注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
レガシーREST APIプラグイン(magritte-rest-v2)
ここで説明されているレガシーREST APIオプションは、カスタムソースタイプmagritte-rest-v2を使用しており、歴史的なリファレンスのみを目的としています。この機能は現在積極的に開発されていないため、オンプレミスシステムに関するまれな状況を除き、使用すべきではありません。
- インターネットにアクセス可能なソースへの同期とエクスポートには、external transformsを使用してください。
- インターネットにアクセス可能なエンドポイントとオンプレミスのエンドポイントを含むWebhookには、REST API sourceを使用してください。
- オンプレミスシステムへの同期とエクスポートに利用可能なsource connectorがない場合、レガシーREST APIプラグインを引き続き使用することができます。
カスタムソースタイプのmagritte-rest-v2は、API呼び出しのシーケンスから外部システムと対話することを可能にし、主にエージェントランタイムを使用してオンプレミスのREST APIに接続するために使用するべきです。
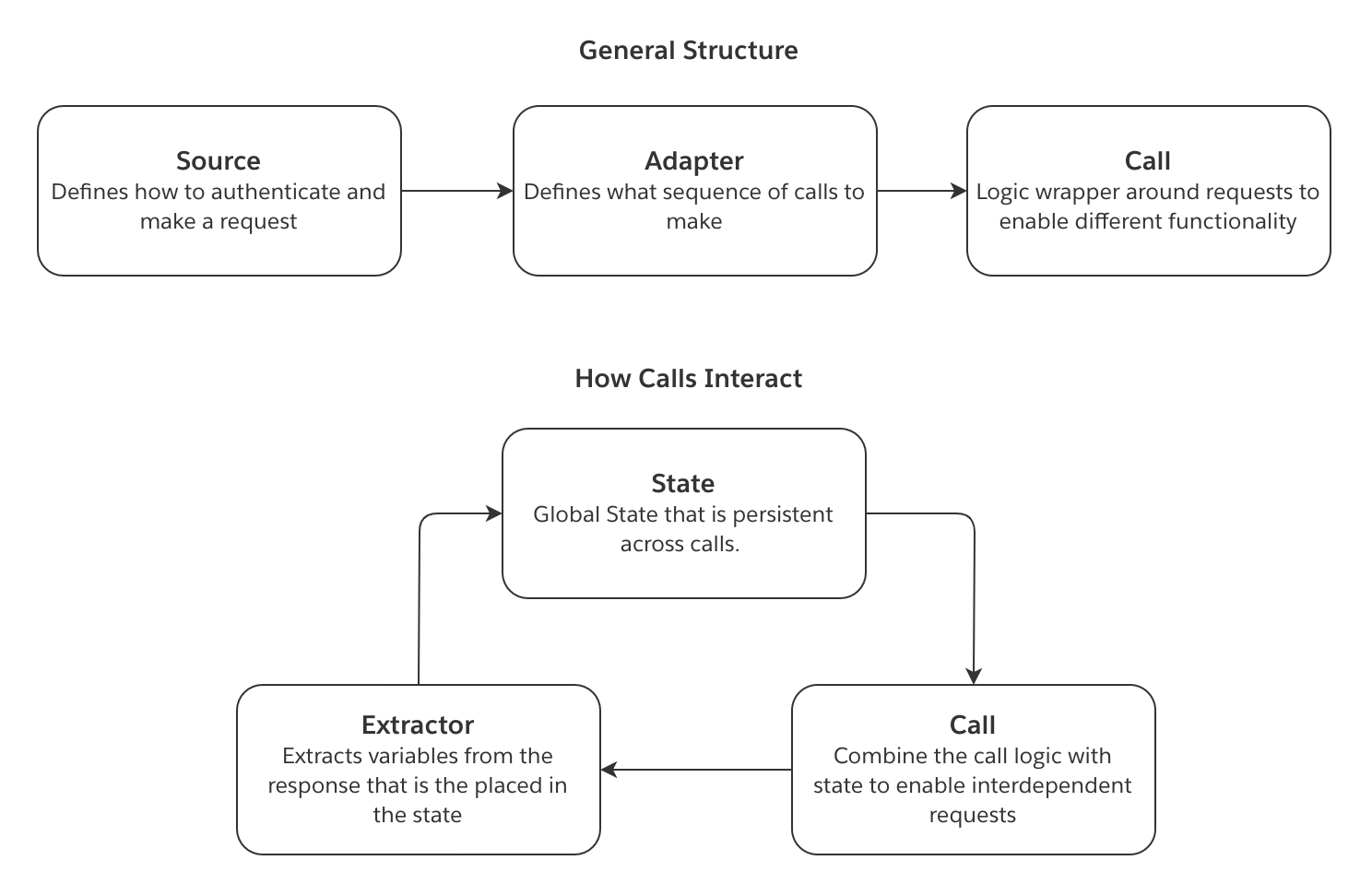
アーキテクチャ
以下の概念は、magritte-rest-v2ソースを使用する際の情報フローを説明しています。
- ソースは接続がどのように確立されるかを定義します。これには、リクエストがどのように認証するかが含まれます。
- 同期は呼び出しのリストで構成されます。各呼び出しはどのようなリクエストを行うべきかを定義し、このリクエストに必要なロジックを実装します。呼び出しは単一のGETリクエストのように単純なものであるか、ページネーションのためのリクエストのループのように複雑なものであるかもしれません。
- エクストラクターは認証呼び出しと同期呼び出しの両方に対する応答を解析する方法を定義します。同期呼び出しの場合、応答のフィールドをstateに保存できます。
- 結果として得られるstateは次の呼び出しに渡されます。この
stateの変数は、続く呼び出しに挿入することができます。これにより、相互に依存するリクエストが可能になります。
この図は上記の概念がどのように相互作用するかを示しています:
カスタムmagritte-rest-v2ソースの作成
magritte-rest-v2ソースを作成するには、Data ConnectionアプリケーションのSourcesタブからNew sourceを選択します。次に、Add Custom Sourceのオプションを選択します。magritte-rest-v2プラグインは主にYAMLエディターを通じて設定されます。
以下の例は、異なる認証タイプの設定に必要なYAMLコードスニペットを提供しています:
- Headers
- Username and password
- Body
- Form
- URL parameters
- Call
- Call to another domain
- Client certificate
- NTLM
このドキュメンテーションでは、以下のトピックについてもさらにガイダンスを提供しています:
認証
ヘッダー
Copied!1 2 3 4 5 6 7type: magritte-rest-v2 sourceMap: my_api: # "my_api"という名前のAPIの設定 type: magritte-rest # APIのタイプは"magritte-rest" headers: # ヘッダー情報 Authorization: 'Bearer {{token}}' # 認証トークンを含むヘッダー。"Bearer"の後には認証トークンが入る url: "https://some-api.com/" # APIのURL
ユーザー名とパスワード
これは Basic 認証とも呼ばれます。
Copied!1 2 3 4 5 6type: magritte-rest-v2 # Magritte REST V2タイプを定義します sourceMap: # ソースマップを定義します my_api: # my_apiという名前のAPIを定義します type: magritte-rest # APIのタイプをmagritte-restとして設定します usernamePassword: '{{username}}:{{password}}' # ユーザー名とパスワードを設定します url: "https://some-api.com/" # APIのURLを設定します
本文
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source # ソースのタイプを定義します。ここでは、REST APIの認証呼び出しを行うソースとしています url: "https://some-api.com/" # APIのURLを定義します requestMimeType: application/json # リクエストのMIMEタイプを定義します。ここでは、JSONフォーマットを指定しています body: '{"username": "{{username}}", "password": "{{password}}"}' # リクエストの本文を定義します。ここでは、ユーザー名とパスワードをJSON形式で送信します authCalls: [] # 認証呼び出しを定義します。ここでは、空の配列を指定していますので、追加の認証呼び出しは行われません
URL パラメーター
Copied!1 2 3 4 5 6 7 8 9type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source # magritte-rest-auth-call-sourceのタイプ url: "https://some-api.com/" # APIのURL parameters: # APIのパラメーター username: "{{username}}" # ユーザー名 password: "{{password}}" # パスワード authCalls: [] # 認証用のAPI呼び出し
コール
以下の設定は、返されたトークンを同期で使用するために、URLエンコードされたフォームボディを /auth エンドポイントに送信するために使用できます。エンドポイントがフォームタイプを持っている場合のみ formBody を使用してください。それ以外の場合は body を使用してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25type: magritte-rest-v2 sourceMap: my_api: # magritte-rest-auth-call-source のタイプでAPIのソースを定義しています type: magritte-rest-auth-call-source # APIのURLを定義しています url: "https://some-api.com/" headers: # トークンによる認証を設定しています Authorization: 'Bearer {%token%}' authCalls: - type: magritte-rest-call # 認証のパスを定義しています path: /auth # HTTPのメソッドをPOSTに設定しています method: POST formBody: # ユーザー名とパスワードを設定しています username: '{{username}}' password: '{{password}}' extractor: - type: magritte-rest-json-extractor assign: # トークンを抽出しています token: /token
返されたトークンが、同期が完了する前に定期的に期限切れになる場合は、authCalls の下で呼び出しをどのくらいの頻度で再試行するかを指定するために authExpiration パラメーターを使用します。authExpiration の値は、/auth エンドポイントが返すトークンの有効期間を超えないように設定します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source # APIのURLを設定します url: "https://some-api.com/" # 認証トークンの有効期限を30分に設定します authExpiration: 30m headers: # 認証ヘッダーにBearerトークンを設定します Authorization: 'Bearer {%token%}' authCalls: - type: magritte-rest-call # 認証パスを設定します path: /auth # リクエストメソッドをPOSTに設定します method: POST formBody: # ユーザーネームを設定します username: '{{username}}' # パスワードを設定します password: '{{password}}' extractor: - type: magritte-rest-json-extractor assign: # トークンを抽出し、変数tokenに割り当てます token: /token
APIがサブスクリプションキーのようなセキュリティヘッダーを使用して正常にログインする場合、authCallsの下に追加のヘッダーセクションを追加する必要があります。この2つ目のヘッダーセクションは、認証呼び出し専用に使用され、最初のヘッダーセクションとは完全に別れています。すべての他のAPI呼び出し(認証呼び出しを除く)は最初のヘッダーセクションを使用します。これらのヘッダーセクションが適切に設定されていないと、401の認証失敗が発生する可能性があります。以下に例を示します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source # APIのURLを指定します url: "https://some-api.com/" headers: X-service-identifier: SWN # 認証トークンを指定します Authorization: 'Bearer {%token%}' # サブスクリプションキーを指定します Ocp-Apim-Subscription-Key: '{{subscriptionKey}}' authCalls: - type: magritte-rest-call # 認証パスを指定します path: /auth # HTTPメソッドを指定します method: POST headers: X-service-identifier: SWN # サブスクリプションキーを指定します Ocp-Apim-Subscription-Key: '{{subscriptionKey}}' body: # ユーザ名を指定します username: '{{username}}' # パスワードを指定します password: '{{password}}' extractor: - type: magritte-rest-json-extractor assign: # トークン情報を取得します token: /token
別のドメインへの呼び出し
