注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
コードリポジトリを使用してバッチパイプラインを作成する
このガイドでは、コードリポジトリアプリケーションを使用したシンプルなデータ変換の例をユーザーに説明します。ユーザーはSQLコードの記述と編集、およびデータセットの作成方法を学びます。また、ユーザーはブランチで作業することで、同僚とのコラボレーションを可能にします。
1. リポジトリの作成
新しいリポジトリを作成して始めましょう。Foundry の Project へ移動し、右上の + New を選択し、次に Code repository を選択します。
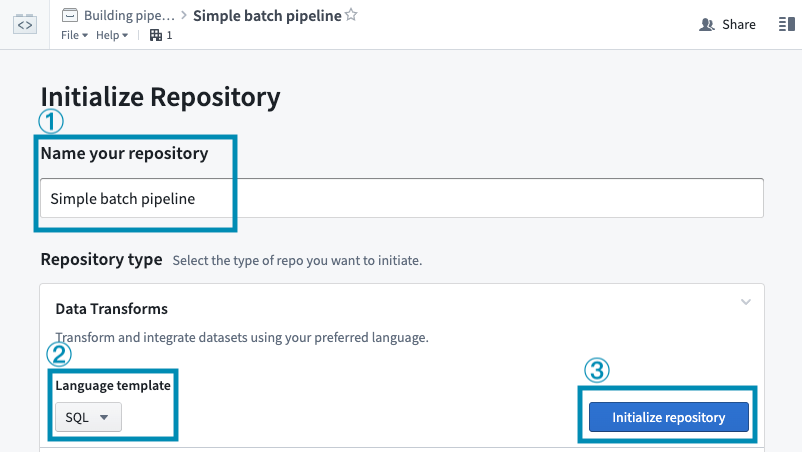
このガイドでは、SQL変換を記述します。リポジトリに名前を付け、 Language template の下のドロップダウンから SQL を選択します。次に、Initialize repository を選択します。
2. データのインポート
すでに作業する生のデータセットをインポートしている場合は、次のステップに進めます。それ以外の場合は、以下のサンプルデータセットをダウンロードできます:
このデータセットをリポジトリと並べてプロジェクトにアップロードする方法については、manual data uploads のガイドを参照してください。
3. ブランチの作成
ユーザーは個人の ブランチ を作成して変更を加えることで、マスター版のコードを直接編集するのではなく、同僚と安全にコードリポジトリで共同作業を行うことができます。変更を追跡し、元に戻すことができ、マスターコードに変更をマージすることも可能です。コードは行ごとにレビューすることができ、そのため、プロダクションパイプラインへの変更はチームメイトの間で容易に議論することができます。Foundryでのブランチングについて詳しく知るには、このページ をご覧ください。
コードリポジトリに移動すると、デフォルトで master ブランチになります。master ブランチを保護することがベストプラクティスであり、これはそのブランチ上で直接コードを編集することはできないことを意味します。保護されたブランチ上のファイルは読むことができますが、編集や作成はできません。
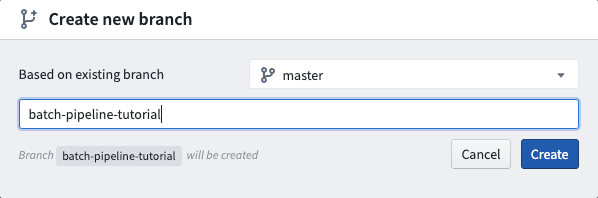
ユーザーがコードリポジトリに変更を加える前に、まず自分自身のブランチを作成する必要があります。このブランチには master ブランチのコードのコピーが含まれます。ブランチを作成するには、現在のブランチ名の隣にある ![]() アイコンをクリックします。
