- Capabilities
- Getting started
- Architecture center
- Platform updates
Document processing
This page will discuss a few useful considerations for extracting data from a PDF document or image.
Data extraction
This page offers a basic guide for using Pipeline Builder to parse PDFs for semantic search and includes a recommendation for presenting the information in a Workshop application when you just have text content.
Semantic search is a powerful tool to use with PDFs, particularly if the content is broken down into smaller "chunks" that are embedded separately, helping users and workflows find important information that might otherwise be hard to access. This is especially useful considering the vast amount of unstructured knowledge in PDFs that often goes unnoticed.
To use, simply upload your PDFs to Foundry, extract the text, chunk the same text, search for those chunks, and surface the results of that search with the corresponding PDF rendered on the side for source-of-truth cross-validation for the users.
Follow the steps outlined below to import PDFs and extract text from PDFs:
- Import the PDFs as a media set.
- Add the media set to Pipeline Builder.
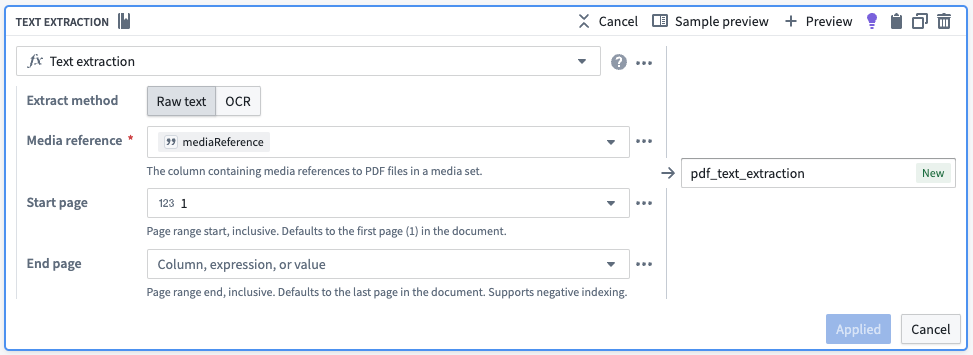
- Use the Get Media References board.

- Use the Text Extraction board.
Chunking
This page outlines how to incorporate a basic chunking strategy into your semantic search workflows. Chunking, in this context, means breaking up larger pieces of text into smaller pieces of text. This is advantageous because embedding models possess a maximum input length for text, and crucially, smaller pieces of text will be more semantically distinct during searches. Chunking is often used when parsing large documents like PDFs.
Primarily, the objective is to split long text into smaller "chunks", each with an associated Ontology object linked back to the original object.
Chunking example
As a starting point, we will show how a basic chunking strategy can be accomplished without using code in Pipeline Builder. For more advanced strategies, we recommend using a code repository as part of your pipeline.
For illustrative purposes, we will use a simple two row dataset with two columns, object_id and object_text. For ease of understanding, the object_text examples below are purposefully short.