これにより、一つのドメインで認証を行い、そのトークンを別のドメインで使用することが可能になります:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22type: magritte-rest-v2 sourceMap: auth_api: # 認証API type: magritte-rest url: "https://auth.api.com" # APIのURL data_api: # データAPI type: magritte-rest-auth-call-source url: "https://data-api.com/" # APIのURL headers: # ヘッダー情報 Authorization: 'Bearer {%token%}' # トークンを使用した認証 authCalls: # 認証コール - type: magritte-rest-call source: auth_api # 認証APIのソース path: /auth # 認証パス method: POST # HTTPメソッド formBody: # フォームボディ username: '{{username}}' # ユーザー名 password: '{{password}}' # パスワード extractor: # 抽出器 - type: magritte-rest-json-extractor assign: # 割り当て token: /token # トークン
クライアント証明書
ソースは認証のためのJava KeyStore(JKS)ファイルの提供をサポートしています:
Copied!1 2 3 4 5 6 7type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: "https://some-api.com/" # APIのURL keystorePath: "/my/keystore/keystore.jks" # キーストアへのパス keystorePassword: "{{password}}" # キーストアのパスワード
NTLM
次のcurl:curl -v http://example.com/do.asmx --ntlm -u DOMAIN\\username:passwordは以下のように翻訳できます:
Copied!1 2 3 4 5 6type: magritte-rest-ntlm-source # ソースのタイプを指定します。ここではmagritte-rest-ntlm-sourceを使用します url: http://example.com # データソースのURLを指定します user: "{{username}}" # ユーザー名を指定します password: "{{password}}" # パスワードを指定します domain: DOMAIN (optional) # ドメイン名を指定します(任意) workstation: (optional) the name of your machine as given by $(hostname) # ワークステーション名を指定します(任意)。これはあなたのマシンの名前で、$(hostname)によって与えられます
プロキシ
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: http://example.com proxy: 'http://my-proxy:8888/' # IPアドレスも渡すことができます
このコメントは、proxyフィールドにIPアドレスも渡せるということを説明しています。
設定でプロキシの資格情報も渡すことができます:
Copied!1 2 3 4 5 6 7 8 9type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: http://example.com # ここにはAPIのURLを記載します proxy: url: 'http://my-proxy:8888/' # ここにはプロキシのURLを記載します。IPアドレスも可能です username: 'my-proxy-username' # プロキシのユーザー名を記載します password: 'my-proxy-password' # プロキシのパスワードを記載します
サーバー証明書の問題
javax.net.ssl.SSLHandshakeException のようなエラーが表示された場合、このガイドに従ってサーバーの証明書をエージェントのトラストストアに追加する必要があるかもしれません。
デバッグ目的でのみ、証明書のチェックを無効にすることもできます。これは、curlを不安全な -k フラグ(curl -k https://some-domain)を付けて実行することに対応しています。
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest # magritte-restのタイプを指定します url: https://example.com # APIのURLを指定します insecure: true # セキュリティ設定。trueの場合、安全性が低いとされます
TLS バージョン
デフォルトでは、プラグインは現代の TLS バージョン (TLSv1.2 および TLSv1.3) のみで接続します。
古いバージョンを使用するには、設定で TLS バージョンを指定してください:
Copied!1 2 3 4 5 6type: magritte-rest-v2 # 型はmagritte-rest-v2を指定します sourceMap: # ソースマップを定義します my_api: # my_apiという名前のAPIを定義します type: magritte-rest # APIの型はmagritte-restを指定します url: https://example.com # APIのURLはhttps://example.comを指定します tlsVersion: 'TLSv1.1' # 使用するTLSのバージョンは1.1を指定します
サポートされているバージョン:TLSv1.3、TLSv1.2、TLSv1.1、TLSv1、SSLv3。
同期の作成
同期を作成するには、magritte-rest-v2 ソースの一番上から "同期の作成" ボタンをクリックします。基本ビューでは、データをフェッチするための1つ以上の呼び出しを作成する手順を案内します。高度なビューでは、YAML設定を直接編集することが可能です。これらのビュー間をページの右上で切り替えることができます。
同期には少なくとも1つの呼び出しが必要です。基本ビューでは、"順番に呼び出しを実行する" ヘッダーの下の "追加" ボタンをクリックして新しい呼び出しを作成することができます。次に、呼び出しは "シングルコール" を選択して一度だけ行うか、ループ、時間範囲、日付範囲、リスト、または結果のページングに基づいて複数回行うかを指定できます。
各呼び出しには、クエリ時にソースURLに追加されるパスが必要です。たとえば、ソースのURLが https://my-ap-source.com で、パスが /api/v1/get-documents を使用すると、呼び出しは https://my-ap-source.com/api/v1/get-documents をクエリします。
このセクションでは、一般的なシナリオを対象としたYAML設定のリストを示します:
このドキュメンテーションでは、以下のトピックについても追加のガイダンスを提供します:
一般的なシナリオ
日時ベースのAPI
/daily_data?date=2020-01-01 で各日付のCSVレポートを提供するAPIを想定します。この例では、これらのレポートが利用可能になるとすぐに取り込むことを希望します。これを達成するために、同期されたレポートの最後の日付を覚えておく日次同期をスケジュールすることで、今日までの同期されていない日付のレポートを自動的に取得できます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26type: rest-source-adapter2 # タイプ:rest-source-adapter2 outputFileType: csv # 出力ファイルタイプ:csv incrementalStateVars: # 増分状態変数: incremental_date_to_query: '2020-01-01' # クエリの増分日付:'2020-01-01' initialStateVars: # 初期状態変数: yesterday: # 昨日: type: magritte-rest-datetime-expression # タイプ:マグリット-rest-日付時刻式 offset: '-P1D' # オフセット:'-P1D' timezone: UTC # タイムゾーン:UTC formatString: 'yyyy-MM-dd' # フォーマット文字列:'yyyy-MM-dd' restCalls: # RESTコール: - type: magritte-increasing-date-param-call # タイプ:マグリット-増加日付パラメータコール checkConditionFirst: true # 条件を最初にチェック:真 paramToIncrease: date_to_query # 増加するパラメータ:date_to_query increaseBy: P1D # 増加量:P1D initValue: '{%incremental_date_to_query%}' # 初期値:'{%incremental_date_to_query%}' stopValue: '{%yesterday%}' # 停止値:'{%yesterday%}' format: 'yyyy-MM-dd' # フォーマット:'yyyy-MM-dd' method: GET # メソッド:GET path: '/daily_data' # パス:'/daily_data' parameters: # パラメータ: date: '{%date_to_query%}' # 日付:'{%date_to_query%}' extractor: # 抽出器: - type: magritte-rest-string-extractor # タイプ:マグリット-rest-文字列抽出器 fromStateVar: 'date_to_query' # 状態変数から:'date_to_query' var: 'incremental_date_to_query' # 変数:'incremental_date_to_query'
上記の設定と同等のPythonスニペットを比較すると役立つかもしれません。APIがインターネット上で利用可能である場合、外部Pythonトランスフォームを直接使用できることを覚えておいてください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31import requests from datetime import datetime, timedelta # 増分状態をロードします incremental_state = load_incremental_state() # 増分状態がなければ、'2020-01-01'をデフォルトの日付として設定します if incremental_state is None: incremental_state = {'incremental_date_to_query': '2020-01-01'} # 昨日の日付を取得します yesterday = datetime.utcnow() - timedelta(days=1) # クエリする日付を増分状態から取得します date_to_query = incremental_state['incremental_date_to_query'] # 文字列形式の日付を日付型に変換します date_to_query = datetime.strptime(date_to_query, '%Y-%m-%d') # 昨日の日付がクエリ日付以上である間、ループを続けます while yesterday >= date_to_query: # 日次データを取得します response = requests.get(source.url + '/daily_data', params={ 'date': date_to_query.strftime('%Y-%m-%d') }) # 取得したデータをアップロードします upload(response) # クエリする日付を1日進めます date_to_query += timedelta(days=1) # 増分日付を更新します incremental_date_to_query = date_to_query # 更新した増分状態を保存します save_incremental_state({'incremental_date_to_query': incremental_date_to_query})
