注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ブランチングとリリースプロセス
このドキュメントの目的は、コードリポジトリ内のプロジェクトで管理されるデータパイプラインのブランチ管理とリリースプロセスにおける推奨されるベストプラクティスを概説することです。
高いレベルでの目標は、新しいデータ機能やデータ品質の修正に対する迅速な反復と、安定したプロセス準拠の変更管理プロセスとのバランスをとるプロセスを設計することです。
リリースの範囲
リリース管理プロセスの詳細に入る前に、「私たちがリリースする製品とは何か?」を正確に定義する必要があります。ここでは、製品を概念的な単位としてリリースされるアセットのセットと定義します。
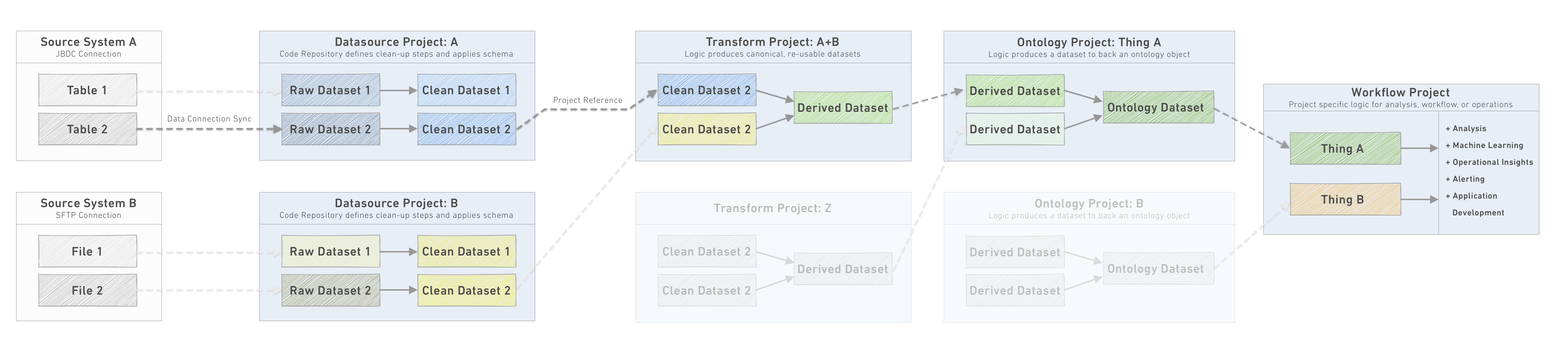
推奨されるプロジェクト構造 を Foundry でパイプラインを構築する方法の参考として、パイプラインはデータソース、変換、オントロジー、ワークフローといった複数のプロジェクトタイプで定義されていることがわかります。ただし、ほとんどの場合、各プロジェクトをそれぞれ製品として管理するのではなく、各プロジェクトは次の製品タイプの1つとしてリソースのサブセットを定義します。
- オントロジー製品:この製品は、データソース、パイプライン、オントロジープロジェクトから作成された出力データセットの集合です。
- ユースケース製品:すべてのユースケースプロジェクトは、それ自体で成り立つ特定のユースケースを表しています。各ユースケースは製品として定義されます。
ここで製品に与える定義は、複数のリポジトリで管理されるコードや Foundry の他のリソースをカバーしています。
製品ブランチ管理
以下のセクションでは、各製品のリリースを管理するために展開したいブランチ戦略について説明します。コードリポジトリとデータセット間でのブランチングの一般的な方法とブランチの動作について詳しく学ぶ。
製品内のすべてのリポジトリで同じブランチ名を使用することを強くお勧めします。これにより、下流のブランチが正しい上流のブランチから読み込まれることが保証されます。
私たちがお勧めする一般的なブランチ戦略は、GitFlow という一般的なプラクティスに基づいていますが、いくつかの変更が加えられています。主な変更点は、リリース ブランチをスキップすることをお勧めすることです。Foundryで作成物がデプロイされる方法のため、テスト後に dev から master へ直接変更をマージすることができます。
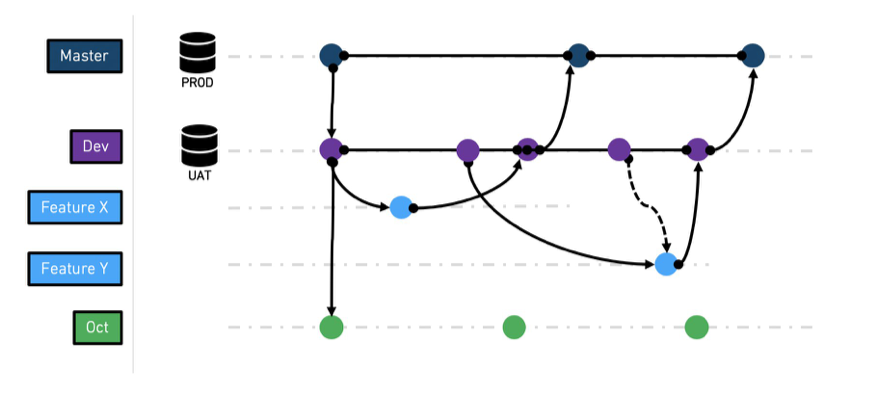
一般的なブランチ
