- Capabilities
- Getting started
- Architecture center
- Platform updates
Use a Python function in Pipeline Builder
Prerequisites
This guide assumes you have already authored and published a Python function. Review our getting started with Python functions documentation for a tutorial.
Architecture
Python functions run in a Pipeline Builder pipeline as a sidecar container. This means that the function does not need to be deployed and scales dynamically with the size of your pipeline. Embedded functions can be previewed similarly to other transforms in Pipeline Builder.
Use your function in a Pipeline Builder pipeline
Follow the steps below to prepare and configure a Python function in your pipeline:
- Open the Pipeline Builder pipeline in which you want to use your Python function.
- Import your UDF into Pipeline Builder using one of two methods:
- From the graph view:
- Select Reusables from the upper part of the pipeline graph, then choose User-defined functions.
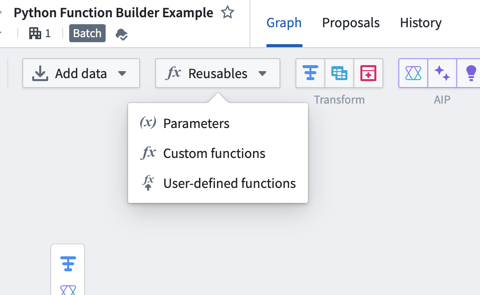
2. Select Import UDF and search through the available functions to find the one you want to use 3. Choose Add next to the function name. The function should then display an Imported tag.
4. Close the import dialogue and select Transform on your Pipeline Builder graph where you would like to use the function. 5. From the list of transforms, find the UDFs tab to the left to view your imported functions.
- Select Reusables from the upper part of the pipeline graph, then choose User-defined functions.
- Use the transform picker:
- Select Transform on the pipeline builder graph.
- Enter the name of the UDF you want to import.
