注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
BigQuery
Foundry と Google BigQuery を接続して、BigQuery テーブルと Foundry データセット間でデータを読み取り同期します。
サポートされる機能
| 機能 | ステータス |
|---|---|
| 探索 | 🟢 一般提供 |
| バルクインポート | 🟢 一般提供 |
| インクリメンタル | 🟢 一般提供 |
| バーチャルテーブル | 🟢 一般提供 |
| エクスポートタスク | 🟡 サンセット |
データモデル
BigQuery からのテーブルは Foundry にインポートされ、データは Avro 形式で保存されます。BIGNUMERIC と TIME 型の列はインポート時にはサポートされていません。
Foundry から BigQuery にデータをエクスポートする際には、MAPS、STRUCTS、および ARRAYS を除くすべての列型がサポートされます。
パフォーマンスと制限
非標準の BigQuery テーブルから 20GB 以上のデータを同期する場合は、一時ストレージテーブルを有効にする必要があります。1 回の同期でディスク上に使用可能なサイズまでのデータをインポートできます。直接接続を通じて実行される同期では、通常 600GB までが制限となります。より大きなテーブルをインポートするにはインクリメンタル同期を使用してください。
設定
- Data Connection アプリケーションを開き、画面右上の + New Source を選択します。
- 利用可能なコネクタタイプから BigQuery を選択します。
- インターネット経由で 直接接続 を使用するか、中間エージェントを通じて接続 するかを選択します。
- 以下のセクションの情報を使用してコネクタの設定を続行するための追加構成プロンプトに従います。
Foundry でのコネクタの設定についてさらに詳しく学びましょう。
BigQuery の認証と設定を進めるには Google Cloud IAM サービスアカウント ↗ が必要です。
認証
BigQuery コネクタを使用するには、以下の Identity and Access Management (IAM) ロールが必要です。
BigQuery データを読み取る:
BigQuery Read Session User: BigQuery プロジェクトに付与BigQuery Data Viewer: データとメタデータを読み取るために BigQuery データに付与BigQuery Job User(オプション): ビューを取り込んだり、カスタムクエリを実行するために付与
Foundry から BigQuery にデータをエクスポートする:
BigQuery Data Editor: BigQuery データセットまたはプロジェクトに付与BigQuery Job User: BigQuery プロジェクトに付与Storage Object Admin: Google Cloud Storage でデータをエクスポートする場合、バケットに付与
一時テーブルを使用する:
BigQuery Data Editor: コネクタによってデータセットが自動的に作成される場合、BigQuery プロジェクトに付与BigQuery Data Editor: 一時テーブルを保存するために提供されたデータセットに付与
必要なロールの詳細については、アクセス制御に関する Google Cloud ドキュメント ↗を参照してください。
利用可能な認証方法のいずれかを選択してください:
-
GCP インスタンスアカウント: インスタンスベースの認証の設定方法については、Google Cloud ドキュメント ↗を参照してください。
- GCP インスタンス認証は、GCP 内の適切に構成されたインスタンスでエージェントを実行するコネクタに対してのみ機能します。
- バーチャルテーブル は GCP インスタンス認証資格情報をサポートしていません。
-
サービスアカウントキーファイル: サービスアカウントキーファイル認証の設定方法については、Google Cloud ドキュメント ↗を参照してください。キーファイルは JSON または PKCS8 資格情報として提供できます。
-
Workload Identity Federation (OIDC): 表示されるソースシステム構成手順に従って OIDC を設定します。Workload Identity Federation の詳細については Google Cloud ドキュメント ↗を参照し、Foundry で OIDC がどのように機能するかについてはこちらのドキュメントを参照してください。
