注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
コードリポジトリを使用してメディアセットバッチパイプラインを作成する
このガイドでは、Code Repositories アプリケーションを使用した簡単な変換例を説明します。メディアセットを使用して Python コードを作成および編集する方法を学びます。
1. リポジトリを作成する
新しいリポジトリを作成して始めます。 Foundry の Project に移動し、右上の + New を選択し、Code repository を選択します。
このガイドでは、Python トランスフォームを作成します。リポジトリに名前を付け、Language template のドロップダウンメニューで Python を選択します。次に、Initialize repository を選択します。
2. データをインポートする
既に取り込むための生のメディアセットをインポートしている場合は、次のステップに進んでください。それ以外の場合は、Foundry にメディアをインポートする方法 に関するメディアセットガイドを参照してください。
3. transforms-media ライブラリをインポートする
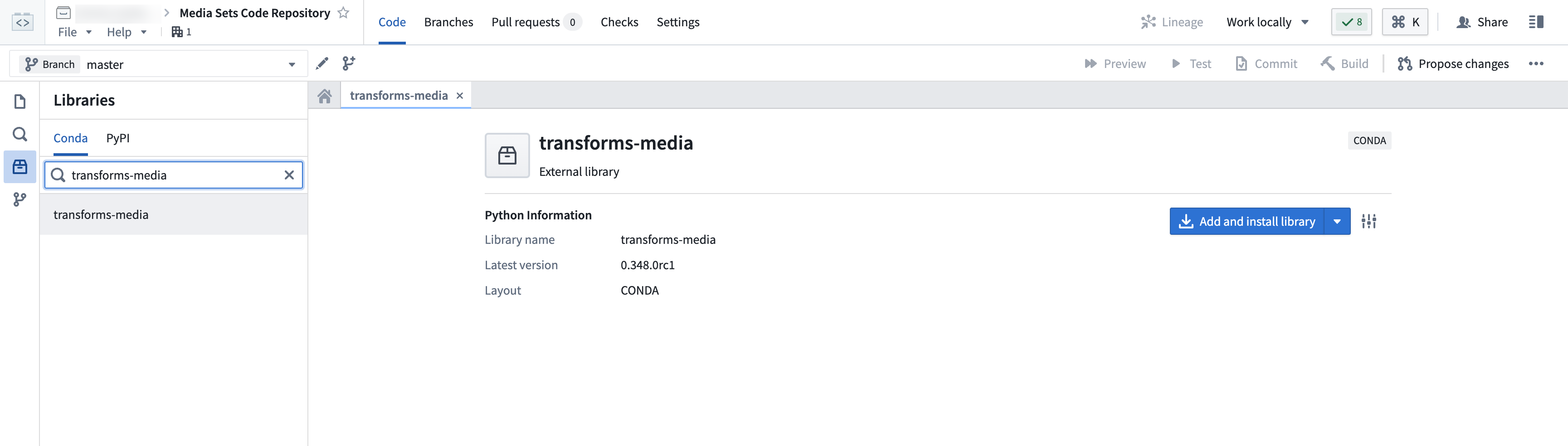
メディアセット変換を使用するには、transforms-media ライブラリをインポートする必要があります。
左サイドバーの Libraries オプションに移動し、transforms-media ライブラリを検索して選択します。次に、Add and install library を選択します。
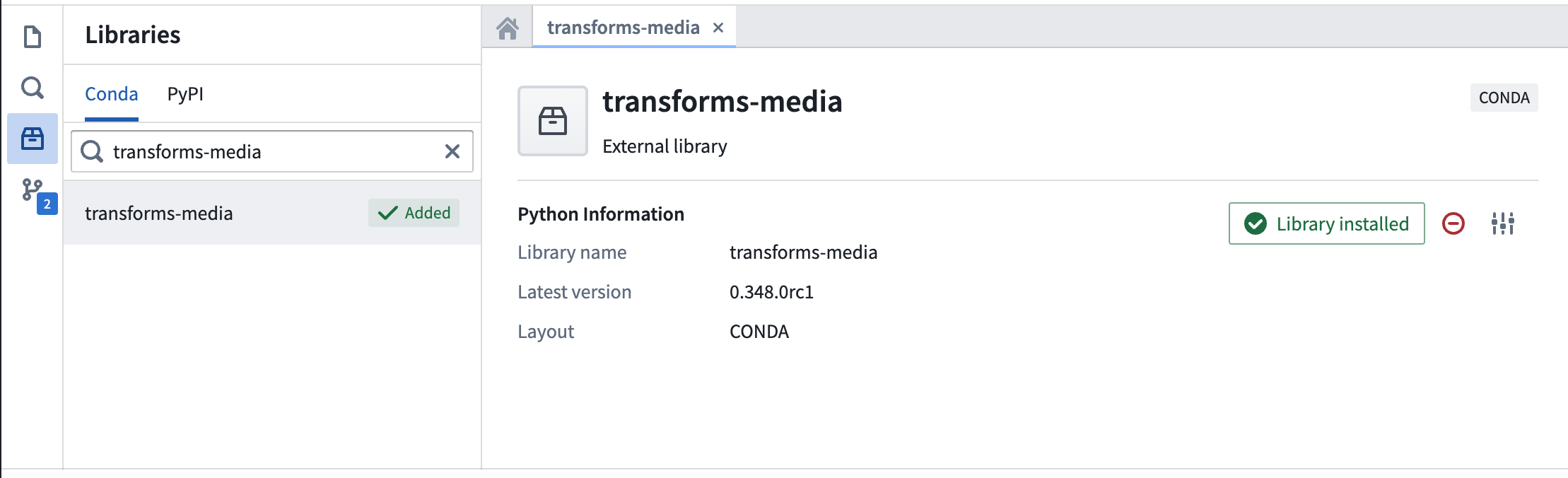
インストールが完了すると、ステータスは Library installed と表示されます。
4. コードを編集する
新しいファイルを作成する
Python トランスフォームリポジトリを作成すると、examples.py ファイルが自動的に生成されます。これをベースに使用できます。ファイル名を変更するには、省略記号アイコンを選択し、Rename を選んでファイルに適切な名前を付けます。
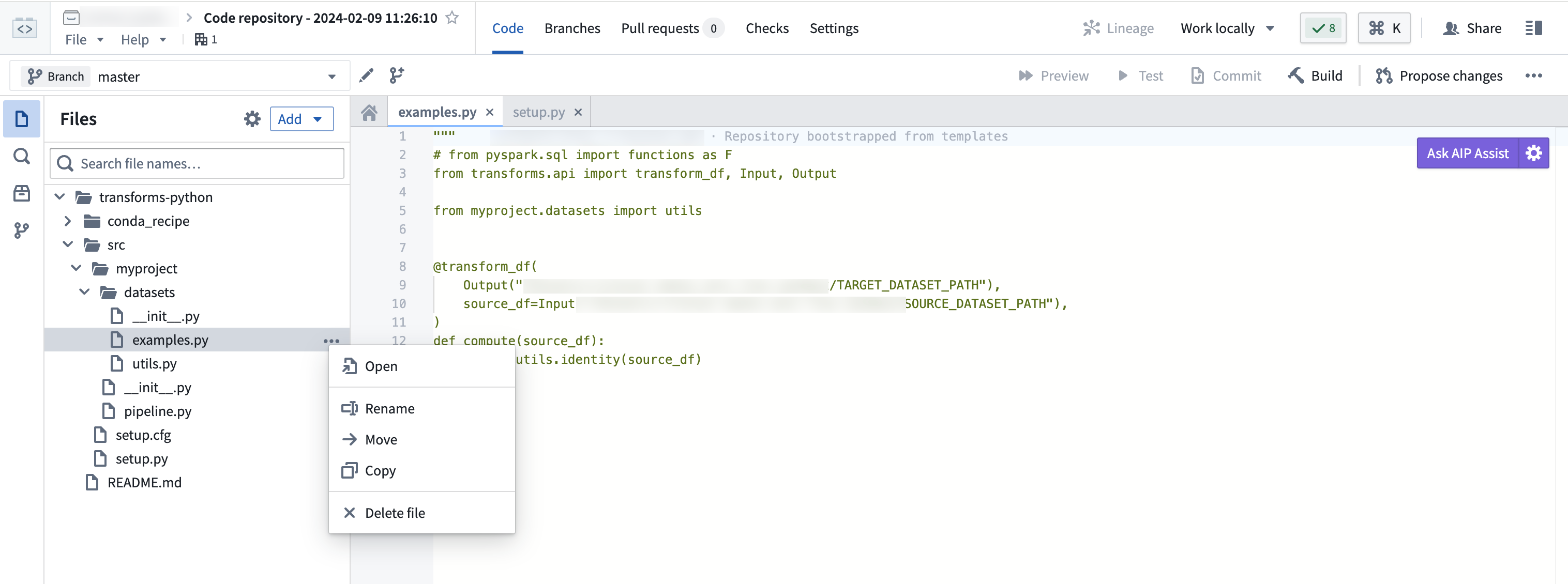
新しいファイルを作成するには、省略記号アイコンを選択し、Datasets ディレクトリの下で New file を選択します。このワークフローに必要な Python ファイルを作成していることを確認してください。
ファイルに適切なライブラリをインポートする
