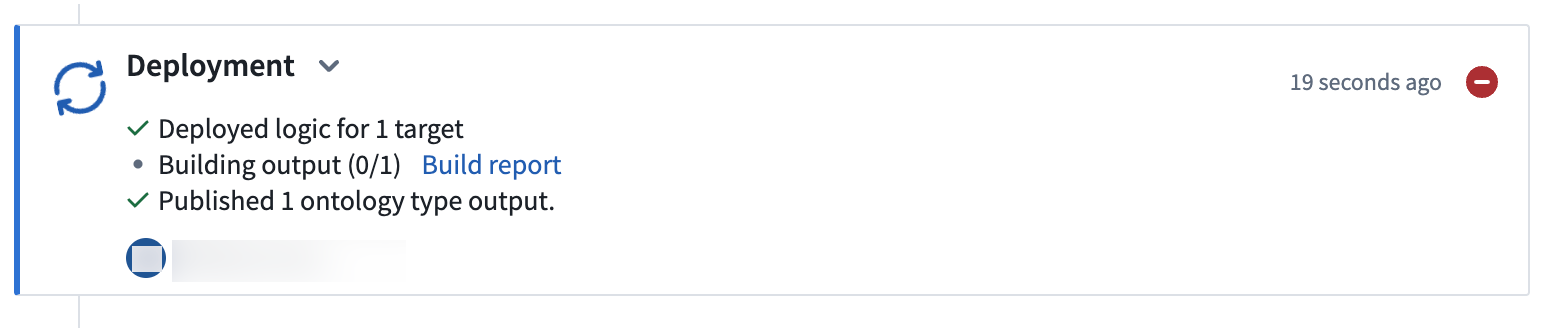
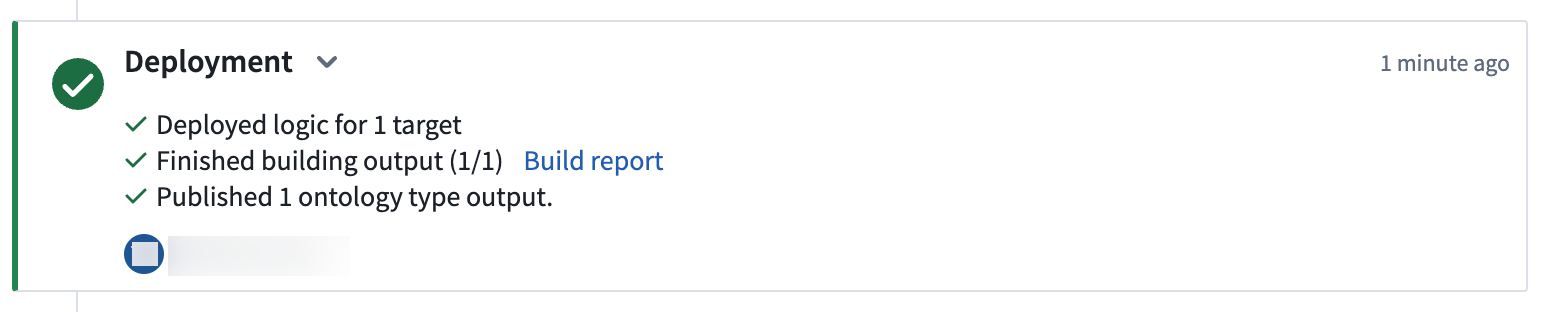
(オプション)パート 6:オントロジーの北
デプロイメントが完了し、オブジェクトが初期化されると、オブジェクト出力に直接アクションを実行できるはずです。パイプライン出力を含む Workshop モジュールを生成するには、Create Workshop module を選択します。
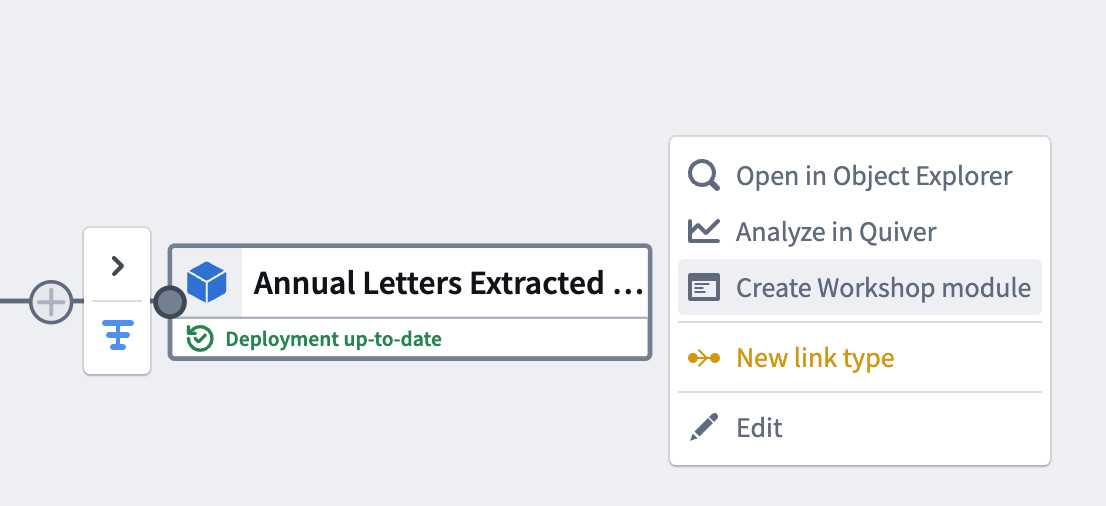
この最後のステップで、パイプライン出力を生成し、Workshop モジュールを生成しました。