ページベースのAPI
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19type: rest-source-adapter2 # タイプ: RESTソースアダプタ2 outputFileType: json # 出力ファイルタイプ: json restCalls: # REST呼び出し - type: magritte-paging-inc-param-call # タイプ: ページング増加パラメータ呼び出し paramToIncrease: page # 増加させるパラメータ: ページ initValue: 0 # 初期値: 0 increaseBy: 1 # 増加量: 1 method: GET # メソッド: GET path: '/data' # パス: '/data' parameters: # パラメータ page: '{%page%}' # ページ: '{%page%}' entries_per_page: 1000 # ページごとのエントリ: 1000 extractor: # エクストラクタ - type: magritte-rest-json-extractor # タイプ: JSONエクストラクタ assign: # 割り当て page_items: '/items' # ページ項目: '/items' condition: # 条件 type: magritte-rest-non-empty-condition # タイプ: 非空の条件 var: page_items # 変数: ページ項目
開発者である場合、上記の設定を同等の python スニペットと比較することで理解しやすくなるかもしれません:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19import requests page = 0 while True: # ソースからデータを取得 response = requests.get(source.url + '/data', params={ 'page': page, 'entries_per_page': 1000 }) # アップロード処理 upload(response) # ページ番号をインクリメント page += 1 # ページ内のアイテムを取得 page_items = response.json().get('items') # アイテムが存在しない場合、ループを抜ける if not page_items: break
オフセットベースのAPI
ここには、基本的なElasticSearchの検索APIの例を示します:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21type: rest-source-adapter2 # タイプ: RESTソースアダプター2 outputFileType: json # 出力ファイルタイプ: json restCalls: # REST呼び出し: - type: magritte-paging-inc-param-call # タイプ: マグリットページング増加パラメータ呼び出し paramToIncrease: offset # 増加させるパラメータ: offset initValue: 0 # 初期値: 0 increaseBy: 100 # 増加量: 100 method: POST # メソッド: POST path: '/_search' # パス: '/_search' body: |- # 本文: { "from": {%offset%}, # から: {%offset%} "size": 100 # サイズ: 100 } extractor: # 抽出器: - type: magritte-rest-json-extractor # タイプ: マグリットREST JSON抽出器 assign: # 割り当て: hits: '/hits' # ヒット: '/hits' condition: # 条件: type: magritte-rest-non-empty-condition # タイプ: マグリットREST非空条件 var: hits # 変数: ヒット
次のページリンクベースのAPI
次のページのトークンは、カーソル、続行、またはページネーショントークンともよく知られています。
ここにElasticSearchの検索とスクロールAPIの例があります:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28type: rest-source-adapter2 # タイプ: RESTソースアダプタ2 outputFileType: json # 出力ファイルタイプ: JSON restCalls: # RESTコール: - type: magritte-rest-call # タイプ: マグリットRESTコール method: GET # メソッド: GET path: /my-es-index/_search?scroll=1m # パス: /my-es-index/_search?scroll=1m parameters: # パラメータ: scroll: 1m # スクロール: 1m extractor: # 抽出器: - type: json # タイプ: JSON assign: # 割り当て: scroll_id: /_scroll_id # scroll_id: /_scroll_id - type: magritte-do-while-call # タイプ: マグリットdo-whileコール method: GET # メソッド: GET checkConditionFirst: true # 最初に条件をチェック: 真 path: /_search/scroll # パス: /_search/scroll parameters: # パラメータ: scroll: 1m # スクロール: 1m scroll_id: '{%scroll_id%}' # scroll_id: '{%scroll_id%}' extractor: # 抽出器: - type: json # タイプ: JSON assign: # 割り当て: scroll_id: /_scroll_id # scroll_id: /_scroll_id hits: /hits # ヒット: /hits timeBetweenCalls: 0s # コール間の時間: 0秒 condition: # 条件: type: magritte-rest-non-empty-condition # タイプ: マグリットREST非空の条件 var: hits # 変数: ヒット
以下は、AWS nextToken ページネーション API の例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31type: rest-source-adapter2 outputFileType: json # 出力ファイルのタイプをjsonに設定します restCalls: - type: magritte-rest-call # MagritteのREST呼び出しのタイプ method: POST # HTTPメソッドとしてPOSTを使用します path: /findings/list # パスは/findings/listです extractor: - type: json # 抽出タイプはjsonです assign: nextToken: /nextToken # /nextTokenからnextTokenを割り当てます allowNull: false # nullを許可しない設定です allowMissingField: true # フィールドが欠けているのを許可する設定です requestMimeType: application/json # リクエストのMIMEタイプはapplication/jsonです body: '{}' # リクエストボディは空のjsonオブジェクトです - type: magritte-do-while-call # Magritteのdo-while呼び出しタイプ method: POST # HTTPメソッドとしてPOSTを使用します checkConditionFirst: true # 最初に条件をチェックする設定です path: /findings/list # パスは/findings/listです extractor: - type: json # 抽出タイプはjsonです assign: findings: /findings # /findingsからfindingsを割り当てます nextToken: /nextToken # /nextTokenからnextTokenを割り当てます allowNull: false # nullを許可しない設定です allowMissingField: true # フィールドが欠けているのを許可する設定です condition: type: magritte-rest-available-condition # 条件タイプはMagritteのREST利用可能条件です var: nextToken # 条件変数はnextTokenです timeBetweenCalls: 0s # 呼び出し間の時間は0秒です requestMimeType: appliation/json # リクエストのMIMEタイプはapplication/jsonです body: '{"nextToken":"{%nextToken%}"}' # リクエストボディはnextTokenを含むjsonオブジェクトです
レポートのトリガーとダウンロード
以下の sync は、3つの相互依存ステップを必要とするAPIのためのものです。
- ボディがエンドポイントに投稿され、IDを含むレスポンスが返されます。
- 次のエンドポイントでこのIDを使用してレポートを取得する必要があります。しかし、レポートはすぐには準備ができていないため、レスポンスにはレポートが完了したかどうかを定義する
statusフィールドが含まれます。 - レポートが完了したら、第三のエンドポイントからレポートを取得できます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-rest-call path: '/findRelevantId' # 関連するIDを見つけるためのパス method: POST # HTTPメソッドはPOSTを使用 requestMimeType: application/json # リクエストのMIMEタイプはapplication/json extractor: - type: json assign: id: /id # idを抽出し割り当てる body: > body saveResponse: false # レスポンスを保存しない - type: magritte-do-while-call path: '/reportReady' # レポートの準備ができているかを確認するためのパス method: GET # HTTPメソッドはGETを使用 parameters: id: '{%id%}' # パラメータとしてidを使用 extractor: - type: magritte-rest-json-extractor assign: status: /status # ステータスを抽出し割り当てる condition: type: "magritte-rest-regex-condition" var: status matches: "(processing|queued)" # ステータスがprocessingまたはqueuedである場合にマッチ timeBetweenCalls: 8s # コール間の時間は8秒 saveResponse: false # レスポンスを保存しない - type: magritte-rest-call path: '/getReport/{%id%}' # レポートを取得するためのパス method: GET # HTTPメソッドはGETを使用 requestMimeType: application/json # リクエストのMIMEタイプはapplication/json
