注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Phonographにデータを書き戻す
Phonograph 書き戻しは、SlateからFoundryオントロジーへの変更を行うために推奨されません。代わりに、オントロジーへの更新や変更を適用するために、Action Widgetと共にActionsを使用することを推奨します。詳細は Action types documentation を参照してください。
このガイドは、オントロジーにカスタムまたは複雑な変更を行うためにActionsを設定できないユーザー向けのものです。Phonograph 書き戻しを進める前に、Palantirの代表者に連絡して、特定のユースケースに対してActionsが適切に使用できるかどうかを確認してください。
Slateでユーザーの入力/データの変更をキャプチャし、それらをFoundryに保存するためには、以下の3つのコンポーネントが必要です:
- ソースデータセット: 編集可能にしたいFoundryに存在するデータセットです。このデータセットにはプライマリキーが必要です。
- Phonograph同期: Phonographは、Slateがソースデータセットへのユーザー入力の変更をキャプチャするための手動編集キャッシュです。データセットをPhonograph(Postgresではない)に同期すると、データセットがSlateで利用可能になり、ユーザーの編集が可能になります。
- 書き戻しデータセット: これは、ソースデータセットのユーザーが変更したバージョンを保存するために作成するFoundryのデータセットです。ソースデータセットは常に未変更のままであり、Phonographキャッシュに保存されたすべてのユーザーの編集は、Foundryの書き戻しデータセットに保存されます。
ソースデータセットを追加する
まず、Dataset タブでソースデータセットをユーザーのSlateアプリケーションに追加します。+ Add ボタンを使用して、単純な派生データセットである asteroid_notes を追加します。この概念的なデータセットには、小惑星の名前と、小惑星に関するユーザーが入力した情報を保持するための空白の列 research_notes が含まれています。
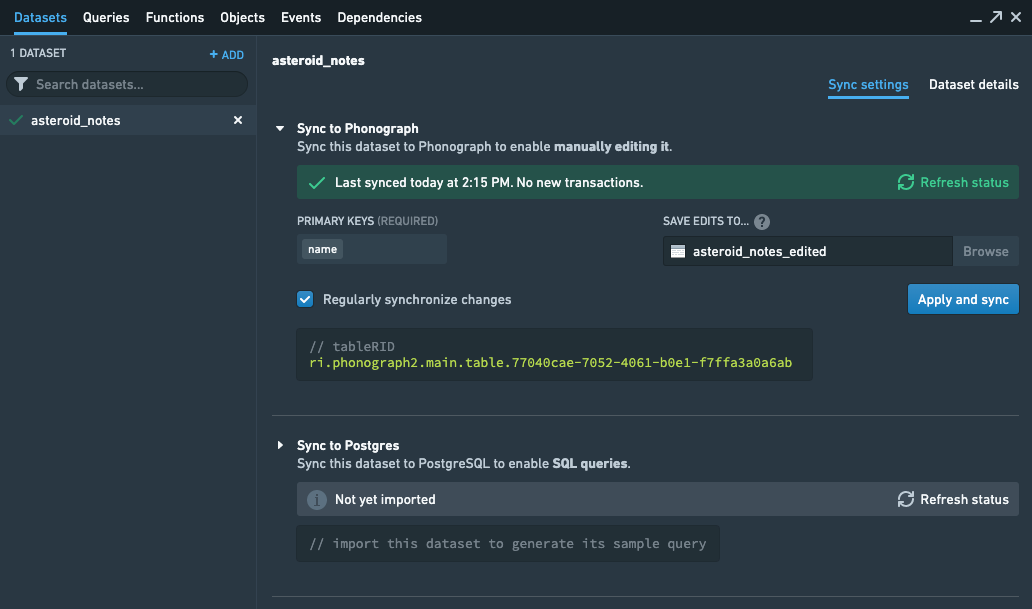
データセットを追加した後、データセットの同期設定を表示します。手動編集キャッシュであるPhonographへの同期を設定します。
プライマリキー を選択します。プライマリキーの選択は、単一の行を一意に識別する必要があります。一般的には、適切なプライマリキーを生成するために、トランスフォームで複数の列を組み合わせる必要があります。一連の列を定義して共同のプライマリキーとすることも可能ですが、これによりデータの編集が複雑になります。
プライマリキーが設定されたら、Foundryでユーザーの編集を保存する書き戻しデータセットを作成します。"Browse" を選択して、編集内容を保存できるFoundryのデータセットを作成します。ポップアップウィンドウで、データセットの名前と、データセットを作成したいFoundryの場所を指定します。
終了したら、同期設定は次のようになるはずです:
書き戻しインデックスは struct 列タイプをサポートしていません。これは、DateTime 列タイプを持つデータセットはインデックス作成に失敗することを意味します。ContourまたはSQLまたはPythonトランスフォームを使用して、DateTime 列をインデックス作成前に Timestamp にキャストできます。