ネットワーキング
BigQuery コネクタはポート 443 で以下のドメインへのネットワークアクセスを必要とします:
bigquery.googleapis.combigquerystorage.googleapis.comstorage.googleapis.comwww.googleapis.com
以下のドメインへの追加アクセスが必要になる場合があります:
oauth2.googleapis.comaccounts.google.com
Google Cloud Platform (GCP) 上の Foundry と GCP 上の BigQuery 間で直接接続を確立する場合は、関連する VPC サービスコントロールを通じて接続を有効にする必要があります。この接続がユーザーの設定に必要な場合は、追加のガイダンスについて Palantir サポートに連絡してください。
接続の詳細
BigQuery コネクタには以下の構成オプションが利用可能です:
| オプション | 必須? | 説明 |
|---|---|---|
Project ID | はい | BigQuery プロジェクトの ID; このプロジェクトは BigQuery のコンピューティング使用量に対して請求されます |
Credentials settings | はい | 上記の認証ガイダンスを使用して構成します。 |
Cloud Storage bucket | いいえ | BigQuery にデータを書き込むためのステージング場所として使用する Cloud Storage バケットの名前を追加します。 |
Proxy settings | いいえ | BigQuery へのプロキシ接続を許可するために有効にします。 |
Settings for temporary tables | いいえ* | 一時テーブルを使用するために有効にします。 |
gRPC Settings | いいえ | gRPC チャネルを構成するための高度な設定です。 |
Additional projects | いいえ | 同じ接続によってアクセスされる必要がある追加のプロジェクトの ID を追加します。このコネクタの資格情報として使用される Google Cloud アカウントはこれらのプロジェクトにアクセスできる必要があります。コネクタ Project Id は BigQuery データアクセスまたはコンピューティング使用量に対して請求されます。 |
* 一時テーブルは、バーチャルテーブル経由でBigQuery ビュー ↗を登録する際に有効にする必要があります。
BigQuery からデータを同期
BigQuery 同期を設定するには、ソース 概要 画面の右上で Explore and create syncs を選択します。次に、Foundry に同期したいテーブルを選択します。同期の準備ができたら、Create sync for x datasets を選択します。
Foundry でのソース探索についてさらに詳しく学びましょう。
一時テーブル
非標準の BigQuery テーブルから 20GB 以上のデータを同期する場合、一時テーブルを有効にする必要があります。一時テーブルを使用すると、BigQuery は大規模なクエリ出力からのインポート、ビューやその他の非標準テーブルからのデータインポート、および大規模なインクリメンタルインポートとインジェストを行うことができます。
一時テーブルを使用するには、コネクタ構成で Settings for temporary tables を有効にします。
- データセットを自動的に作成: このオプションを選択して、一時テーブルを保存するための
Palantir_temporary_tablesデータセットを作成します。このオプションには、BigQuery アカウントにプロジェクト上のBigQuery Data Editorロールが必要です。 - 使用するデータセットを提供: このオプションを選択して、一時テーブルを保存するデータセットの
Project IDとDataset nameを手動で追加します。このオプションには、提供されたデータセット上のBigQuery Data Editorロールが必要です。
バーチャルテーブルでBigQuery ビュー ↗を使用する場合、一時テーブルを有効にする必要があることに注意してください。
BigQuery 同期の構成
BigQuery コネクタは、大規模なデータ同期やカスタムクエリのための高度な同期構成を可能にします。
利用可能な同期を探索し、それらをコネクタに追加した後、Edit syncs に移動します。左側の Syncs パネルから構成したい同期を見つけて、右側の > を選択します。