Extractorは、状態に保存するフィールドを定義します。これらの変数は、次に続くすべてのREST呼び出しで利用可能であることに注意してください。保存した変数を注入するには、変数名を {%%} で囲みます。2番目の do-while 呼び出しは、ステータス変数がキュー待ちまたは処理中でなくなるまでリクエストを送信するループを実装します。
一部のAPIは status エンドポイントを持っておらず、代わりに getReport エンドポイントをポーリングして、レポートが準備できるまで空のレスポンスを提供する必要があります。以下の設定は、そのようなシナリオをどのように扱うかを示しています:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: rest-source-adapter2 outputFileType: json # 出力ファイル形式をJSONに設定 restCalls: - type: magritte-do-while-call # ループしながらAPIコールを行う設定 path: '/getReport/{%id%}' # APIエンドポイントのパス method: GET # HTTPメソッドをGETに設定 extractor: - type: magritte-rest-string-extractor # レスポンスの抽出方法 var: response # 抽出結果を格納する変数 condition: type: magritte-rest-not-condition # 条件が成立しない場合の処理 condition: type: magritte-rest-non-empty-condition # レスポンスが空でない場合の条件 var: response # チェックする変数 timeBetweenCalls: 8s # APIコールの間隔を8秒に設定
または、レポートが準備完了するまで getReport エンドポイントが 204 ステータスコードを返す場合、以下のように処理できます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-do-while-call path: '/getReport/{%id%}' # RESTエンドポイントのパス method: GET # HTTPメソッド extractor: - type: magritte-rest-http-status-code-extractor assign: responseCode # HTTPステータスコードを抽出し、responseCodeに割り当てる condition: type: magritte-rest-regex-condition var: responseCode # 抽出されたresponseCodeを条件に使用 matches: 204 # ステータスコードが204であるかをチェック timeBetweenCalls: 8s # 各リクエストの間隔を8秒に設定
インクリメンタル同期
このプラグインは、インクリメンタルな同期をサポートしています。これを行うには、同期のインクリメンタル state として保存したい state から変数を選択し、incrementalStateVarsを指定します:
Copied!1 2 3type: rest-source-adapter2 incrementalStateVars: var_name: initial_value # インクリメンタルメタデータが見つからない場合に使用される初期値
Copied!1 2 3type: rest-source-adapter2 # タイプ: RESTソースアダプタ2 incrementalStateVars: # 増分状態変数: lastModifiedDate: 20190101 # 最終更新日: 20190101
保存された増分 state は、同期を実行する際の初期 state として使用されます。
より詳細な例:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23type: rest-source-adapter2 outputFileType: json incrementalStateVars: lastModifiedTime: 'Some initial start time' # 初期の開始時間 initialStateVars: # 現在の時間を取得 currentTime: type: magritte-rest-datetime-expression timezone: 'Some timezone, e.g. Europe/Paris' # タイムゾーン(例:Europe/Paris) formatString: 'Some format string https://docs.oracle.com/javase/8/docs/api/ \ java/time/format/DateTimeFormatter.html' # フォーマット文字列 restCalls: - type: magritte-rest-call path: /my/values method: GET parameters: from: '{%lastModifiedTime%}' # から until: '{%currentTime%}' # まで extractor: # 最終更新時間を現在の時間に更新 - type: magritte-rest-string-extractor var: lastModifiedTime fromStateVar: currentTime
詳細なドキュメンテーション
API ソースを複数追加した場合、それぞれの REST コールで使用するソースを source 属性で指定する必要があります。
同期
同期設定には、以下のフィールドが含まれます。
Copied!1 2 3 4 5 6 7 8 9type: rest-source-adapter2 restCalls: [calls] # Callsの詳細については下記のドキュメンテーションを参照してください initialStateVars: {variableName}: {variableValue} # 初期状態の変数名とその値 incrementalStateVars: {variableName}: {variableValue} # 増分状態の変数名とその値 outputFileType: json # oneFilePerResponseがTrueの場合、必須 cacheToDisk: defaults to True # デフォルトではディスクへキャッシュされます oneFilePerResponse: defaults to True; when set to True "outputFileType" is required # デフォルトはTrueで、Trueに設定した場合は"outputFileType"が必要になります
outputFileType で出力ファイルタイプを設定するには、oneFilePerResponse が true でなければなりません。それ以外の場合、レスポンスはデータセットの行として保存されます。レスポンスタイプに基づいた推奨オプションについては、以下の レスポンスの保存 を参照してください。
レスポンスの保存
バイナリレスポンスまたはレスポンスサイズの合計が 100MB を超える場合に推奨:
Copied!1 2 3cacheToDisk: true # ディスクにキャッシュする。trueならキャッシュします。 outputFileType: [任意のファイル形式, たとえば txt, json, jpg] # 出力ファイルの形式を指定します。 oneFilePerResponse: true # デフォルト、指定する必要はありません。各レスポンスごとにファイルを生成します。
数MBまでの非バイナリレスポンスと、レスポンスサイズの合計が100MB以下の場合、以下のように推奨します:
Copied!1 2cacheToDisk: false # ディスクへのキャッシュ:無効 oneFilePerResponse: false # レスポンスごとにファイルを作成:無効
レスポンスがディスクに収まらないが、全体の同期時間が短い(3 分以下)場合、次のことをお勧めします:
Copied!1 2 3cacheToDisk: false # ディスクへのキャッシュ:無効 oneFilePerResponse: true # 応答ごとに1つのファイル:有効 outputFileType: [任意のファイル形式, 例:txt、json、jpg] # 出力ファイルタイプ:任意の形式(例:txt、json、jpg)
コール
コアコールフィールド
すべてのコールは基本的な RestCall オブジェクトから継承され、以下のフィールドを含みます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28type: Rest呼び出しタイプ path: エンドポイント method: GET | POST | PUT | PATCH # 以下はすべてオプションです source: この呼び出しに使用するAPIソース。 # 複数のAPIソースがある場合は必須です。 parameters: リクエストに一緒に送るパラメーターのマップ # デフォルトは空のマップ saveResponse: レスポンスをファウンドリーに保存するかどうか # デフォルトはTrue body: 投稿する本文 formBody: # x-www-form-urlencodedのポストで使用するパラメーターのマップ。 # オプションで、x-www-form-urlencodedエンドポイントをヒットする場合にのみ、本文の代わりに使用します。 param1: value1 requestMimeType: application/json headers: リクエストヘッダー、これらはソースヘッダーに追加されますが、一致するヘッダーは置き換えられます # validResponseCodes: オプションで、APIコールが終了しないHTTPレスポンスコードのセット。 # 設定されていない場合、有効なHTTPレスポンスコードは200、201、204です。 validResponseCodes: - 200 - 201 - 204 # retries: デフォルトは0。リクエストはキャンセル、接続問題、またはタイムアウトにより失敗する可能性があります。 # この呼び出しによって行われるリクエストごとの再試行回数を設定することができます。 retries: 0 extractor: 抽出器オブジェクトのリスト、抽出器を参照 # ファイル名のテンプレート 例 'data_{%page%}', # それ以外の場合、ファイル名は'[sourceName][path][parameters]'となります filename: '<必要がない限りオーバーライドしないでください>' addTimestampToFilename: デフォルトはtrueで、タイムスタンプをファイル名に追加するかどうか
上記のフィールドに追加のフィールドを追加することができます。
REST コール