master – これは本番ブランチです。そのため、保護されたブランチであり、リリースマネージャーロールのみがこのブランチへのPRを承認できます。master ブランチは本番データで供給されることが想定されています。
dev - dev(開発)ブランチは、master ブランチから派生したステージングブランチです。これは、テストデータを使用して完全な機能をテストしたい場合に主に関連しています。dev ブランチは master から供給されることがあります(これは、フォールバックブランチを介して自動的に行われます)または、UATデータソースから供給されることがあります。
feature-[X] – 機能ブランチは、特定の機能が開発およびテストされる場所です。このブランチは、dev ブランチから派生します。これは短命のブランチであり、ブランチがマスターにマージされると削除できます。ブランチが dev から派生しているため、dev ブランチが持っているデータと同じデータが供給されます。フォールバックブランチが再構成されない限り、また入力データセットが機能ブランチに存在しない限り、これは真実であることに注意してください。
その他の特別なブランチ
major-release-[X] - ソースシステムのスキーマの変更(特定のケイデンスで発生する)による必要な変更をすべて統合する特別なブランチ。
hot-fix-[X] - 本番環境で発見された問題を修正するために使用される特別なブランチで、コードベースが新しいバージョンに移行しています。dev と master が同期されていると仮定しています(現在アクティブにテストされている機能がない限り)、このようなブランチが必要になることはほとんどありません。
ブランチ管理ワークフロー
上記で説明したように、一部のブランチは恒久的であり、他のブランチは短期間存在します。以下のセクションでは、ブランチ間の推奨されるワークフローについて説明します。
-
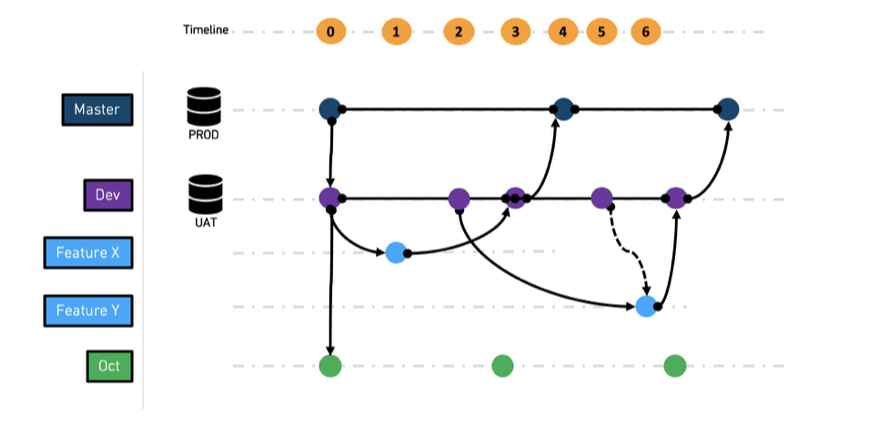
t0 で、
masterとdevブランチが作成されます。 -
t1 で、
feature xブランチがdevから作成されます。 -
t2 で、
feature yブランチがdevから作成されます。 -
t3 で、
feature xがdevにマージされます。 -
t4 で、
devがmasterにマージされ、feature xブランチが削除されます。 -
t5 で、
devがfeature yにマージされ、devの最新の状態が取得されます。 -
t6 で、
feature yがdevにマージされ、その後devからmasterにマージされます。
dev と master に開発されてリリースされる機能に加えて、major-release-[X] などのメジャーリリースの長寿命のブランチが開発されています。