インポート設定
BigQuery から Foundry に同期されるデータを選択します。
テーブル全体の同期
テーブル全体を Foundry に同期するために以下の情報を入力します。
| オプション | 必須? | 説明 |
|---|---|---|
BigQuery project Id | いいえ | テーブルが属するプロジェクトの ID。 |
BigQuery dataset | はい | テーブルが属するデータセットの名前。 |
BigQuery table | いいえ | Foundry に同期されるテーブルの名前。 |
カスタム SQL
任意のクエリを実行し、その結果を Foundry に保存できます。クエリの出力は 20GB 未満である必要があり(BigQuery テーブルの最大サイズ)、一時テーブルの使用が有効である必要があります。クエリはキーワード select または with で始まる必要があります。たとえば: SELECT * from table_name limit 100;。
インクリメンタル同期
通常、同期はターゲットテーブルから一致するすべての行をインポートしますが、データが同期間で変更されたかどうかに関係なく行います。対照的に、インクリメンタル同期は、最新の同期に関する状態を維持し、新しい一致する行のみをインジェストします。
インクリメンタル同期は、BigQuery から大規模なテーブルをインジェストする場合に使用できます。インクリメンタル同期を使用するには、テーブルに厳密に単調増加する列が含まれている必要があります。さらに、読み取られるテーブルまたはクエリには、次のデータ型のいずれかの列が含まれている必要があります:
INT64FLOAT64NUMERICBIGNUMERICSTRINGTIMESTAMPDATETIMEDATETIME
例: 5 TB のテーブルには数十億行が含まれており、これを BigQuery に同期したいとします。テーブルには id という単調増加する列があります。この同期は、インクリメンタル列として id 列を使用し、初期値を -1 に設定し、1 回の同期で 5000 万行をインジェストするように構成できます。
同期が初めて実行されると、id 値が -1 より大きい最初の 5000 万行(id に基づいて昇順)が Foundry にインジェストされます。たとえば、この同期が数回実行され、この同期の最後の実行中にインジェストされた最大の id が 19384004822 であった場合、次の同期では 19384004822 より大きい最初の id から始まる次の 5000 万行がインジェストされます。
インクリメンタル同期には、以下の構成が必要です。
| オプション | 必須? | 説明 |
|---|---|---|
| 列 | はい | インクリメンタルインジェストに使用する列を選択します。テーブルにサポートされている列型が含まれていない場合、ドロップダウンは空です。 |
Initial value | はい | データの同期を開始する値。 |
Limit | いいえ | 1 回の同期でダウンロードするレコードの数。 |
カスタムクエリのインクリメンタル同期
カスタムクエリ同期でインクリメンタルクエリを有効にするには、クエリを次の形式に一致させるように更新する必要があります:
SELECT * from table_name where incremental_column_name > @value order by incremental_column_name asc limit @limit
BigQuery へのデータのエクスポート
コネクタは 2 つの方法で BigQuery にエクスポートできます:
- 中間ストアとして Google Cloud Storage を使用(推奨)。詳細は以下のCloud Storage 経由のエクスポートセクションを参照してください。
- BigQuery API 経由のエクスポート。詳細はローカルファイルからのデータの読み取り ↗を参照してください。
API を使用した書き込みは、数百万行のデータスケールに適しています。このモードでの期待されるパフォーマンスは、約 2 分で 100 万行をエクスポートすることです。データスケールが数十億行に達する場合は、Google Cloud Storage を使用してください。
タスク構成
データのエクスポートを開始するには、エクスポートタスクを構成する必要があります。コネクタをエクスポートするプロジェクトフォルダーに移動し、コネクタ名を右クリックして Create Data Connection Task を選択します。