アイコンをクリックします。
これにより、既存のブランチの選択と新しいブランチのカスタム名の選択のためのダイアログが開きます:
新しいブランチを作成した後、左側に同一のファイルツリーが表示されます。ユーザーは単に、ユーザーが開始した master ブランチのコードのコピーを作成しただけです。ユーザーは今、ブランチ内のファイルを編集できます。
4. コードの編集
新しいファイルの作成
ユーザーのブランチで作業をしているので、フォルダーにマウスを置くと表示される省略記号アイコンをクリックして新しいSQLファイルを作成し、次に New file を選択します。New file を選択すると、ファイルの種類を選択し、名前を付けるように求められます。この例では、SQL Transformation を選択し、ファイル名(スペースや特殊文字は含めない)を選択します:
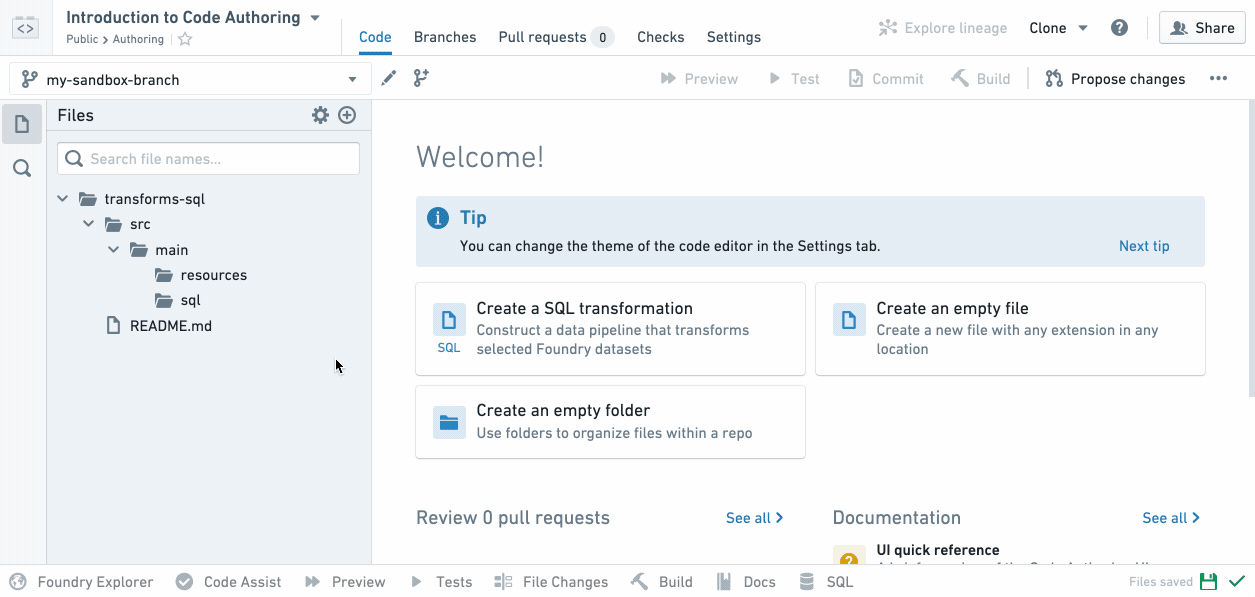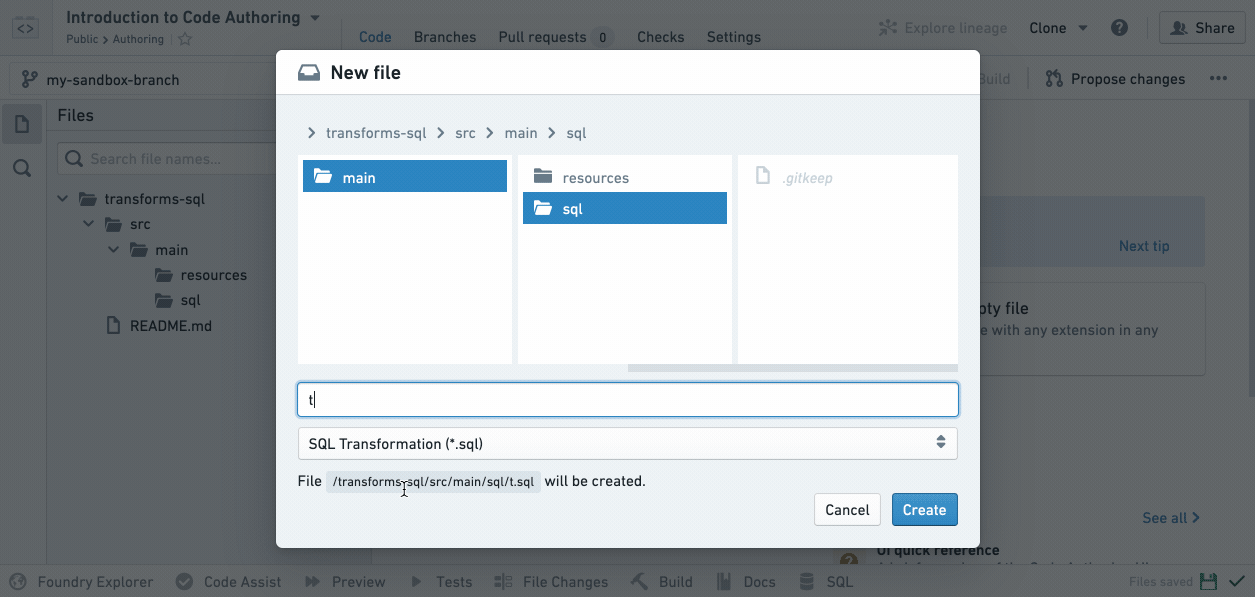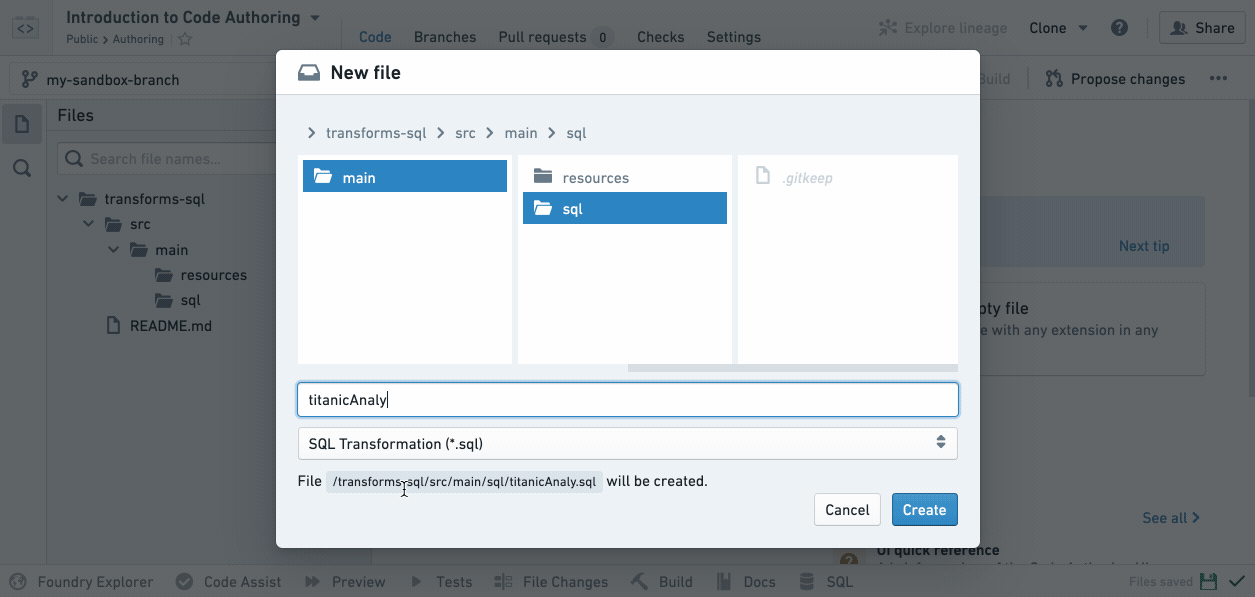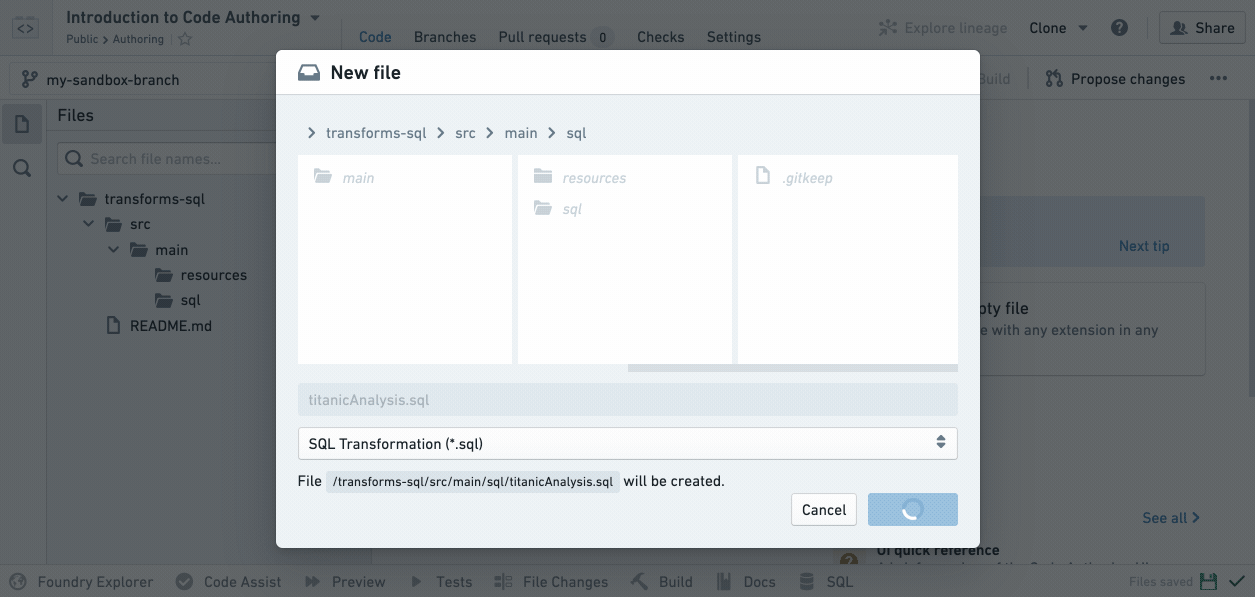
新しいSQLファイルがファイルツリーでハイライト表示されていることに注意してください。これは、ユーザーがそれをビルドしたときに結果のデータセットが存在する位置を示しています。
ファイルツリーでファイル名が緑色になっている場合、それはユーザーがブランチで新しく作成したファイルであり、ユーザーが開始したマスターブランチには存在しません。ファイル名がオレンジ色の場合、それは master 上に存在するファイルで、ユーザーのブランチで変更が加えられたことを意味します。
新しく作成した .sql ファイルは、ユーザーが提供したファイル名に基づいて出力データセットを宣言します。例えば、リポジトリが /Public/Authoring 内にある場合、titanicAnalysis.sql を作成すると、新しいファイルは自動的に出力データセット /Public/Authoring/titanicAnalysis を宣言します。
ファイルの編集
次に、プレースホルダーのテキストを実際のデータ変換コードに置き換えます。まず、`SOURCE_DATASET_PATH` を実際の入力データセットへのパスに置き換えます。この例では、このチュートリアルのステップ (2) でインポートした titanic データセットを使用します。