| object_id | object_text |
|---|---|
| abc | gold ring lost |
| xyz | fast cars zoom |
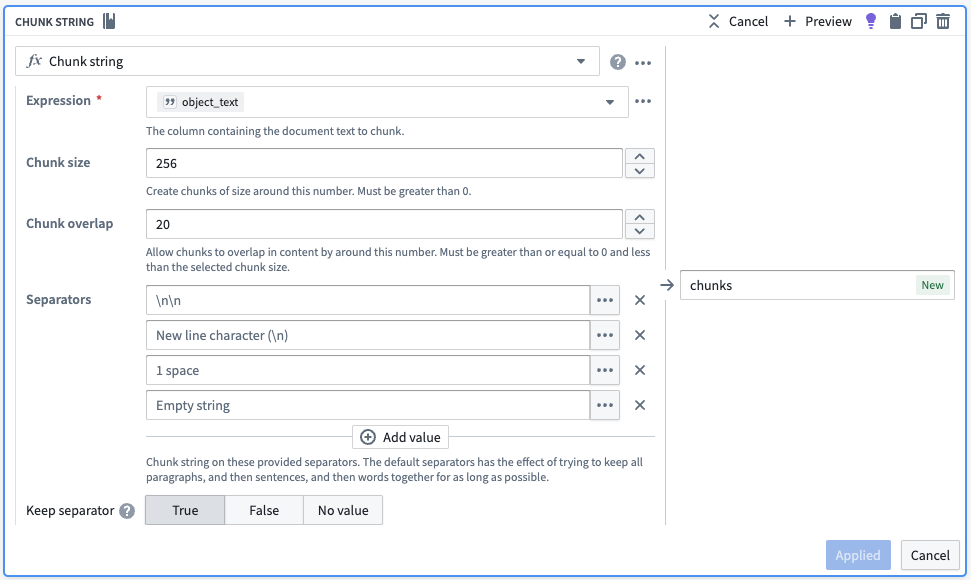
We initiate the process by employing the Chunk String board, which introduces an extra column containing an array of object_text segmented into smaller pieces. The board accommodates various chunking approaches, such as overlap and separators, to ensure that each semantic concept remains coherent and unique.
The below screenshot of a Chunk String board shows a simple strategy which you may alter for use toward your own use case. The below configuration would attempt to return chunks that are roughly 256 characters in size. Effectively, the board splits text on the highest priority separator until each chunk is equal to or smaller than the chunk size. If there are no more highest priority separators to split on and some chunks are still too large, it moves to the next separator until either all the chunks are equal or smaller than the chunk size or there are no more separators to use. Finally, the board will ensure that for each chunk identified, the chunk following has an overlap that covers the last 20 characters of the previous chunk.
| object_id | object_text | chunks |
|---|---|---|
| abc | gold ring lost | [gold,ring,lost] |
| xyz | fast cars zoom | [fast,cars,zoom] |
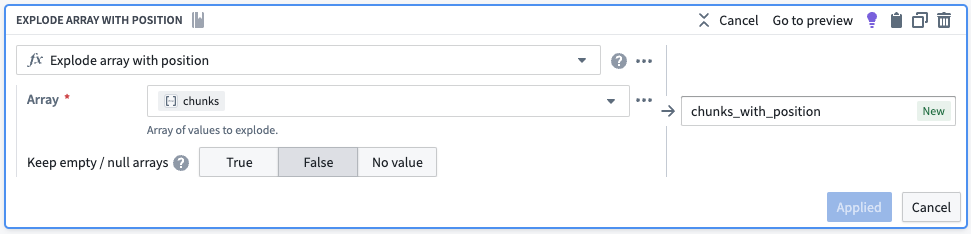
Next we want each element in the array to have its own row. We will use the Explode Array with Position board to transform our dataset to one with six rows. The new column in each of the rows (as seen below) is a struct (map) with two key-value pairs, the position in the array and the element in the array.
| object_id | object_text | chunks | chunks_with_position |
|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} |
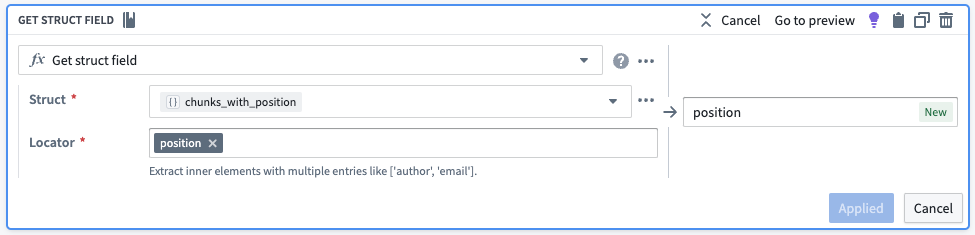
From there, we will pull out the position and the element into their own columns.