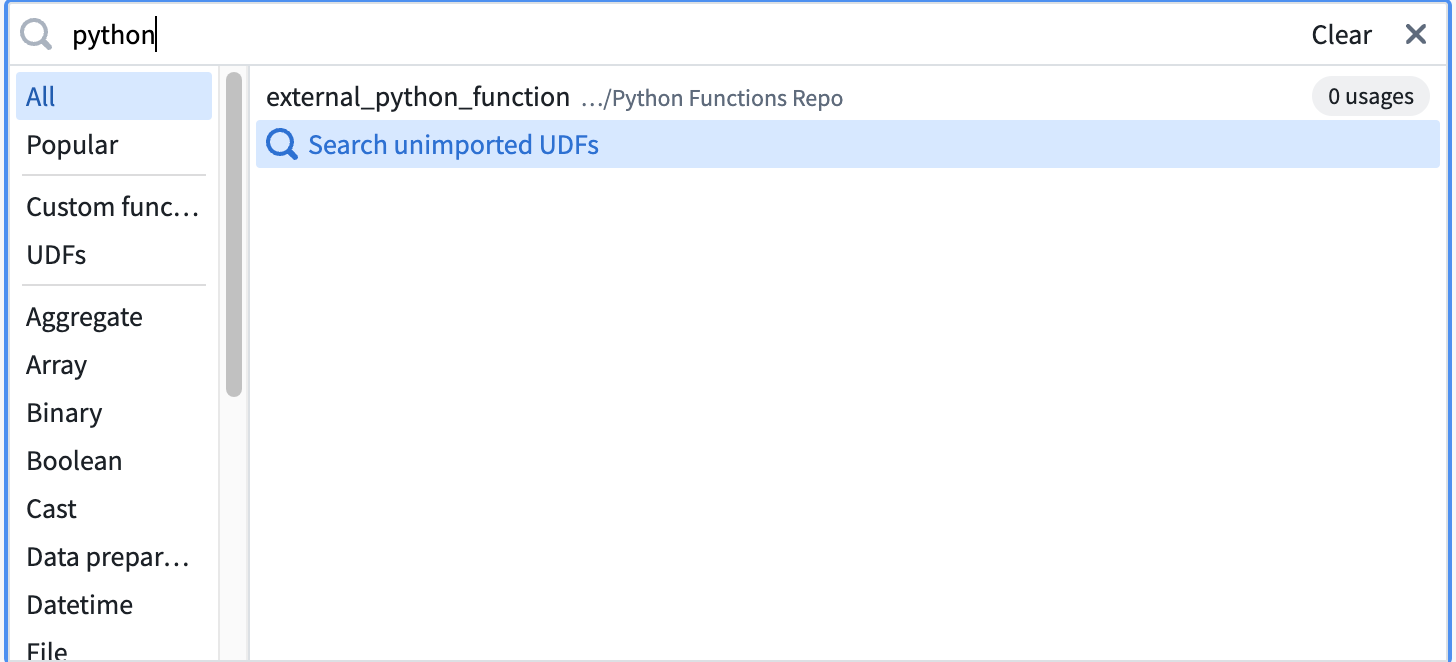
3. Select Search unimported UDFs. 4. Hover over the desired UDF and select Import.
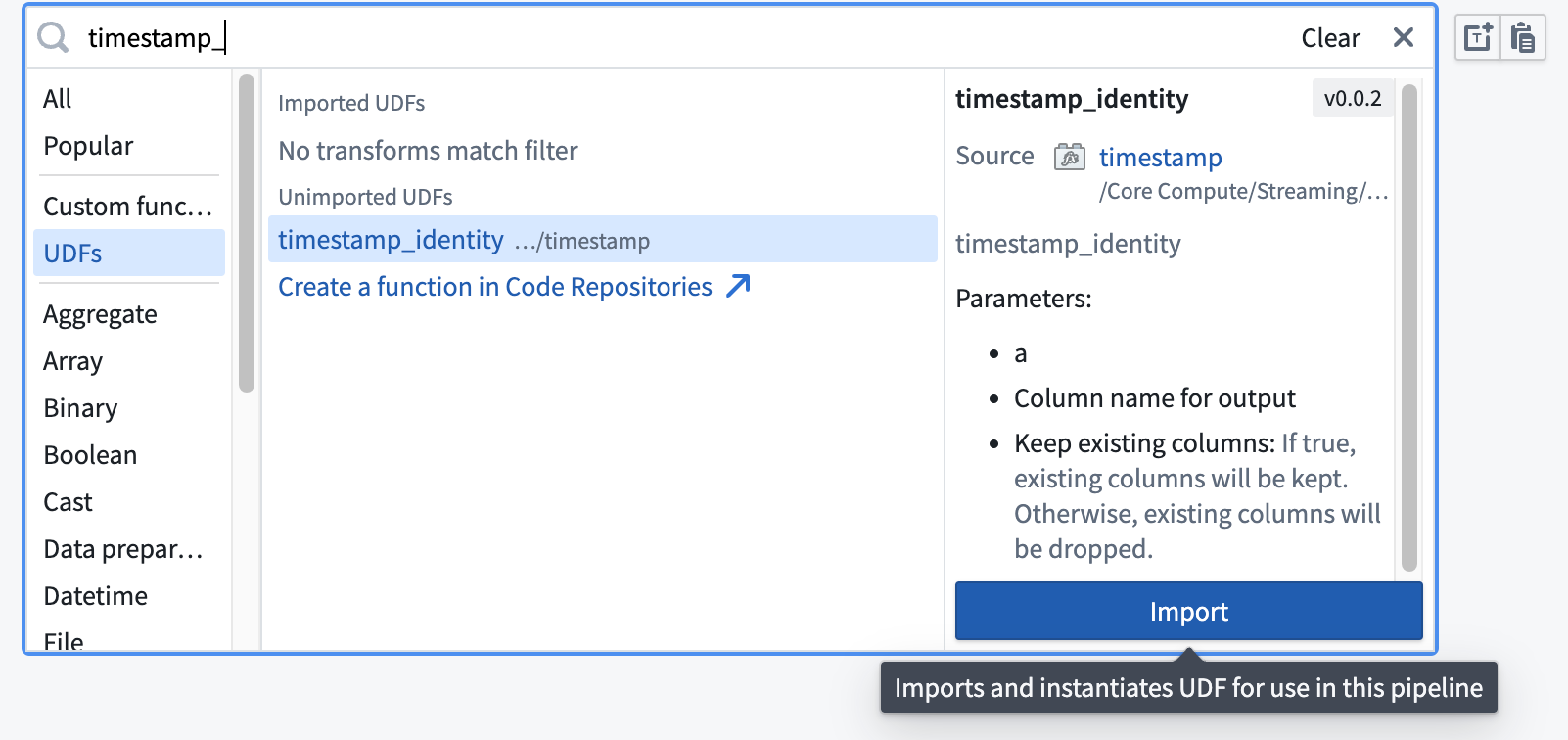
- From the graph view:
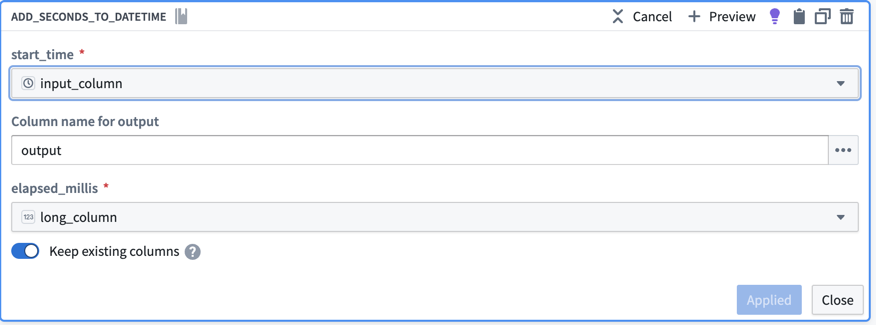
- Fill out the transform definition specifying the input columns and parameters, then select Apply.
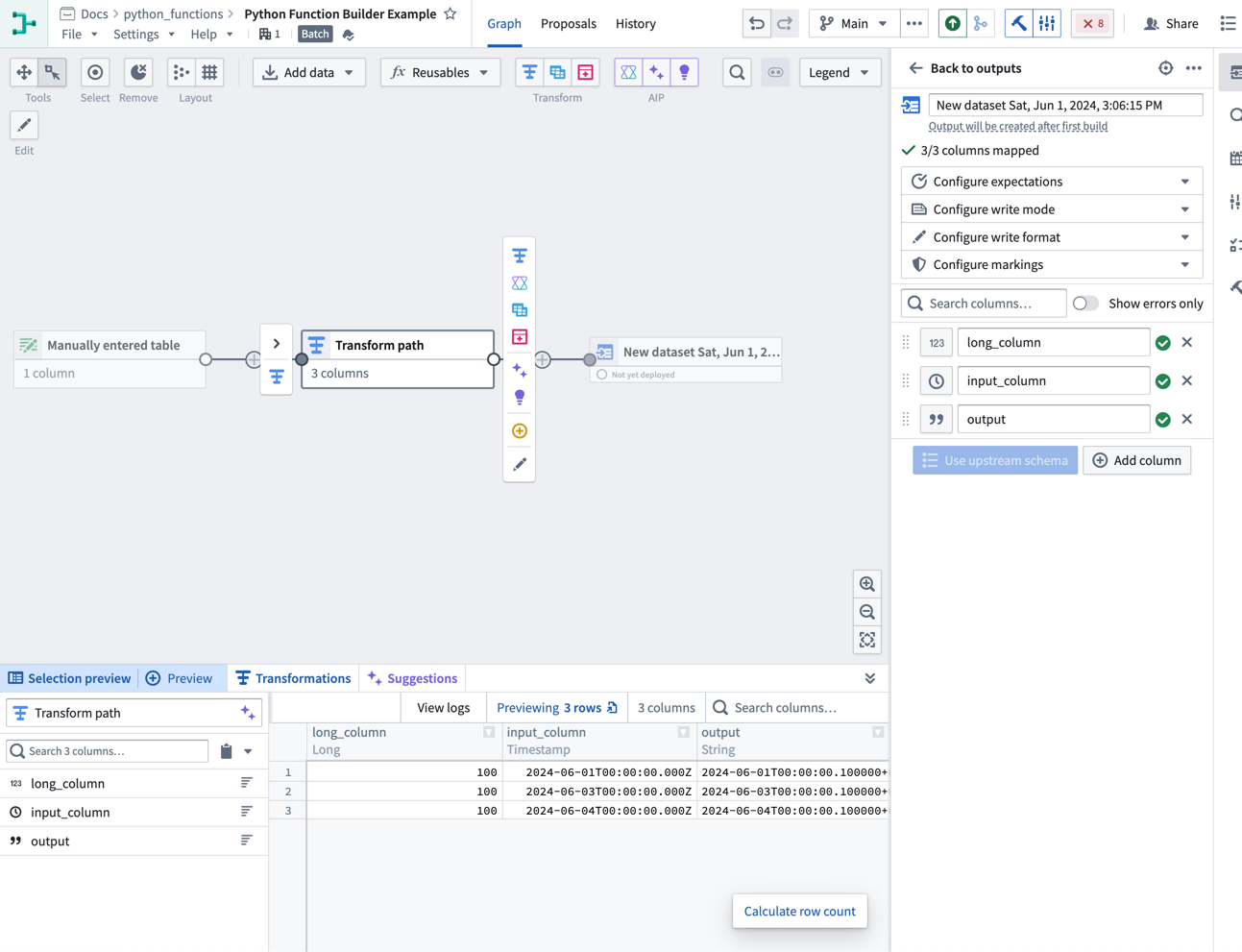