バックティックを入力すると、ユーザーが使用できるデータセットをリスト表示するインタラクティブなメニューが自動補完により表示されることに注意してください。リストからデータセットを選択すると、データセットの参照はデータセットの一意のIDに置き換えられます。これにより、データセットが後で移動されても、変換コードは引き続き動作します。
バックティック内にプロジェクトの名前を入力し、titanic データセットを見つけ、メニューから選択します。
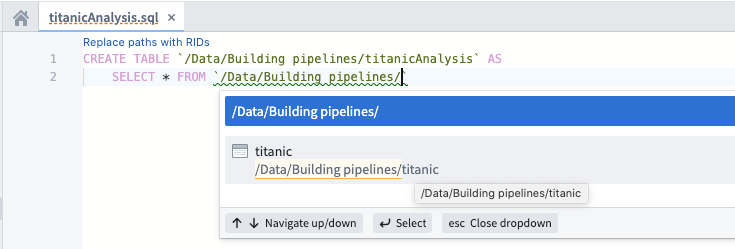
データに変換を適用するためにSQLコードを記述し続けます。SQL関数を入力すると、さまざまなヘルプダイアログが表示されます。例えば、"titanic" データセットの乗客の性別を一文字で省略した新しい列を作成したいとします。SUBSTRING 関数の使用方法についての情報を表示できます:
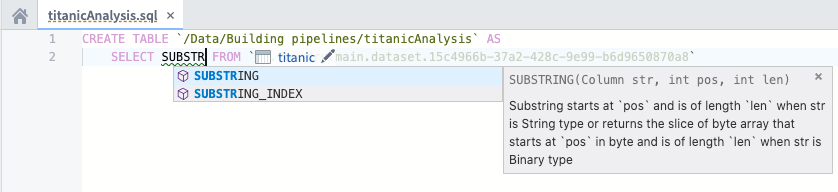
次に進む前に、"Name"、"Age"、"Survived"、"Ticket" の列と、"Gender" という名前の派生列を選択するデータ変換コードを書き終えます。"Gender" 列は乗客の省略された性別を表し、この列を作成するためには "Sex" 列に SUBSTRING 関数を呼び出します。
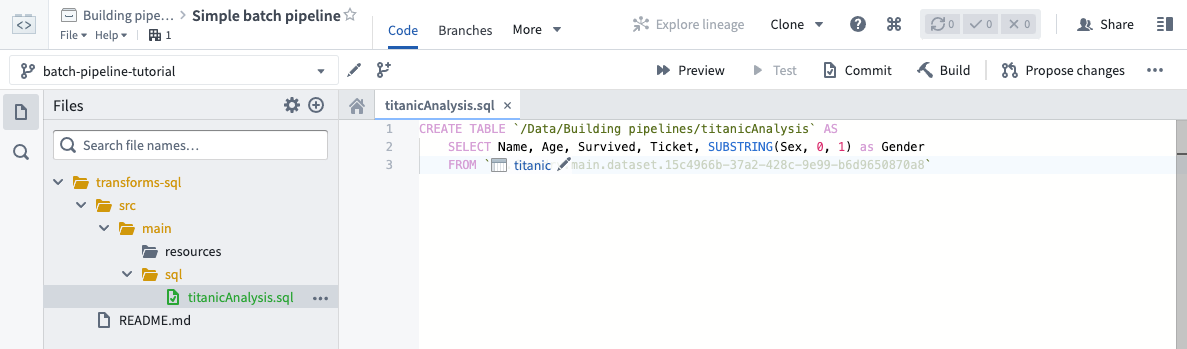
SQLで派生列を作成する場合、必ずエイリアスを定義する必要があることに注意してください。SQLデータ変換の記述について詳しくは、Spark SQL language reference を参照してください。
5. 変更のテスト
Foundryでは、データセットをブランチ化(コードと同様)することができます。これは、マルチステップのデータパイプラインの設計をテストするのに便利です。例えば、ユーザーはデータパイプラインの一部に対する変更を孤立してテストでき、ユーザーのブランチに依存しない他の人に対してダウンストリームの依存関係を壊すことなくテストできます。
データ変換コードを記述したので、ユーザーはブランチで行った変更をテストする必要があります。変更をテストすることは重要です。これにより、ユーザーのコードが期待通りに動作していることを確認できるからです。これを行った後、ユーザーは変更を master ブランチにマージできます。
変更の反復にプレビューを使用する