Copied!1type: magritte-rest-call # タイプ:マグリット-REST-コール
このコードは、特定のタイプ(ここでは'magritte-rest-call')のREST呼び出しを指定します。このタイプの呼び出しは、一般的にAPI呼び出しを行うときに使用されます。 単一のリクエストを実行します。コアコールと同じYAML設定を使用します。
インクリメンタルページングコール
条件が満たされている間、増加するパラメーターを持つ同じリクエストを実行します。ページングによく使用されます。パスまたは parameters: セクションに含まれている場合、増加しているパラメーターは {%paramToIncrease%} を値として持つ必要があります。
Copied!1 2 3 4 5 6 7 8 9 10type: magritte-paging-inc-param-call paramToIncrease: 増加させるパラメーターへの状態キー。 checkConditionFirst: "true"に設定した場合、whileループと同等です。"false"(デフォルト)に設定した場合、do-whileループと同等です。 initValue: 増加パラメーターの初期値。 increaseBy: 各反復でパラメーターをどれだけ増加させるか。 onEach: 各反復で実行する呼び出しのリスト。オプションで、ネストされた呼び出しを行うために使用されます。 condition: リクエストを続けるための条件オブジェクト。条件が真である限り、新しいリクエストが作成されます。この条件は最初のリクエスト後にのみ確認されるため、 do-whileループのように動作します。 maxIterationsAllowed: エラーをスローする前に実行する反復の最大数。 timeBetweenCalls: (オプション) リクエスト間の待機時間
インクリメンタル日付呼び出し
ある条件が満たされるまで日付パラメーターを増加させて同じリクエストを実行します。これは日付の反復処理に使用されます。これはLocalDate型とPeriod型を使用するため、利用可能な最も粒度の高い増分は1日です。これは日付のみのマッチングでのみ機能します。より細かく増分を行う必要がある場合は、magritte-increasing-time-param-callを参照してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16type: magritte-increasing-date-param-call # 増加させるパラメーターへの状態キー paramToIncrease: state key to param to increase. # "true"に設定されている場合、whileループと同等。"false"(デフォルト)はdo-whileループと同等です。 checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # 増加パラメータの初期値 initValue: Initial value of increasing parameter. # 各反復でパラメータをどれだけ増やすか、java.time.Periodとして解析可能 increaseBy: How much to increase the parameter by in each iteration, parseable as a java.time.Period # 使用される最後の日付、該当する場合はこの値を含む stopValue: The last date which will be used, including this value if applicable. # 各呼び出しのDateTimeパラメータのフォーマット(java.time.format.DateTimeFormatter)、initValueおよびstopValueと同じ format: The format (java.time.format.DateTimeFormatter) for the DateTime parameter in each call, the same as initValue and stopValue. # (オプション)リクエスト間の待ち時間 timeBetweenCalls: (optional) time to wait between requests
インクリメンタルタイムコール
何らかの条件が満たされるまで、増加する DateTime パラメーターで同じリクエストを実行します。DateTime を通じて反復処理するために使用されます。 注:これは OffsetDateTime と Duration タイプを使用し、magritte-incrementing-date-param-call とは対照的です。 OffsetDateTime は夏時間の変更を考慮に入れません。このことが API が DateTime を処理する方法と予想外のギャップを生じさせないか確認してください。
Copied!1 2 3 4 5 6 7 8 9type: magritte-increasing-time-param-call paramToIncrease: 増加させるパラメータへの状態キー。 checkConditionFirst: "true"に設定すると、whileループと同等になります。"false"(デフォルト)に設定すると do-whileループと同等になります。 initValue: 増加パラメータの初期値。 increaseBy: 各イテレーションでパラメータをどれだけ増やすか、java.time.Durationとして解析可能 stopValue: 使用される最後のDateTime、適用可能な場合はこの値を含む。 format: 各呼び出しのDateTimeパラメータの形式(java.time.format.DateTimeFormatter)、initValueおよびstopValueと同じ。 timeBetweenCalls: (オプション)リクエスト間の待機時間
Do while
指定された条件が満たされなくなるまでリクエストを実行します。 コア呼び出しフィールドに加えて、2つのフィールドを提供する必要があります。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: magritte-do-while-call # type: magritte-do-while-call はこのコードの種類を指定します timeBetweenCalls: time to wait between requests # timeBetweenCalls: リクエスト間で待つ時間を指定します checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # checkConditionFirst: "true"に設定するとwhileループと同等になります。"false"(デフォルト)を設定するとdo-whileループと同等になります。 condition: Condition object that keeps requests going. As long as the condition is true, a new request is created. # condition: リクエストを続ける条件オブジェクト。条件が真である限り、新しいリクエストが作成されます。 maxIterationsAllowed: How many iterations to run before throwing an error. Defaults to 50. # maxIterationsAllowed: エラーをスローする前に実行するイテレーションの数を指定します。デフォルト値は50です。
オプションとして、最初の呼び出しをブートストラップするための初期 state を提供できます。
例:
Copied!1 2initialState: nextPage: "" # 初期状態では、次のページは空("")です
初期の state と増分の state が競合した場合、増分の state が初期のステートを上書きします。
Iterable stateの呼び出し
イテラブルな state 要素の各要素に対してリクエストを実行します。
Copied!1 2 3 4 5 6 7 8 9type: magritte-iterable-state-call timeBetweenCalls: 5s # 各呼び出し間の時間を制御します iterableField: イテレートする状態キー。この変数はイテレータブルでなければなりません。 iteratorExtractor: イテラブルな要素のそれぞれに対して実行する抽出器のリスト。 onEach: 各イテレーションで実行する呼び出しのリスト。オプションで、ネストされた呼び出しを行うために使用されます。 maxIterationsAllowed: エラーをスローする前に実行するイテレーションの最大数。デフォルトは50です。 parallelism: 同期に使用するスレッドの整数数。仮定/制限には、リクエストに副作用がない、 呼び出しの順序やそのレスポンスが状態を更新する順序に保証がない、呼び出し間に時間がない、 などがあります。このフィールドはオプションで、デフォルトは1です。
エクストラクター
エクストラクターは、レスポンスまたはstate 変数から変数を保存する方法を定義します。URL、URLパラメーター、またはリクエストボディ内のstateから変数を参照することができ、{%var_name_1%}の形式で表示されます。
エクストラクターのデフォルトの動作は、レスポンスから値を抽出することです。オプションとして、fromStateVar設定を追加して、Stateから抽出することもできます。これにより、異なるエクストラクターを一つずつ実行することが可能になります。例を以下に示します:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: rest-source-adapter2 # レストソースアダプタ2の型 outputFileType: csv # 出力ファイルの形式はCSV restCalls: # REST呼び出し - type: magritte-rest-call # Magritte REST呼び出しの型 path: /my/path/index.html # パス source: mysource # ソース method: GET # メソッドはGET extractor: # 抽出器 - type: magritte-rest-json-extractor # Magritte REST JSON抽出器の型 assign: # 割り当て full_name: /my/field/full_name # full_nameフィールド - type: magritte-rest-regexp-extractor # Magritte REST正規表現抽出器の型 fromStateVar: full_name # full_nameからの状態変数 assign: # 割り当て names: '\w+' # namesというフィールドには単語を割り当てる
すべてのエクストラクターには、利用可能な条件チェックが組み込まれています:
Copied!1condition: 入力状態が指定された条件を満たしているかどうかを確認します。そうでない場合、エクストラクターは実行されません。
JSONエクストラクター
すべてのJSONエクストラクターは Jackson JsonNode ↗ を使用し、同じ表記法に従います。
フィールドを参照するためのクイックガイド:
JSON {"id":1} が与えられた場合:
"/id"を使用すると1を返します"/"を使用すると{"id":1}を返します
リストが与えられた場合、たとえば [1,2,3] や [{"id":1},{"id":2}]:
""を使用するとリストを返します。