Data Connection ビューの左側パネルで、Source 名が使用したいコネクタと一致していることを確認します。次に、Input フィールドに入力データセットを追加します。入力データセットは inputDataset と呼ばれ、Foundry からエクスポートされるデータセットです。エクスポートタスクには 1 つの Output も構成する必要があります。出力データセットは outputDataset と呼ばれ、Foundry データセットを指します。出力データセットはタスクの実行、スケジュール、および監視に使用されます。
Data Connection ビューの左側パネルで:
Source名が使用したいコネクタと一致していることを確認します。inputDatasetという名前のInputを追加します。入力データセットは Foundry からエクスポートされるデータセットです。outputDatasetという名前のOutputを追加します。出力データセットはタスクの実行、スケジュール、および監視に使用されます。- 最後に、テキストフィールドにタスク構成を定義するための YAML ブロックを追加します。
左側パネルに表示されるコネクタおよび入力データセットのラベルは、YAML で定義された名前を反映していません。
エクスポートタスク YAML を作成する際に、以下のオプションを使用します:
| オプション | 必須? | デフォルト | 説明 |
|---|---|---|---|
project | いいえ | コネクタのプロジェクト ID | 宛先テーブルが属するプロジェクトの ID。 |
dataset | はい |
Copied!1 2 3 4 5 6 7type: magritte-bigquery-export-task config: table: dataset: datasetInBigQuery # BigQuery内のデータセット table: tableInBigQuery # BigQuery内のテーブル project: projectId #(Optional: Do not specify unless the Project for export differs from the Project configured for the connector.) # (オプション: エクスポート用のプロジェクトがコネクターで設定されたプロジェクトと異なる場合のみ指定してください。) incrementalType: SNAPSHOT | REQUIRE_INCREMENTAL # インクリメンタルタイプ:スナップショット | インクリメンタルが必要
Parquet形式で保存された行を含むデータセットのみがBigQueryへのエクスポートをサポートしています。
エクスポートタスクを設定した後、右上隅の Save を選択します。
出力テーブルに行を追加
宛先テーブルに行を追加する必要がある場合、データセットを置き換えるのではなく REQUIRE_INCREMENTAL を使用できます。
インクリメンタル同期は、行が入力データセットにのみ追加されること、およびBigQueryの宛先テーブルがFoundryの入力データセットのスキーマと一致することを必要とします。
Cloud Storage 経由でのエクスポート (推奨)
Cloud Storage 経由でエクスポートするには、コネクタの設定でCloud Storageバケットを設定する必要があります。また、このCloud Storageバケットはコネクタの一時テーブルのためだけに使用され、バケットに一時的に書き込まれるデータはできるだけ少ないユーザーがアクセスできるようにする必要があります。
BigQuery APIよりもCloud Storage経由でBigQueryにエクスポートすることを推奨します。Cloud Storageは大規模な運用に適しており、BigQueryに一時テーブルを作成しません。
BigQuery API 経由でのエクスポート
エクスポートジョブは宛先テーブルに加えて一時テーブルを作成します。この一時テーブルには追加のアクセス制限は適用されません。また、SNAPSHOTエクスポートはテーブルを削除して再作成するため、追加のアクセス制限も削除されます。
BigQuery API 経由でエクスポートする際、データは一時テーブル datasetName.tableName_temp_$timestamp にエクスポートされます。エクスポートが完了すると、行は自動的に一時テーブルから宛先テーブルに転送されます。
HiveテーブルのパーティションはBigQuery APIを通じてエクスポートすることはサポートされていません。Hiveテーブルでパーティション分割されたデータセットの場合、Cloud Storageを通じてエクスポートしてください。