ユーザーがコードを記述するときには、Preview 機能を使用して開発サイクルを加速し、変更を素早く反復することができます。プレビューは、ユーザーのコードをサンプル入力で実行し、コミットしたり、チェックを実行したり、Foundryでデータセットを実体化することなく、サンプル出力を提供します。サンプル出力はビルドの結果を代表するものではないかもしれませんが、ユーザーのコードが動作し、期待通りの結果を出すことを確認する方法を提供できます。
使用するには、ヘッダーから Preview をクリックするか、または Code Editor の下部バーにある Preview ヘルパーを開きます。ファイルベースのデータセットやスキーマを持つものをプレビューすることができます。
スキーマを持つデータセットでは、変更のプレビュー時に使用する入力をカスタマイズすることができます。これは、編集したい入力の settings icon をクリックすることで可能です。オプションは以下の通りです:
- Original input: 元の入力のサンプルを使用します。
- Previous preview: 同じリポジトリで生成されたデータセットの場合、プレビューした変更をチェーン化して、データセットのプレビューをプレビューの入力として使用することができます。
- Apply custom filters: サポートされている列にフィルターを適用して、特定の入力のサブセットで変更をテストします。例えば、「特定のウィンドウ内のタイムスタンプを持つすべての行」や「特定の文字列値を持つすべての行」などです。
- Select a different dataset: ユーザーのコードが必要とするすべての列を持つ別のデータセットを選択し、特定のケースをテストしたり、任意の他のカスタムサンプルを入力として提供します。
ファイルを含むデータセットで初めてプレビューを実行すると、サンプル内で使用されるファイルを設定する必要があります。サンプルファイルが選択されると、関連する入力を選択することで再設定できます。設定を保存した後、プレビューは選択したファイルのサンプル上でコードを実行します。
再度プレビューを実行すると、入力ファイルの再設定は必要ありません。プレビューが実行されたら、ユーザーは出力サンプルを行またはファイルとして表示できます。必要な権限があれば、出力ファイルをダウンロードすることも選択できます。
変更のコミット
新しいコードを記述した後、変更をコミットできます。コードリポジトリでは、ユーザーが行った作業をラベル付けするために変更をコミットします。コミットを行う前でも、ユーザーの作業はデフォルトで自動保存されます。コミットは、ユーザーが停止点に達したときに変更のセットを具体的にラベル付けします。