メディアセットを操作する場合、@transform デコレーターを使用する必要があります。メディアセットの入力と出力は、transforms.mediasets.MediaSetInput および transforms.mediasets.MediaSetOutput 仕様を使用して渡す必要があります。
Copied!1 2 3 4 5 6 7 8 9 10 11# transforms.apiからtransformをインポートします from transforms.api import transform # transforms.mediasetsからMediaSetInputとMediaSetOutputをインポートします from transforms.mediasets import MediaSetInput, MediaSetOutput # transformデコレータを使用します。これにより、以下に定義された関数は変換として扱われます @transform( # imagesは'/examples/images'パスからメディアセットを入力として受け取ります images=MediaSetInput('/examples/images'), ... )
出力ファイルが存在することを確認する
メディアセットの出力ファイルを作成している場合は、トランスフォームデコレータで参照する前に、ファイルを作成しておく必要があります。
このファイルは、プロジェクトフォルダー(Pythonトランスフォームのコードリポジトリを最初に作成した場所)に移動して、ドロップダウンメニューから 新規 > メディアセット を選択することで作成できます。
get_media_item()、get_media_item_by_path()、または list_media_items_by_path_with_media_reference() を使用する
メディアセット内の各メディアアイテムを変換するためには、get_media_item() または get_media_item_by_path() を使用して、変換の中でこれらのメディアアイテムを参照する必要があります。
get_media_item()、get_media_item_by_path() への呼び出しは、Pythonのファイルライクなストリームオブジェクトを返すことに注意してください。io.open()(外部)で受け付けられるすべてのオプションもサポートされています。アイテムはストリームとして読み込まれるため、ランダムアクセスはサポートされていません。
メディアアイテムを以下のように1つずつ参照することができます。