ワイルドカードを使用して、リスト内のすべてのアイテムのサブインデックスまたはフィールドを参照することができます。たとえば:
ネストしたリストを含むフィールドが与えられた場合、たとえば { "result": [[1], [2, 3, 4]] }:
"/result/*/0"を使用すると[1,2]を返します。
オブジェクトのリストを含むフィールドが与えられた場合、たとえば { "result": [{ "foo": 1}, {"foo": 2}]}:
"/result/*/foo"を使用すると[1,2]を返します。
JSONエクストラクターの割り当て
レスポンス内のフィールドをそのままステートに配置するエクストラクターです。YAML設定は保存する変数のマップです。 左側の文字列はステート内の変数の名前、右側の文字列は変数へのパスです。
JSONエクストラクターはワイルドカードをサポートしています。JSON [{"id":1}, {"id":2}] が与えられた場合、/*/id を使用すると [1,2] を返し、""(空文字列)を使用すると完全なリストを返します。
Copied!1 2 3 4type: json assign: var_name_1: /field-name1 # 変数名1にフィールド名1を割り当て var_name_2: /field_name2 # 変数名2にフィールド名2を割り当て
デフォルトでは、抽出されたフィールドが null 値であるか存在しない場合、呼び出しは失敗します。
これらの状況で呼び出しが失敗しないようにするために、以下のフラグが利用可能です:
allowMissingFieldは、フィールドが存在しないか、フィールドが null 値の場合に失敗しないようにします。allowNullは、存在するフィールドが null 値の場合に失敗しないようにします。allowUnescapedControlCharsは、JSON レスポンスに\nのようなエスケープされていない制御文字が含まれている場合に失敗しないようにします。
Copied!1 2 3 4 5 6 7 8type: json # フィールドが欠落していても許可します allowMissingField: true assign: # field-name1 の値を var_name_1 に割り当てます var_name_1: /field-name1 # field_name2 の値を var_name_2 に割り当てます var_name_2: /field_name2
JSONエクストラクターを追加する
Copied!1 2 3 4type: magritte-rest-append-json-extractor appendFrom: /レスポンス内の配列を追加するフィールド appendFromItem: /抽出する配列要素ごとのフィールド # 任意 appendTo: 要素を追加する状態の変数名。
日本語でのコードコメント:
Copied!1 2 3 4type: magritte-rest-append-json-extractor # magritte-rest-append-json-extractorタイプを指定 appendFrom: /レスポンス内の配列を追加するフィールド # レスポンスから追加する配列が含まれるフィールドを指定 appendFromItem: /抽出する配列要素ごとのフィールド # 任意。配列の各要素から抽出するフィールドを指定 appendTo: 要素を追加する状態の変数名。 # 追加する要素を保持する状態変数の名前を指定
応答が次のようになっている場合:
Copied!1 2 3 4 5 6 7 8 9{ // "things"というキーに対応する値は配列です。 "things": [ // 配列の最初の要素はオブジェクトです。このオブジェクトには"name"と"id"という2つのキーが存在します。 {"name": "dummy", "id": "1"}, // 配列の2つ目の要素もオブジェクトです。このオブジェクトも"name"と"id"という2つのキーが存在します。 {"name": "dummy2", "id": "2"} ] }
その後、YAML は次のようになります:
Copied!1 2 3 4type: magritte-rest-append-json-extractor appendFrom: /things # /things から追加 appendFromItem: /id # /id 項目から追加 appendTo: var # var に追加
結果として、[1,2]がvarに追加されます。
また、以下のようにも使用できます:
Copied!1 2 3type: magritte-rest-append-json-extractor # タイプ:マグリット-REST-追加-JSON-エクストラクタ appendFrom: /things # 追加元:/things appendTo: var # 追加先:var
これにより、state varに [{"name": "dummy", "id": "1"}, {"name": "dummy", "id": "2"}] が追加されます。
Max JSONエクストラクタ
Copied!1 2 3 4 5type: magritte-rest-max-json-extractor list: /レスポンス内の最大値を取得するための配列を含むフィールド。 item: /抽出する配列要素ごとのフィールド var: 最大値を保存するための状態変数。 previousVal: 現在の最大値を取得するための状態変数 # 任意
Copied!1 2 3 4 5 6 7 8 9{ // "things"は配列です。各要素はオブジェクトとして構成されています。 "things": [ // このオブジェクトは二つのプロパティを持っています:"name"と"value"。 {"name": "dummy", "value": "1"}, // このオブジェクトも同様に"name"と"value"の二つのプロパティを持っています。 {"name": "dummy2", "value": "2"} ] }
Copied!1 2 3 4type: magritte-rest-max-json-extractor # タイプ:マグリット-REST-最大-JSON-抽出器 list: /things # リスト:/things(物事) item: /id # アイテム:/id var: max_value # 変数:最大値
これにより、max_valueに2が保存されます。
また、すでにmax_valueに5が存在すると仮定すると:
Copied!1 2 3 4 5type: magritte-rest-max-json-extractor # タイプ: マグリットREST最大JSON抽出器 list: /things # リスト: /things item: /id # 項目: /id var: max_value # 変数: max_value previousVal: max_value # 前回の値: max_value
max_valueは5に等しいままになります。
Streaming JSON最終行抽出器
レスポンスが各行でJSONファイルを含むStreaming JSON(NDJSON)形式の抽出器です。通常、この形式はデータセットを返すために使用されるため、すべての行は同じ形式のJSONを持つべきです。
抽出器は、NDJSONファイルの最後の行からパスから変数を抽出することをサポートしています。
Copied!1 2 3 4 5type: magritte-rest-last-streaming-json-extractor # JSONが{'value':'somevalue', 'id':1}のように見える場合、これは1を抽出します nodePath: /id varName: id # 値を保存するための状態変数の名前 saveNulls: false # nullを変数に保存するかスキップするか(デフォルトはfalse)
ストリーミング JSON 追加エクストラクター
エクストラクターは、NDJSON ファイルの各行から変数を配列に抽出するとともに、最後に遭遇した変数を抽出することをサポートしています。エクストラクターが null(行が欠落している、キーが欠落している、またはキーの下の値が null)に遭遇すると、ループを停止します。
Copied!1 2 3 4 5 6type: magritte-rest-last-streaming-json-extractor nodePath: /id # jsonが{'value':'somevalue', 'id':1}のように見える場合、これは1を抽出します arrayVarName: ids # 配列を保存するための状態の変数の名前 optional<lastVarName>: lastId # 配列の最後の値を保存するための状態の変数の名前 optional<limit>: 10 # 解析する行数を制限します。これはlastVarNameと組み合わせて使用し、 # iterableStateCallと共に抽出実行ごとの呼び出し数を制限することができます
XML 抽出器
XML 抽出器の割り当て
レスポンス内のフィールドを単純に状態に配置する抽出器です。YAML設定は保存する変数のマップです。左側の文字列は状態の変数名で、右側の文字列はxpath表記を使用して変数へのパスです。
Copied!1 2 3 4type: magritte-rest-xml-extractor assign: var_name_1: /top_level_tag/second_level_tag/text() # トップレベルタグの下のセカンドレベルタグのテキストを取得します var_name_2: /top_level_tag/text() # トップレベルタグのテキストを取得します
HTMLエクストラクター
CSSセレクターによってHTMLから抽出します(サポートされるセレクターの構文 ↗)。抽出のための属性を指定することができます。指定しない場合、選択されたエレメントのテキストが返されます。firstが真であれば、エクストラクターは最初のエレメントを文字列または数値として返すことを試みます。このエクストラクターは、不正確なXMLに対しても使用することができます。
Copied!1 2 3 4 5type: magritte-rest-html-extractor var: 'links' # 変数'links'を定義します selector: "a[href$='pdf']" # .pdfで終わるhref属性を持つ<a>要素を選択します attribute: href # 属性'href'を取得します(オプション) first: false # 先頭の要素だけを取得するかどうかを指定します(オプション、デフォルトはfalse)
提供された例では、.pdf で終わるすべてのアンカータグのハイパーメディアリファレンスを、links 変数に文字列の配列として保存します。
文字列抽出器
文字列抽出器
文字列を抽出し、この文字列を定義された変数に割り当てた新しい state を返します。
Copied!1 2# タイプ: マグリット-rest-string-extractor(REST文字列抽出ツール) var: 'variable_name' # 変数: '変数名'
サブストリング抽出器
state の変数からサブストリングを抽出し、それを別の state に保存します。
Copied!1 2 3 4 5 6type: magritte-rest-substr-extractor start: 2 # 部分文字列の開始インデックス length: 5 # 任意, 部分文字列の長さ(開始インデックスを含む)。 # 設定しない場合、部分文字列は開始インデックス以降の全文字列になります。 assign: var_to_save_substring_to # var: state_variable_to_substring - 廃止されました。代わりにfromStateVarを使用してください!