Commit ボタンをクリックすると、変更がコミットされ、コードに対して自動チェックが実行されます。Build ボタンをクリックすると、変更もコミットされます。具体的には、Build をクリックすると、自動コードチェックが実行され、出力データセットのビルドが開始されます。データセットをビルドせずにすぐに変更をテストし、コードがコードチェックを通過することを確認したい場合は、Commit をクリックします。それ以外の場合は、build your dataset へ進むことができます。
行った変更をコミットするには、右上の角にある  ボタンをクリックして、行った変更の概要を入力します。変更をコミットすると、自動的にコード上でチェックが実行されます。右上のアイコンはこれらのチェックのステータスを示しており、詳細を見るためにはそれにマウスを置くことができます。
ボタンをクリックして、行った変更の概要を入力します。変更をコミットすると、自動的にコード上でチェックが実行されます。右上のアイコンはこれらのチェックのステータスを示しており、詳細を見るためにはそれにマウスを置くことができます。

ブランチ上でデータセットをビルドする
変更をテストするために、画面の上部にある  ボタンをクリックします。
ボタンをクリックします。
ビルドボタンをクリックすると、2つのことが起こります:コード上で自動チェックが実行され、出力データセットのビルドが開始されます。この間、新しい出力データセットがユーザーのブランチのコードから作成されるか、既存の出力データセットがユーザーの変更を反映して更新されます。Build ヘルパーで実行中のタスクの進行状況を確認できます。タスクが完了したら、![]() アイコンが各タスクが正常に完了したことを示します。代わりに
アイコンが各タスクが正常に完了したことを示します。代わりに ![]() アイコンが表示された場合は、Build ヘルパー内の details ボタンをクリックして何が間違っていたのかを詳しく知ることができます。これにより、ユーザーは Checks タブに移動し、エラーメッセージを探すことができ、またビルドを再トリガーすることもできます。
アイコンが表示された場合は、Build ヘルパー内の details ボタンをクリックして何が間違っていたのかを詳しく知ることができます。これにより、ユーザーは Checks タブに移動し、エラーメッセージを探すことができ、またビルドを再トリガーすることもできます。
変更のテストとデータセットのビルドについては以下の重要な情報をご覧ください:
- 右上の角にある Build ボタンをクリックすることは、Code Repositoriesインターフェースの下部にある Build ヘルパー内の Build ボタンをクリックすることと同等です。
- ビルドボタンをクリックしてチェックを実行し、出力データセットのビルドを開始する前に、ユーザーはデータ変換ロジックを含むファイルを選択する必要があります。
- ブランチ上でビルドをトリガーするたびに、それは既に実行中の既存のビルドの後にキューに入ります。
データセットをプレビューする
タスクが正常に完了し、データセットが作成されたら、Buildヘルパーでデータセットをプレビューできます。
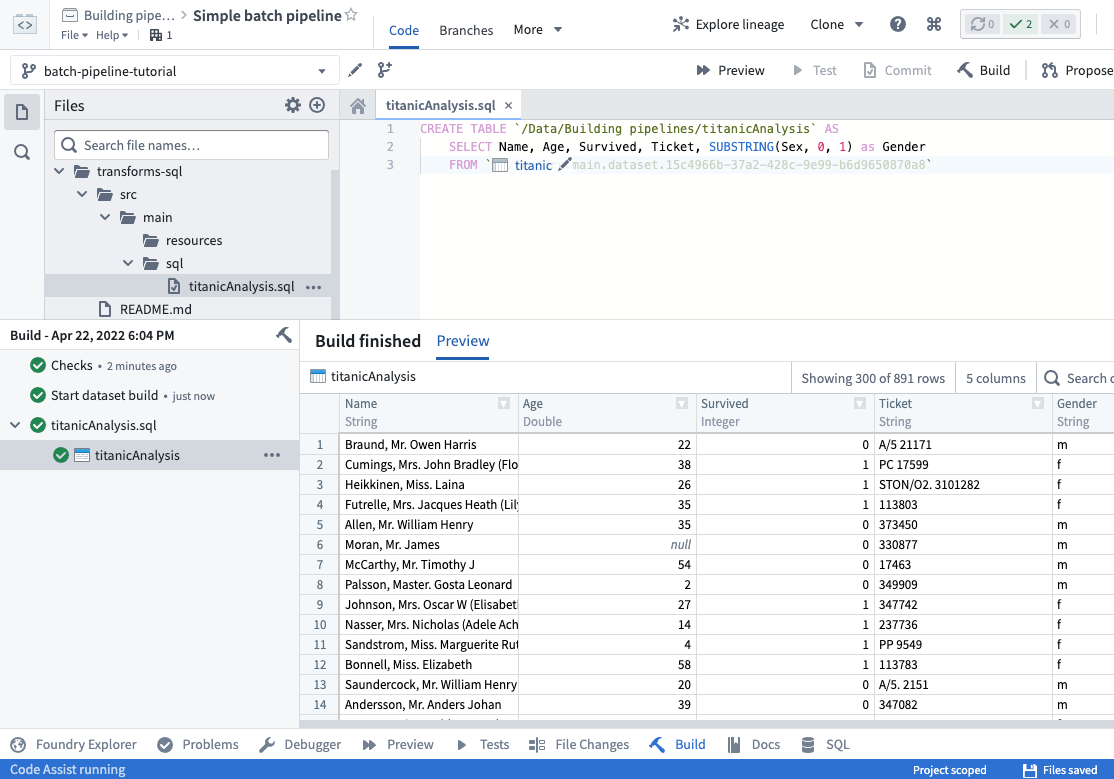
Buildヘルパーのデータセットへのリンクをクリックして、データセット全体を開きます。
これで、ユーザーのブランチでデータセットを作成しました。このガイドの残りの部分を読んで、データ変換コードをマスターブランチにマージする方法を学びましょう。
6. 変更をレビューするために提案する
これまでに、ユーザーは以下のことを行いました。
- 変更を加えるための独自のブランチを作成しました。
- データ変換コードを含む新しい SQL ファイルを作成しました。
- ブランチで変更をテストし、データセットを作成しました。
- 作成したデータセットをプレビューしました。
これで、チームメイトによるレビューのために変更を提案できます。変更をテストし、出力データセットに満足したら、チームメイトによるレビューのために変更を提案できます。
Owner権限を持つユーザーは、_プルリクエスト_を作成する際に「自動的に変更をマージする」オプションを有効にできます。このオプションは、リポジトリのブランチに少なくとも 1 つの必須チェックが設定され、通過している場合にのみ利用可能です。 「自動的に変更をマージする」オプションを有効にすると、プルリクエストが作成された後、自動的にメインコードにマージされます。ブランチの変更がメインコードにマージされると、ブランチも自動的に削除されます。
新しい Pull Request を作成するには、右上隅の  ボタンをクリックします。これにより、「新しいプルリクエスト」ページが開き、変更の説明を書いて プルリクエストの作成 ボタンをクリックできます。
ボタンをクリックします。これにより、「新しいプルリクエスト」ページが開き、変更の説明を書いて プルリクエストの作成 ボタンをクリックできます。
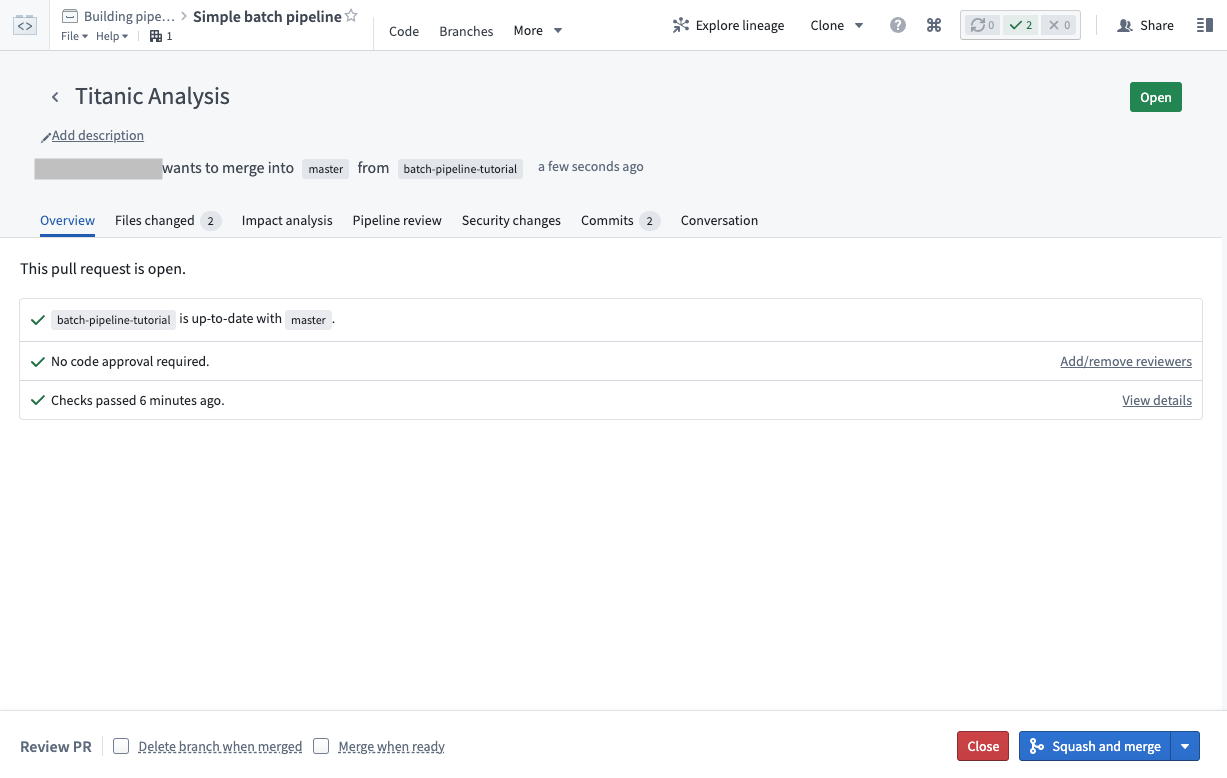