You should now see your Python function on your Pipeline Builder graph and can preview the output of the function.
External API calls in Pipeline Builder
To make API calls to an external system from Pipeline Builder, you can publish a Python function with access to external systems. This will allow you to write logic that communicates with external systems and use it as part of your pipeline.
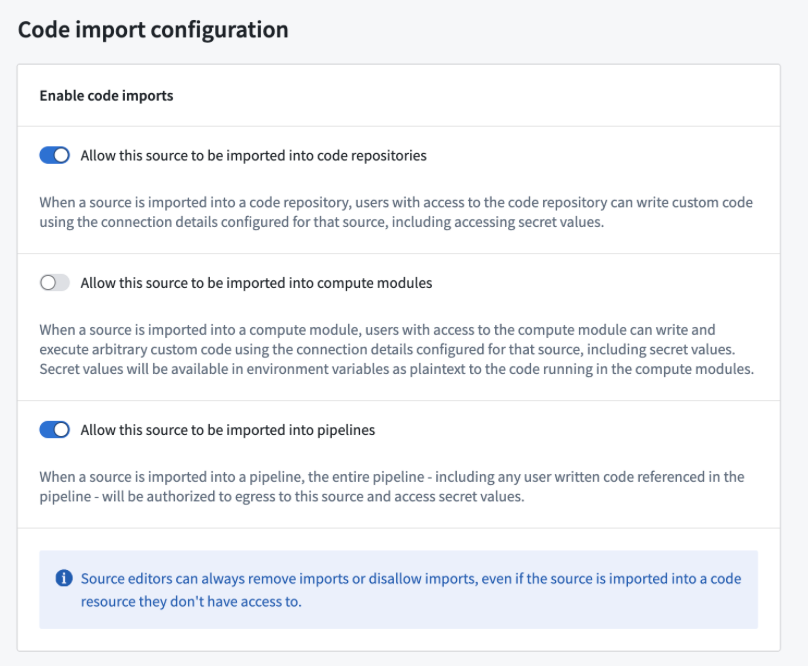
To be used as a user-defined function (UDF) in Pipeline Builder, all sources used in your function must be configured to be importable into pipelines. To configure this setting, navigate to the source in Data Connection, then to the Connection settings > Code import configuration tab:
Once you have enabled this option on your source and published your Python function, it can be used in your pipeline in the same way as any other Python function.