エクスポートが REQUIRE_INCREMENTAL モードで実行されている場合、宛先テーブルを共有できます。SNAPSHOT モードで実行すると、各実行時にテーブルが再作成され、共有を再適用する必要があります。
BigQuery APIを通じてエクスポートするには、エクスポートされたテーブルにBigQueryの行レベルまたは列レベルの権限を適用しないでください。
仮想テーブル
このセクションでは、BigQueryソースを使用した仮想テーブルの使用に関する追加の詳細を提供します。このセクションはFoundryデータセットへの同期には適用されません。
| 仮想テーブルの機能 | ステータス |
|---|---|
| ソース形式 | 🟢 一般利用可能: テーブル、ビュー、マテリアライズドビュー |
| 手動登録 | 🟢 一般利用可能 |
| 自動登録 | 🟢 一般利用可能 |
| プッシュダウンコンピュート | 🟢 一般利用可能; BigQuery Spark connector ↗ 経由で利用可能 |
| インクリメンタルパイプラインのサポート | 🟢 一般利用可能: APPEND のみ [1] |
BigQueryはUPDATEやDELETEの変更情報を提供しないため、仮想テーブルを利用したインクリメンタルパイプラインはAPPENDのみのソーステーブルに基づいて構築することが重要です。詳細については公式のBigQueryドキュメント ↗をご覧ください。
仮想テーブルを使用する場合、以下のソース設定要件を覚えておいてください。
- ソースを直接接続として設定する必要があります。仮想テーブルは中間エージェントの使用をサポートしていません。
- このドキュメントのネットワークセクションに記載されているように、双方向接続と許可リストの設定を確立してください。
- Code Repositoriesで仮想テーブルを使用する場合、追加のソース設定の詳細については仮想テーブルのドキュメントを参照してください。
- サービスアカウントのキーファイル資格情報またはWorkload Identity Federation (OIDC)を使用してください。インスタンスベースの認証は仮想テーブルではサポートされていません。
- 一時テーブルを有効にしてBigQueryビュー ↗を登録し、関連する役割を認証資格情報に追加する必要があります。
詳細については、接続の詳細および一時テーブルセクションを参照してください。
[1] BigQuery仮想テーブルを利用したパイプラインのインクリメンタルサポートを有効にするには、適切な保持期間でTime Travel ↗を有効にしてください。この機能はChange History ↗に依存しており、現在はAPPENDのみです。Pythonトランスフォームのcurrentおよびaddedリードモードがサポートされています。_CHANGE_TYPEおよび_CHANGE_TIMESTAMP列はPythonトランスフォームで利用可能になります。
トラブルシューティング
Not found: Dataset <dataset> was not found in location <location>
BigQueryは、クエリが使用する入力やクエリの結果が保存される場所に基づいて、クエリが実行される場所を決定します。一時テーブルが使用される場合、出力は一時テーブルデータセットの一時テーブルに設定されます。このデータセットの場所がクエリの実行場所を決定します。同期のすべての入力と一時テーブルデータセットが同じリージョンにあることを確認してください。Automatically create dataset 設定が有効になっている場合、Google CloudコンソールまたはGoogleのSDK/APIを使用して Palantir_temporary_tables というデータセットの場所を確認してください。
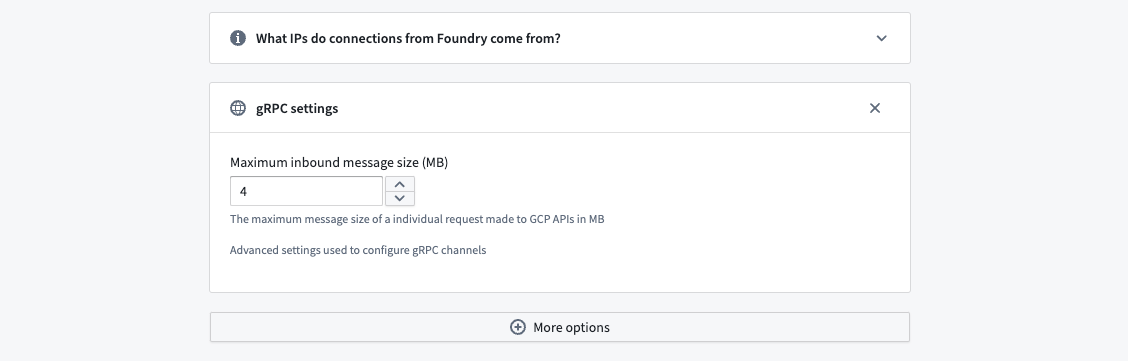
gRPCメッセージが最大サイズを超える
JSON列のような大きなコンテンツを含むデータを同期する場合、上記のエラーで転送が失敗することがあります。BigQueryのMaximum inbound message sizeをgRPC Settingsで調整して、1回のAPIコールでのデータ転送を増やしてください。1回のコールで複数の行を取得するため、最大行サイズに設定するだけでは不十分な場合があります。
この設定オプションは、Connection Settings > Connection Details に移動し、More options をスクロールして gRPC Settings を選択することで見つけることができます。