dev を major-release-[X] にマージし続けることをお勧めします。これにより、最新の機能が同期されます。データソースと変換プロジェクトの変換を通じてバックエンドのスキーマ変更を隠すことで、オントロジーのスキーマをできるだけ安定させることをお勧めします。
リポジトリのアップグレード
リポジトリアップグレード は、コードリポジトリの構成ファイルを更新するように定期的に促すものです。これらの更新は、言語バンドルの依存関係の修正やバージョンアップを適用し、これらの推奨アップグレードを適用するのがベストプラクティスです。

プロンプトに表示される "Upgrade" ボタンをクリックしなかった場合でも、右上の "..." オプションメニューの中にある任意のブランチに対してボタンが利用可能です。
アップグレードプロセスは、機能の開発サイクルと同じように扱うべきです。つまり:
-
masterはdevを介してアップグレードする必要があります。 -
devをアップグレードするように促された場合、自動化された機能ブランチが作成されます。CIチェックが完了したら、このブランチでビルドを実行することで構成の変更をテストできます。アップグレード後も変換が実行されることを確認したら、devに構成の変更をマージします。devがアップグレードされたら、PRを使用してこれらの変更をマスターにプッシュします。 -
すべてのオープンな機能ブランチをアップグレードするには、これらの構成アップグレードを含めるために、
devを各ブランチにマージします。
メンテナンスウィンドウ
アイデアから本番までの迅速な反復ループは、開発プラクティスでは一般的であり、次の反復ループを決定するためにエンドユーザーのフィードバックに依存するプロジェクトの成功にとって重要です。このようなプロセスをサポートするために、事前に定義されたメンテナンスウィンドウを設定することをお勧めします。
例えば、すべての機能PRがマージされたら、結果を確認できるようにdevブランチで全データセットがビルドされます。これらの日には、確認中に発見された問題に対する修正のみがdevにマージされ、devが最終的に木曜日と月曜日にmasterにマージされるまで、"リリース日" となります。
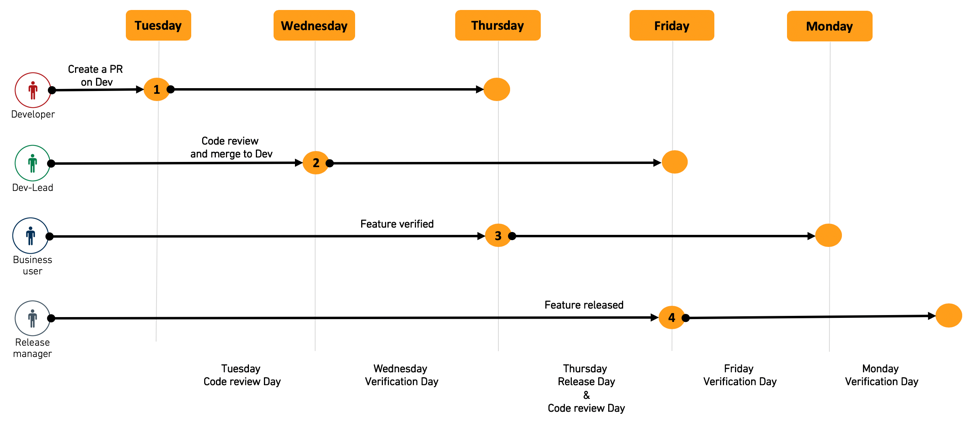
このようなケイデンスで関係者全員と合意することをお勧めします。これにより、彼らはこれらの日に新しい機能を進めるために十分な時間を費やすことができます。
機能のテストとエンドユーザーの検証
機能開発が完了したら、機能の結果の正確さと依存するリソースへの影響をテストおよび検証することが重要です。コードリポジトリでは、テストすべき機能の結果として出力データセットを考慮します。