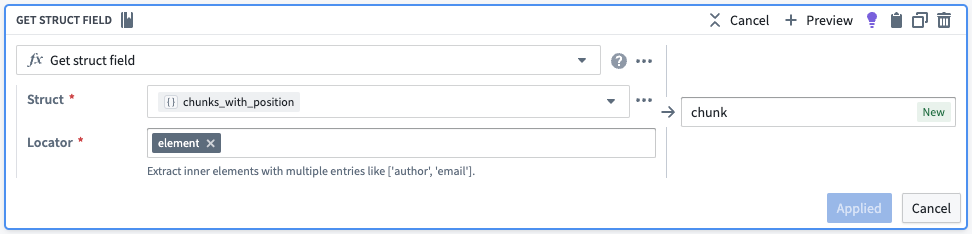
| object_id | object_text | chunks | chunks_with_position | position | chunk |
|---|---|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} | 0 | gold |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} | 1 | ring |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} | 2 | lost |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} | 0 | fast |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} | 1 | cars |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} | 2 | zoom |
To create a unique identifier for each chunk, we will convert the chunk position in its array to a string and then concatenate it to the original object ID. We will also drop the unnecessary columns.
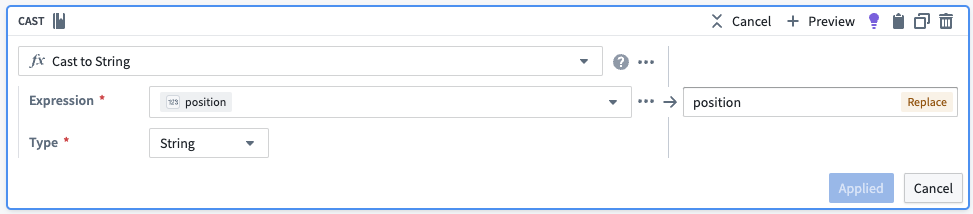
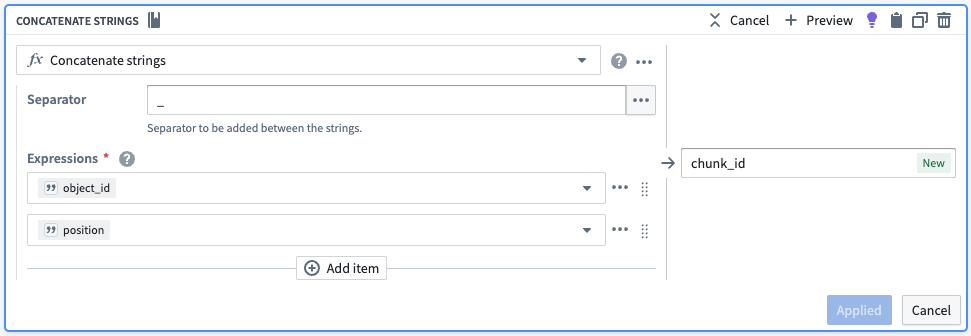

| object_id | chunk | chunk_id |
|---|---|---|
| abc | gold | abc_0 |
| abc | ring | abc_1 |
| abc | lost | abc_2 |
| xyz | fast | xyz_0 |
| xyz | cars | xyz_1 |
| xyz | zoom | xyz_2 |
Now, we have six rows representing six different chunks, each with the object_id (for linking), the new chunk_id to be a new primary key, and the chunk to be embedded as described in semantic search workflow. This results in the table as follows:
| object_id | chunk | chunk_id | embedding |
|---|---|---|---|
| abc | gold | abc_0 | [-0.7,...,0.4] |
| abc | ring | abc_1 | [0.6,...,-0.2] |
| abc | lost | abc_2 | [-0.8,...,0.9] |
| xyz | fast | xyz_0 | [0.3,...,-0.5] |
| xyz | cars | xyz_1 | [-0.1,...,0.8] |
| xyz | zoom | xyz_2 | [0.2,...,-0.3] |