Copied!1 2 3 4 5 6 7 8 9 10 11from transforms.api import transform from transforms.mediasets import MediaSetInput, MediaSetOutput # transformデコレーターを使用して、画像を入力として受け取り、出力として別の画像を生成する関数を定義します。 @transform( images=MediaSetInput('/examples/images'), # '/examples/images' パスからメディアセットを読み込みます output_images=MediaSetOutput('/examples/output_images') # '/examples/output_images' パスにメディアセットを出力します ) def translate_images(images, output_images): image1 = images.get_media_item_by_path("image1") # パスを使用してメディアアイテムを取得します image2 = images.get_media_item("ri.mio.main.media-item.123") # RIDを使用してメディアアイテムを取得します
しかし、多くの場合、メディアセット内のすべてのメディアアイテムをデータフレームにまとめてリスト化したいでしょう。list_media_items_by_path_with_media_reference() を使用してメディアアイテムをリスト化する必要があります:
Copied!1 2 3 4 5 6 7 8 9 10 11from transforms.api import transform, Output from transforms.mediasets import MediaSetInput @transform( images=MediaSetInput('/examples/images'), listing_output=Output('/examples/listed_images') ) def translate_images(ctx, images, listing_output): # メディアアイテムをパスとメディア参照と共にリスト化します media_items_listing = images.list_media_items_by_path_with_media_reference(ctx) # リスト化された出力でPySparkの任意の関数を実行することができます
リストには以下のスキーマが適用されます:
+--------------------------+-----------+-------------------+