これにより、提案された変更を含む新しいプルリクエストが作成されます。プルリクエストページには、提案された変更がデータパイプラインにどのような影響を与えるかを確認するために使用できる多くのツールが用意されています。
- Files changed タブでは、チームメイトがコードを行単位でレビューできます。
- Impact analysis タブでは、ブランチで影響を受けたデータセットがどのように変更されたかを示す、データセットスキーマやヘルスチェックの変更を含めて表示されます。
- Pipeline review タブでは、データパイプラインのグラフを表示し、このプルリクエストの変更がパイプラインにどのような影響を与えるかを視覚的に強調表示します。
プルリクエストでの変更の影響を理解する方法について詳しくはこちら。
一般的には、変更がマスターブランチにマージされる前に他の人にレビューを依頼することが重要です。ユーザーは、ファイルごとに承認または拒否でき、プルリクエストがマージされる前に調整が必要なファイルを追跡できます。特定のファイルがすでに誰によって承認または拒否されたかを確認するには、対応するインジケーターアイコンの上にマウスを置くだけです。
個々のファイルのレビューボタンの使用はオプションですが、1 つのファイルを拒否すると、プルリクエストも自動的に拒否されます。同様に、プルリクエストを承認すると、すべての個々のファイルが承認されます。
7. 変更を master ブランチにマージする
変更を確定する
変更がレビューされた後、適切な権限を持つユーザー(デフォルトではオーナーとエディター)は、プルリクエストでの変更を マージ して master に組み込むことができます。
このチュートリアルの目的のために、画面の右下にある Squash and merge ボタンを選択し、確認ダイアログで再度 Squash and merge を選択してください。
リポジトリには、変更がマージされる前に満たす必要がある異なるポリシーがある場合があります。ポリシーは、ブランチの設定ページでリポジトリオーナーによって定義され、プルリクエストページでコードの著者に提示されます。
master ブランチに変更が反映されていることを確認する
提案された変更が受け入れられたら、ブランチで行った変更が master ブランチに反映されていることを確認する必要があります。これを行うには、Code タブをクリックし、master ブランチを選択し、ファイルを参照してください。ブランチで行った変更が表示されていることを確認してください。
ブランチを削除する