上で定義したブランチ構造に基づいて、出力データセットをビルドすると、同じ機能の入力データセットのブランチからデータを使用するか、フォールバックロジックを通じてソースブランチ、簡略化されたバージョンではマスター、他のバージョンでは dev から読み取ります。
開発者レベルのテストは、データセットの ヘルスチェック、依存するテストデータセット、または Contour などのツールを使用して手動で行うことができます。
プレビューや SQL ヘルパーを介してこのテストを行うことは、強くお勧めしません。プレビューヘルパーは、コードを実行する際にデータの一部を使用し、特に1つ以上の結合操作が含まれるコードでは、すべてのケースが明らかにならない場合があります。SQL ヘルパーは、コードの正確さをテストしますが、ビルドの出力とは異なる場合があるため、結果が異なる場合があります。
機能開発が完了したら、新しい機能コードを dev ブランチにマージする前にレビューし、エンドユーザーによる正確さと完全性の検証が必要です。
Pull Request のレビューと Foundry Issues の組み合わせを使用することをお勧めします。以下の図に説明されています。
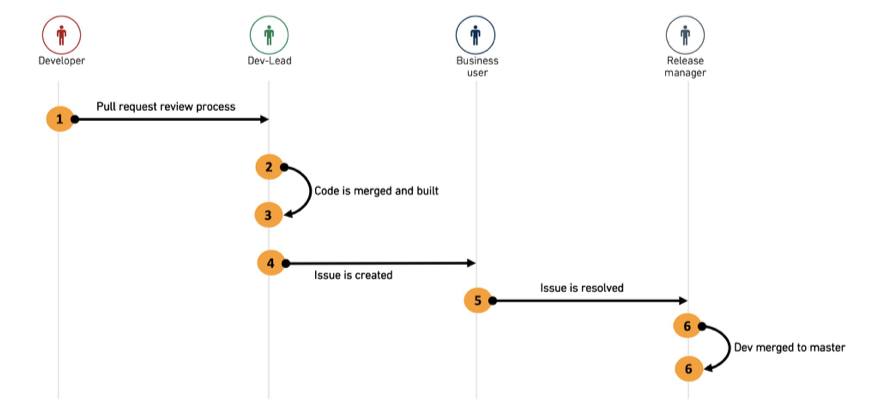
-
開発者は、自分の機能ブランチから
devブランチへのプルリクエストを作成し、実装コメントを追加します。 -
devリードは、PRをレビューし、開発者と必要な変更について協力し、最終的にPRを
devにマージします。
プルリクエストのレビュー中に、影響を受けるデータセットのスキーマの変更を確認してください。スキーマはデータAPIとして扱われるため、列名や列タイプの変更は、コンシューマにとって「ブレーキング」変更と見なされます。古い列を削除または変更するのではなく、新しい列を作成して、古い列の非推奨とデータコンシューマへの新しい列への更新の指示を発表することで、ブレーキを可能な限り制限します。次のメジャーリリースで、前のメジャーリリースで非推奨とされた列を削除することができます。
プルリクエストの影響を受けるデータセットタブのスキーマ差分ビューを使用して、スキーマの変更を確認してください。
- devリードは、
devブランチでビルドを実行して、機能の出力データセットを作成します。 - 開発者は、出力データセットの Foundry Issue を作成し、テストおよび検証リクエストを文書化し、関連するエンドユーザーに課題を割り当てます。
- エンドユーザーは、問題を受け取り、関連するデータセットとテスト対象のブランチの完全なコンテキストとビューがあります。開発者と必要な変更について協力し、問題が解決され、マージする準備ができたとマークされるまで続けます。その後、問題はリリースマネージャーに割り当てられます。