Regexp 抽出器
文字列から1つ以上の正規表現を抽出する抽出器です。yaml設定は保存する変数のマップです。左側の文字列は State内の変数名、右側の文字列はマッチさせる正規表現です。
Copied!1 2 3 4 5 6type: magritte-rest-regexp-extractor assign: # var_name_1は、1で始まり3で終わる文字列またはaで始まりcで終わる文字列を抽出する正規表現パターンを定義します var_name_1: (1(.*)3|a(.*)c) # var_name_2は、"NotInString"という文字列を抽出する正規表現パターンを定義します var_name_2: (NotInString)
入力された文字列が以下の場合:
このコードスニペットは、単なる文字列(abcHelloWorld123)を示しています。プログラムコードとしての機能はありません。したがって、日本語のコメントは必要ありません。ただし、この文字列が何を意味するのかを説明する一般的なコメントを以下に記載します。
Copied!1 2 3 4<!-- この文字列は、アルファベットと数字の組み合わせを示しています。 --> abcHelloWorld123
応答は以下のようになります:
Copied!1 2 3 4 5 6 7{ // "var_name_1": これはキーです。値は ["abc", "123"]という文字列の配列です。 "var_name_1": ["abc", "123"], // "var_name_2": これもキーですが、値は空の配列です。 "var_name_2": [] }
ここでは、HTMLからCSVリンクを抽出し、その後CSVを取得するための完全な使用例を示します:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22type: rest-source-adapter2 # タイプ:rest-source-adapter2 outputFileType: csv # 出力ファイルのタイプ:csv restCalls: # REST呼び出し - type: magritte-rest-call # タイプ:magritte-rest-call path: /my/path/index.html # パス:/my/path/index.html source: mysource # ソース:mysource method: GET # メソッド:GET extractor: # 抽出器 - type: magritte-rest-regexp-extractor # タイプ:magritte-rest-regexp-extractor assign: # 割り当て file_paths: '(?<=https://www\.mysite\.com)(.*filename.*csv)(?=\")' # ファイルパス:https://www.mysite.comから始まり、"filename.*csv"を含み、"で終わる文字列 saveResponse: false # レスポンスを保存するかどうか:いいえ - type: magritte-iterable-state-call # タイプ:magritte-iterable-state-call source: mysource # ソース:mysource timeBetweenCalls: 1s # 呼び出し間の時間:1秒 iterableField: file_paths # 反復可能なフィールド:file_paths method: GET # メソッド:GET path: '{%path%}' # パス:{%path%} saveResponse: true # レスポンスを保存するかどうか:はい iteratorExtractor: # イテレータ抽出器 - type: magritte-rest-string-extractor # タイプ:magritte-rest-string-extractor var: 'path' # 変数:'path'
正規表現置換エクストラクター
文字列の中の一つの正規表現を置換するエクストラクターで、PySparkの関数 pyspark.sql.functions.regexp_replace と同様のものです:
Copied!1 2 3 4type: magritte-rest-regexp-replace-extractor var: result # `state` 変数が結果文字列で作成または上書きされます pattern: "[a]" # 検索する正規表現 replacement: "A" # 正規表現の一致する部分に置き換える新しい文字列
配列の操作
配列への追加または拡張
Append Array Extractor は state 変数を受け取り、配列の末尾にプッシュします。このエクストラクタは、反復可能な state コールにパスを渡すためのパスを収集するのに役立ちます。
Copied!1 2 3type: magritte-rest-append-array-extractor appendTo: target # ターゲットが初期化されていない場合、エクストラクターは空の配列を初期化します。 fromStateVar: args # 単一の引数(append)またはコレクション(extend)を受け入れます
以下は完全な例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30type: rest-source-adapter2 # RESTソースアダプタタイプ2 restCalls: - type: magritte-paging-inc-param-call # ページング増加パラメータコールタイプ method: GET # HTTPメソッドはGET path: category # パスはカテゴリ paramToIncrease: page # 増加するパラメータはページ initValue: 0 # 初期値は0 increaseBy: 100 # 100ずつ増加 parameters: start_element: '{%page%}' # 開始要素はページ num_elements: 100 # 要素数は100 extractor: - type: magritte-rest-json-extractor # JSON抽出タイプ assign: res: /response/categories # resにはレスポンスのカテゴリを割り当てる - type: magritte-rest-append-array-extractor # 配列追加抽出タイプ fromStateVar: res # 状態変数resから appendTo: categories # categoriesに追加する until: type: magritte-rest-non-empty-condition # 非空条件タイプ var: res # 変数はres - type: magritte-iterable-state-call # 反復可能状態コールタイプ method: GET # HTTPメソッドはGET path: 'category/{%category%}' # パスはカテゴリ timeBetweenCalls: 5s # コール間の時間は5秒 iterableField: categories # 反復可能フィールドはカテゴリ iteratorExtractor: - type: magritte-rest-string-extractor # 文字列抽出タイプ var: category # 変数はカテゴリ outputFileType: json # 出力ファイルタイプはJSON
その他のエクストラクター
HTTPステータスコードエクストラクター
レスポンスからHTTPステータスコードを抽出します。
Copied!1 2type: magritte-rest-http-status-code-extractor # typeは、magritte-rest-http-status-code-extractorという種類のエクストラクタを指定します。 assign: 'variable_name' # assignは、抽出したHTTPステータスコードを代入する変数の名前を指定します。
Set-Cookie レスポンスヘッダー抽出器
レスポンス内の Set-Cookie ヘッダーからクッキーを抽出します。
Copied!1 2 3 4 5 6type: magritte-rest-set-cookie-header-extractor # タイプは "magritte-rest-set-cookie-header-extractor"(MagritteのRESTセットクッキーヘッダーエクストラクタ) assign: var_name_1: cookie_name_in_set_cookie_header # "assign"は変数に値を割り当てます。 # ここでは、"var_name_1"という変数に"cookie_name_in_set_cookie_header"という値が割り当てられています。
配列要素抽出器
指定された配列から要素を抽出します。
Copied!1 2 3 4 5 6 7type: magritte-rest-array-element-extractor # 状態変数から要素を抽出するための配列変数 fromStateVar: Array var to extract an element from. # 入力配列内の要素のインデックスを抽出する index: The index of the element in the input array to extract. # 要素を抽出する変数の名前 toStateVar: Name of the variable to extract the element to.
指定されたインデックスのパラメーターは、配列の終わりから開始するために負の値にすることができます。たとえば、最後の要素を抽出するためには-1を使用します。
タイプキャスト抽出器
ある変数を入力として受け取り、事前に定義されたキャストロジックを使用して変数のタイプをキャストし、結果を宛先の変数に保存する抽出器です。
Copied!1 2 3 4type: magritte-rest-typecast-extractor fromStateVar: 抽出器への入力変数。 # Input variable to the extractor. toStateVar: 抽出器の出力変数。 # Output variable of the extractor. toType: キャスティング後の出力変数のタイプ。 # Type of the output variable after casting.
toType パラメーターは 'java.lang.' パッケージ内の有効な Java タイプでなければなりません。
有効なタイプの例としては 'String', 'Integer' だけでなく、完全な 'java.lang' パッケージと名前:'java.lang.Double'も含まれます。
タイプキャスティングを機能させるためには、入力変数のタイプを出力タイプにキャストするための事前定義されたメソッドが存在しなければなりません。 これは、プラグイン内のコードで、設定されたタイプから変数をトランスフォームする必要があることを意味します。
注:2つの文字列 a と b の java.util.Arrays を String にキャストすると [a, b] が得られます。一方、2つの文字列 a と b の com.fasterxml.jackson.databind.node.ArrayNode を String にキャストすると ["a","b"] が得られます。これは、JSON 配列の文字列表現です。
条件
条件は ElasticSearch の条件と同様に機能します。現在サポートされている条件は次のとおりです:
正規表現
Copied!1 2 3type: magritte-rest-regex-condition # タイプ: マグリット-レスト-レジェックス-コンディション var: a state variable key # 変数: 状態変数キー matches: a valid regular expression # マッチ: 有効な正規表現
例:
Copied!1 2 3type: "magritte-rest-regex-condition" # 条件のタイプは "magritte-rest-regex-condition"(正規表現による条件)です。 var: my_state_variable # 条件の対象となる変数は "my_state_variable" です。 matches: '^\d+$' # 条件は、変数の値が全て数字(0-9)であることを確認します。'^\d+$' は正規表現で、文字列が一つ以上の数字で構成されていることを確認します。
利用可能な条件
指定された変数が利用可能かどうか(それが非 null 値に割り当てられているかどうか)を確認します。
Copied!1 2 3 4 5type: magritte-rest-available-condition # type: magritte-rest-available-conditionとは、Magritteフレームワークで使用される特定のタイプを指します。これはREST APIが利用可能な条件を表すオブジェクトのタイプを指定します。 var: a state variable key # var: 状態変数のキーとは、特定の状態や値を参照するための識別キーを指します。これは通常、プログラムの状態を管理するために使用されます。
Copied!1 2 3 4# 'type'は条件チェックの種類を示します。ここでは'magritte-rest-available-condition'が指定されています。 type: magritte-rest-available-condition # 'var'はチェックする状態変数を示します。ここでは'my_state_variable'が指定されています。 var: my_state_variable
非空条件
指定された変数が利用可能で、空でないかを確認します。
Copied!1 2type: magritte-rest-non-empty-condition # タイプ: マグリット-REST-非空条件 var: a state variable key # 変数: 状態変数キー
Copied!1 2 3 4# この部分はMagritteのREST非空条件を示しています type: magritte-rest-non-empty-condition # my_array_state_variableは監視する変数の名前です var: my_array_state_variable
Not 条件
与えられたサブ条件を否定します。
Copied!1 2type: magritte-rest-not-condition condition: 否定する条件。
コメント:
Copied!1 2type: magritte-rest-not-condition # 条件を否定するための種類 condition: A condition to negate. # 否定するための条件
Copied!1 2 3 4 5 6 7 8 9 10 11 12type: magritte-rest-not-condition # 条件タイプ: magritte-rest-not-condition # この条件は、以下に定義された条件が満たされない場合に真となります。 condition: type: magritte-rest-available-condition # 条件タイプ: magritte-rest-available-condition # この条件は、指定された変数が存在し、その値が空でない場合に真となります。 var: my_state_variable # 変数: my_state_variable # この条件でチェックする変数の名前です。
AND 条件
与えられたすべてのサブ条件が真であることを要求します。
Copied!1 2type: magritte-rest-and-condition conditions: AND 演算子で組み合わせる条件のリスト。
Copied!1 2 3 4 5 6 7 8type: magritte-rest-and-condition conditions: - type: magritte-rest-available-condition var: my_state_variable # 日本語: 状態変数が利用可能かどうかを判断する条件 - type: magritte-rest-non-empty-condition var: my_array-state_variable # 日本語: 配列の状態変数が空でないかどうかを判断する条件
バイナリ条件
Copied!1 2 3 4 5type: magritte-rest-binary-condition toCompare: left: `state` キーは条件の左側で比較します right: `state` キーは条件の右側で比較します op: 以下のいずれか "=", "<", ">", "<=", ">="
Copied!1 2 3 4 5 6 7 8 9 10 11 12type: magritte-rest-binary-condition # 「magritte-rest-binary-condition」型:Magritteを使ったRESTバイナリ条件式を指定します。 toCompare: left: a_state_variable # 左:「a_state_variable」変数を指定します。 right: another_state_variable # 右:「another_state_variable」変数を指定します。 op: < # 演算子:「<」(小なり)を使用します。これは左側の変数が右側の変数より小さいかどうかを比較します。
式
式は、Magritte REST同期中の任意の場所で特定の値を計算するために使用できます。エクストラクターとは対照的に、式の結果は同期の state に依存しません。
DateTime 式
特定の日付と/または時間を提供する式。現在の日付/時間を取得し、指定されたオフセットを追加することから始まります。
この初期 state 変数のための他のパラメーター(たとえば、トップレベルの initialStateVars: ブロックに配置するべきです):
Copied!1 2 3 4 5 6 7 8 9type: magritte-rest-datetime-expression # typeは、magritte-rest-datetime-expressionを指します。 offset: Optional. Time to add or substract from the current date/time. Can be negative. # offsetはオプションです。現在の日時から追加または引く時間です。負の値も可能です。 timezone: Optional. Which timezone to calculate the date/time for. Defaults to UTC. # timezoneはオプションです。日付/時間を計算するためのタイムゾーンを指定します。デフォルトはUTCです。 formatString: Optional. Output format of the calculated date and time. Defaults to ISO 8601 datetime with offset. # formatStringはオプションです。計算された日付と時間の出力形式です。デフォルトはオフセット付きのISO 8601 datetimeです。
有効なオフセットについては、Java 8 Duration documentation ↗を参照してください。
有効なタイムゾーンについては、Java 8 ZoneId documentation ↗を参照してください。
有効な出力形式の文字列については、Java 8 DateTimeFormatter ↗を参照してください。
リテラル表現
リテラル値を提供する表現。
リテラルのタイプは自動的に推測され、リテラル表現のログを見ることで確認できます。現在サポートされているタイプは文字列、数値、リストです。
Copied!1 2type: magritte-rest-literal-expression literalValue: Required. # 必須。
Copied!1 2 3 4type: magritte-rest-literal-expression literalValue: 270 # タイプ:マグリット-REST-リテラル-式 # リテラル値:270
リストの例:
Copied!1 2 3 4type: magritte-rest-literal-expression # リテラル値: プログラム内で固定の値として表現される値 literalValue: ["it's", "a", "kind", "of", "magic"] # リテラル値:"it's", "a", "kind", "of", "magic"という文字列の配列
Foundry での JSON の処理
JSON データを取り込む際に:
Copied!1 2 3 4 5 6 7 8 9 10{ "response": { "size": 1000, // レスポンスのサイズ(項目数) "items": [ { "item id": 1, "status": { "modifiedAt": "2020-02-11" }, "com.palantir.metadata": { ... } }, // 項目1の情報 { "item id": 2, "status": { "modifiedAt": "2020-02-12" }, "com.palantir.metadata": { ... } }, // 項目2の情報 { "item id": 3, "status": { "modifiedAt": "2020-02-13" }, "com.palantir.metadata": { ... } } // 項目3の情報 ] } }
magritte-rest-v2 プラグインを使用すると、各JSONレスポンスがデータセット内の別々のファイルとして保存されます。
このデータを簡単に処理するために、生のデータセットにスキーマを設定します:
{
// フィールドのスキーマのリスト
"fieldSchemaList": [
{
"type": "STRING", // データ型は文字列
"name": "row", // フィールド名は"row"
"nullable": null, // null値を許可するかどうか
"userDefinedTypeClass": null, // ユーザー定義型のクラス
"customMetadata": {}, // カスタムメタデータ
"arraySubtype": null, // 配列のサブタイプ
"precision": null, // 精度
"scale": null, // スケール
"mapKeyType": null, // マップキーの型
"mapValueType": null, // マップ値の型
"subSchemas": null // サブスキーマ
}
],
// データフレームリーダークラス
"dataFrameReaderClass": "com.palantir.foundry.spark.input.DataSourceDataFrameReader",
// カスタムメタデータ
"customMetadata": {
"format": "text", // フォーマットはテキスト
"options": {} // オプション
}
}
このデータセットをクリーニングし、各itemをデータセットの別々の行として、そしてitemフィールドを列として持つために、Pythonトランスフォームリポジトリを作成します。
以下のスニペットを新しいutils/read_json.pyファイルに追加してください:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47from pyspark.sql import functions as F import json import re # スキーマをフラット化する関数 def flattenSchema(df, dontFlattenCols=[], jsonCols=[]): new_cols = [] # 全ての列に対してフラット化を試みる for col in df.schema: _flattenSchema(col, [], new_cols, dontFlattenCols + jsonCols, jsonCols) print(new_cols) # 新しい列を選択してDataFrameを返す return df.select(new_cols) # スキーマのフラット化を実行する内部関数 def _flattenSchema(field, path, cols, dontFlattenCols, jsonCols): curentPath = path + [field.name] currentPathStr = '.'.join(curentPath) # フィールドがstruct型であり、またフラット化しない列リストに存在しない場合、フラット化を行う if field.dataType.typeName() == 'struct' and currentPathStr not in dontFlattenCols: for field2 in field.dataType.fields: _flattenSchema(field2, curentPath, cols, dontFlattenCols, jsonCols) else: fullPath = '.'.join(['`{0}`'.format(col) for col in curentPath]) newName = '_'.join(curentPath) sanitized = re.sub('[ ,;{}()\n\t\\.]', '_', newName) # json列の場合、json形式で列を追加する if currentPathStr in jsonCols: cols.append(F.to_json(fullPath).alias(sanitized)) else: cols.append(F.col(fullPath).alias(sanitized)) # jsonを解析する関数 def parse_json(df, node_path, spark): rdd = df.dataframe().rdd.flatMap(get_json_rows(node_path)) df = spark.read.json(rdd) return df # jsonの各行を取得する関数 def get_json_rows(node_path): def _get_json_object(row): parsed_json = json.loads(row[0]) node = parsed_json for segment in node_path: node = node[segment] return [json.dumps(x) for x in node] return _get_json_object
次のようなコードを使用して Pythonトランスフォームを作成できます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13# 必要なライブラリをインポートします from transforms.api import transform, Input, Output from utils import read_json # トランスフォームデコレータを使って、入力と出力を指定します @transform( output=Output("/output"), # 出力パスを指定します json_raw=Input("/raw/json_files"), # 入力パスを指定します ) def my_compute_function(json_raw, output, ctx): # my_compute_functionという名前の関数を定義します df = read_json.parse_json(json_raw, ['response', 'items'], ctx.spark_session) # jsonファイルをパースしてデータフレームに変換します df = read_json.flattenSchema(df, jsonCols=['com.palantir.metadata']) # ネストされたスキーマをフラットにします output.write_dataframe(df) # 最終的なデータフレームを出力します
これによりデータセットが作成されます:
こちらの表には3つの列があります:
item_id(アイテムID): アイテムの一意の識別子です。status_modifiedAt(ステータスの変更日): アイテムのステータスが最後に変更された日付を示します。com_palantir_metadata(パランティアメタデータ): アイテムに関する追加の情報を含むメタデータです。データはJSON形式で保存されています。
Copied!1 2 3 4item_id | status_modifiedAt | com_palantir_metadata 1 | "2020-02-11" | "{ ... }" <!-- アイテムIDが1のアイテムのステータスは2020年2月11日に最後に変更されました。--> 2 | "2020-02-12" | "{ ... }" <!-- アイテムIDが2のアイテムのステータスは2020年2月12日に最後に変更されました。--> 3 | "2020-02-13" | "{ ... }" <!-- アイテムIDが3のアイテムのステータスは2020年2月13日に最後に変更されました。-->