作成していないブランチを削除しないでください。同じコードリポジトリで作業している他の人にとって、これは作業が失われることにつながる可能性があります。
このチュートリアルの最初に作成したブランチを削除して、ごちゃつきを減らすことができます。変更が master ブランチにマージされたので、ブランチを維持する必要はありません。Branches タブに移動し、「Personal branches」の下を見てください。作成したブランチを削除するには、![]() アイコンをクリックします。
アイコンをクリックします。
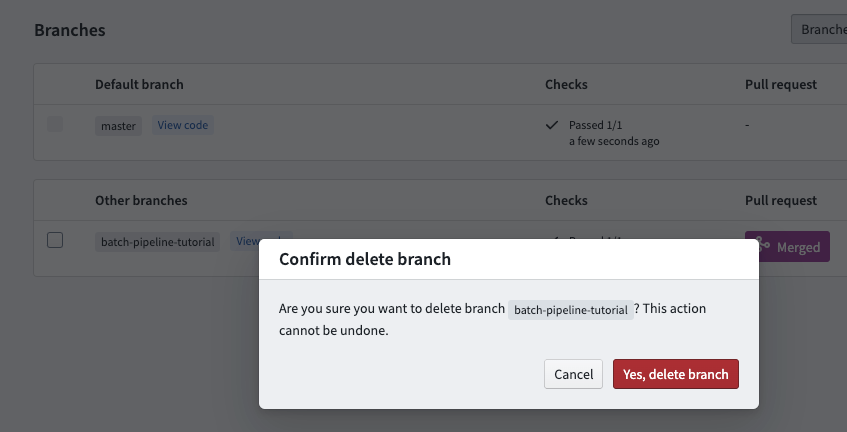
プルリクエストページには、「マージ後にブランチを削除する」オプションがあり、ブランチのクリーンアップを迅速に行うことができます。このオプションは、保護されたブランチには利用できません。
8. master ブランチでデータセットをビルドする
最後のステップは、master ブランチで新しいデータセットをビルドすることです。 ブランチでデータセットをビルドすると同様に、SQL コードファイルが選択された状態で画面上部の  ボタンをクリックします。
ボタンをクリックします。
タスクが正常に完了し、データセットが作成されたら、Buildヘルパーのデータセットへのリンクをクリックして、データセット全体を開くことができます。
おめでとうございます!Code Repositories を使用して、新しいデータ変換を作成し、変更を公開することに成功しました。続けて学ぶためのいくつかの次のステップがあります。
- インクリメンタルパイプラインの作成方法を学ぶ。
- Python Transforms を使用して、より複雑なパイプラインを作成する方法を学ぶ。
- データセット、ブランチング、ビルドなどのコアコンセプトの詳細を調べる。
9. 変更を元に戻す
マスターブランチにすでにマージしたコードの変更に問題があることに気付いた場合、それらの変更を元に戻す簡単な方法があります。マスターブランチのコミット履歴で特定のコミットを元に戻すことができます。リポジトリの Branches タブで、master をクリックして、すべてのコミットの時系列リストを表示します。
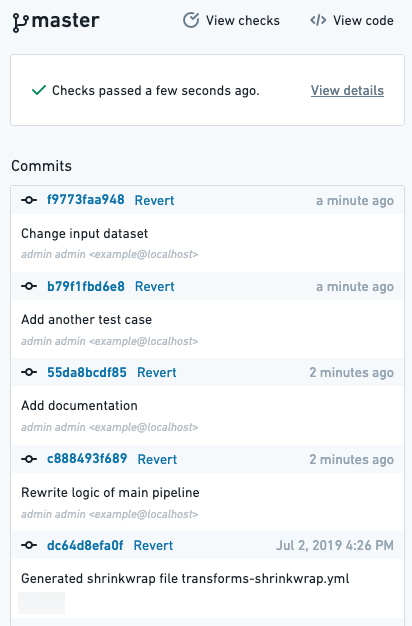
コミットハッシュをクリックすると、特定のコミットのコード変更を表示できます。元に戻したいコミットを見つけたら、Revert をクリックしてください。これにより、マスターブランチにプルリクエストが開き、レビューしてマージできます。