| mediaItemRid | path | media_reference |
+--------------------------+-----------+-------------------+
| ri.mio.main.media-item.1 | item1.jpg | {{reference1}} | // メディア項目1のリファレンス
| ri.mio.main.media-item.2 | item2.jpg | {{reference2}} | // メディア項目2のリファレンス
| ri.mio.main.media-item.3 | item3.jpg | {{reference3}} | // メディア項目3のリファレンス
+--------------------------+-----------+-------------------+
例:PDFメディアセットを新しいPNGメディアセットに変換する
この例では、PDFメディアセット内のすべてのメディアアイテムをループ処理し、それらをPNGイメージとして保存します。
入力例:
list_media_items_by_path_with_media_reference() がデータフレームを返すことに注意してください。これにより、出力に対してPySpark関数を実行することができます。この例では、mediaItemRid 行の値を配列としてループ処理して収集しています:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23# 必要なモジュールをインポートします from transforms.api import transform from transforms.mediasets import MediaSetInput, MediaSetOutput # transformデコレータを使用して関数を定義します # pdfsは入力メディアセットを指定し、output_pngsは出力メディアセットを指定します @transform( pdfs=MediaSetInput('INPUT_MEDIA_SET_PATH'), output_pngs=MediaSetOutput('OUTPUT_MEDIA_SET_PATH') ) def upload_images(ctx, pdfs, output_images): # pdfからメディアアイテムリストを取得します media_items_listing = pdfs.list_media_items_by_path_with_media_reference(ctx) # RDD (Resilient Distributed Dataset)のmap関数を使って、各メディアアイテムのRIDを取得し、リストにまとめます rid_list = media_items_listing.rdd.map(lambda x: x.mediaItemRid).collect() # RIDリストの各要素に対して次の操作を行います for rid in rid_list: # 指定したページのPDF文書をPNG画像に変換します output_png = pdfs.transform_document_to_png(rid, 0) # 変換したPNG画像をメディアアイテムとして出力します。その際、ファイル名には "PNG_" をプレフィックスとして付けます output_images.put_media_item(output_png, "PNG_"+rid)
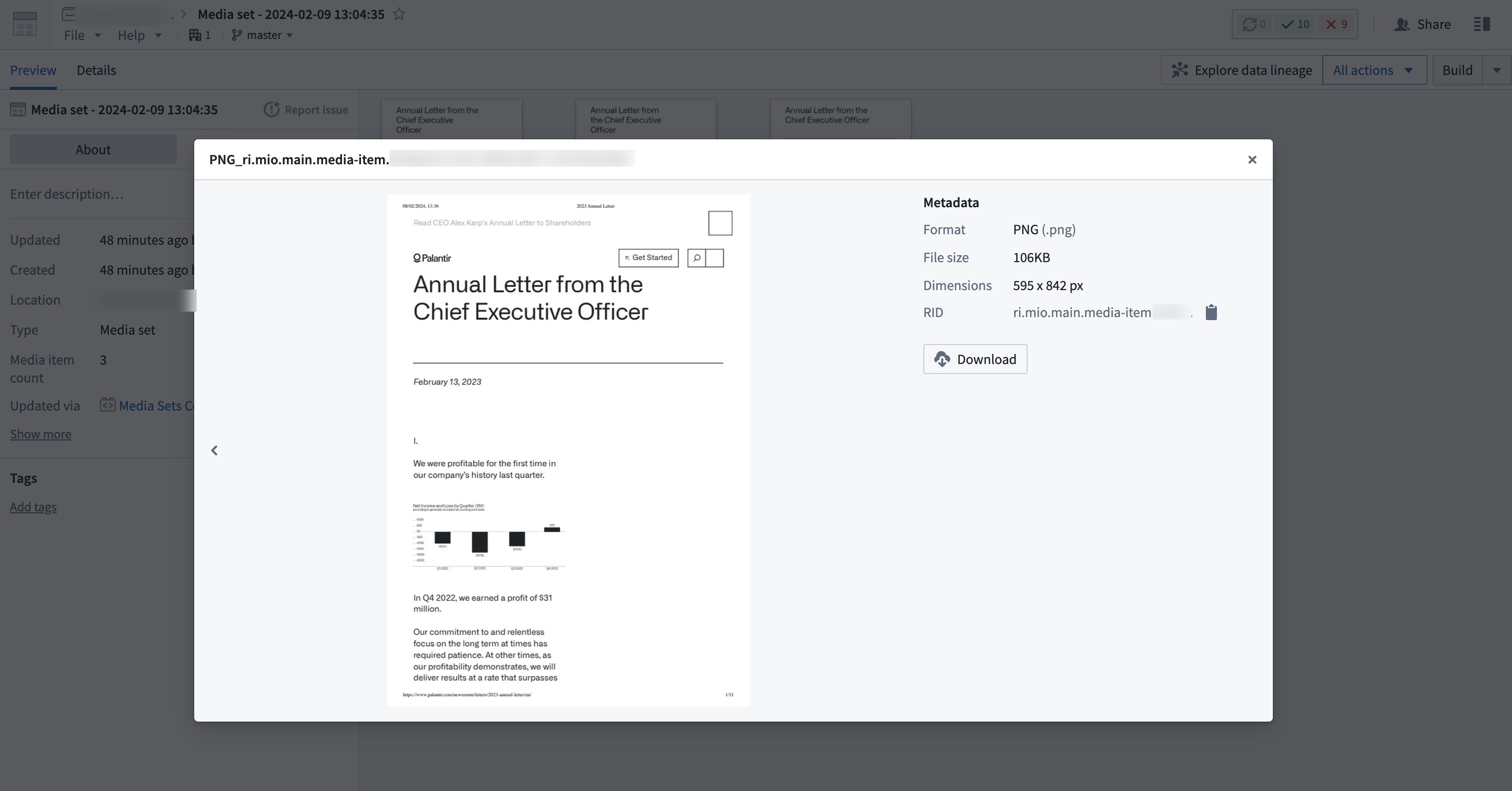
これにより、メタデータプロパティから判断するとPNGファイルを含む出力メディアセットが生成されます:
使用可能な既製の変換のリストをドキュメンテーションで確認してください。
4. ユーザーの変更をテストする
Foundryでは、メディアセットをコードリポジトリと同様にブランチ化することができます。ブランチ化は、マルチステップのデータパイプラインのデザインをテストするのに便利です。例えば、ユーザーのブランチに依存しない下流の依存関係を壊さずに、データパイプラインの一部に対する変更を単独でテストできます。
データ変換コードを書き終えたら、行った変更をテストする必要があります。テストにより、変更をマージする前にコードが期待通りに動作していることが確認できます。
5. ユーザーの変更をコミットする
現在、ユーザーはCode Repositoriesで変更をコミットし、行った作業をラベル付けすることができます。コミットを行う前に、ユーザーの作業はデフォルトで自動保存されます。コミットは、停止点に達したときに変更のセットを具体的にラベル付けします。
Commit ボタンを選択して変更をコミットし、コードに自動チェックを行います。Build ボタンを選択すると、変更がコミットされ、自動コードチェックが行われ、出力データセットのビルドが開始されます。データセットをビルドせずに変更を迅速にテストし、コードがチェックを通過することを確認するには、Commit を選択します。それ以外の場合は、データセットをビルドするに進むことができます。
6. 変更をマージし、ビルドする
新しいメディアセット出力に満足したら、共同作業者と協力して変更をマージ、ビルド、表示します。