- リリースマネージャーは、問題をクローズし、
devをmasterにマージします。 - リリースマネージャーは、機能ブランチを削除します。
上記のワークフローは、関係者間で比較的迅速なコラボレーションサイクルを可能にし、コンテキストを失わずに行うことができます。閉じた問題はプラットフォームに保持され、変更管理プロセスの監査証跡として機能します。
Foundry Issues 機能レビューワークフロー
以下は、チームが Foundry Issues を使用して他の関係者からのレビューリクエストを追跡し、新しい機能に関する会話を行い、コードを master にマージするプロセスを制御および文書化する方法の例です。すべての関心を持つ当事者が情報を提供し、最新の情報を提供できるようにします。これを方向性として、必要に応じて既存の運用および技術プロセスに適応させてください。
ワークフローの例
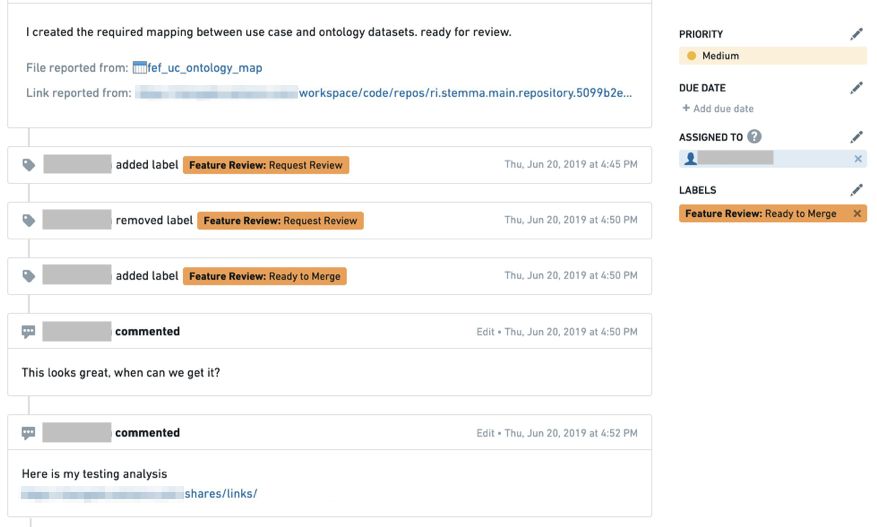
開発者が初めて機能レビューリクエスト問題を作成すると、問題は Feature Review: Request Review のステータスで割り当てられます。問題は、機能が特定の場合にはデータセットまたは特定の列に添付することができます。
エンドユーザーとのコラボレーションは、コメントセクションを使用して行い、Request Change または Ready to Merge のステータスを切り替えて、課題の割り当てを変更します。
問題は、機能のレビューワークフローを保存するのに適した場所です。エンドユーザーは、検証プロセスを文書化(監査目的)し、他のアセットへのリンクを添付することもできます。
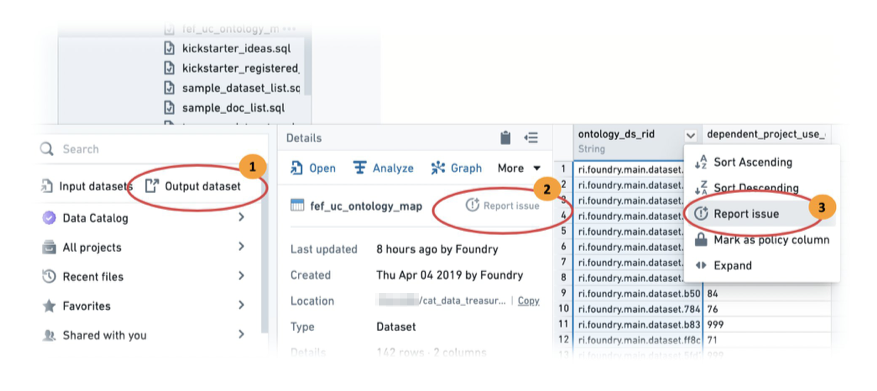
以下の図は、ビルド出力データセットで問題が作成される方法を示しています。
-
Foundry Explorerで、出力データセットを選択します。
-
問題を報告 をクリックして、データセット全体に問題を報告します。
-
機能が特定の列に関連している場合、列レベルの問題報告を使用して、行った変更のコンテキストをレビュワーに提供できます。
-
フォームによってプロンプトされるように、問題フィールドを完了します。
-
問題が作成されたら、ラベルを
Feature Review: Request Reviewに変更してください。(これらのラベルが利用できない場合は、Palantir担当者に連絡してサポートを受けてください。)
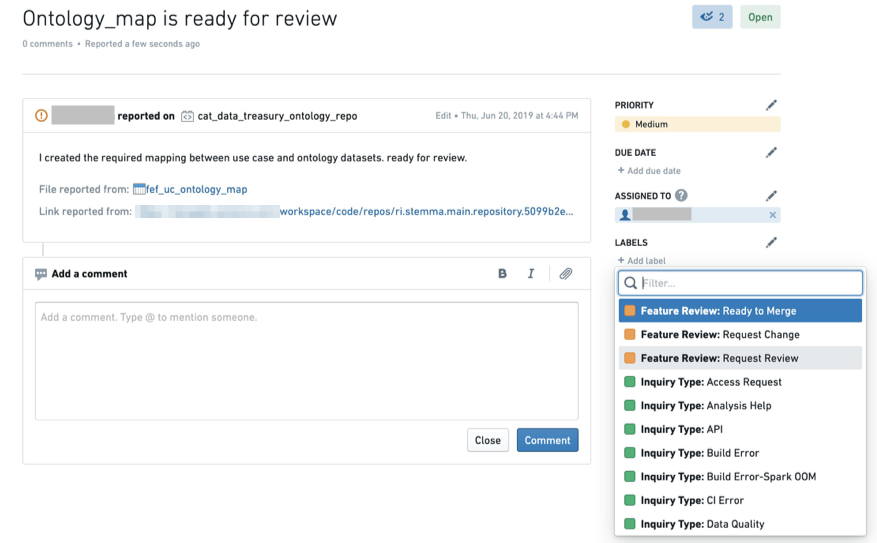
レビュープロセスが進むにつれて、ステータス変更や検証証拠を含むコラボレーションスレッドが問題に保存されます。