現在、UIを通じて同期を登録解除(削除)することはできません。ただし、Slateでの使用には、"Table Registry - Unregister"エンドポイントにクエリを追加することができます。唯一のパラメーターはTable RIDで、結果はTableの削除となります - これは入力データセットまたは出力データセットには影響しません。関連するデータセットの同期UIで、登録された書き戻し同期がないことがわかります。これにより、Tableからのすべてのデータが永久に削除されるので、注意深く使用し、クエリを削除するか、手動で実行するように設定してください。
クエリ例
データがPhonographにインデックスされたので、読み書きができるようになりました。最も簡単なパターンは次のようになります:
- クエリを使用してすべての行または行のサブセットを取得し、ユーザーに表示します。
- ユーザーはアプリケーションウィジェットと対話して行を追加、削除、または行の値を変更します。
- 各変更はユーザーの提出(例:ユーザーが提出ボタンをクリックする)に基づいて独立して書き戻されます。
- 変更を表示するために再度すべての行を取得します...
後で、bulkエンドポイントを使った複雑さの追加と、フロントエンドの表示状態とバックエンドのデータ状態を分離して、より反応性の高いアプリケーションを維持するためのオプションを探究しますが、これらは両方とも高度なトピックです。
行の選択
テーブルからすべての行を取得するためには、新しいSlateクエリを作成する必要があります。
- Slateアプリケーションで新しいクエリを作成します。
- このクエリのソースとして "Phonograph2" を選択します。
- "Available Services" フィールドで、
Table Search Serviceを選択します。 - 下記のコードを使用して、このクエリの
Search Requestフィールドを記入します。このリクエストはmatchAllブロックを使用しており、すべての行が返されます。テーブルのRID(同期設定で利用可能)とソートする列(オプション)を記入する必要があります。
q_getAllRows 例
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14{ "tableRids": [ "<your_table_rid>" // あなたのテーブルのRID ], "filter": { "type": "matchAll", // フィルタタイプ:すべての要素に一致 "matchAll": {} // すべてに一致する条件 }, "sort": { "<your_column_to_sort_by>": { // 並べ替える列の名前 "order": "desc" // 並べ替えの順序:降順 } } }
このクエリパターンでは、ページング(ブラウザのメモリ負荷を軽減し、パフォーマンスを向上させるため)およびソート(sort ブロックを追加することで)が可能です。サーバーサイドページング 機能の使用については、Table Widgetを参照してください。
pagingToken
"{{w_tableWidget.gridOptions.pagingOptions.currentOffset}}"
上記のコードは、現在のページオフセット値を取得します。この値は、ページングオプションに含まれています。
ページングオフセットとは、データの一部だけを表示するときに、そのスタートポイントを示す値です。たとえば、1000件のデータがあるときに、1ページに10件ずつ表示する場合、2ページ目は11番目から20番目のデータを表示します。このときのページングオフセットは11となります。
pageSize
"{{w_phonographResults.gridOptions.pagingOptions.pageSize}}" // ページングオプションのページサイズ
以前は行を取得するために推奨されていたGet All Rowsエンドポイントは廃止されました。上記のようにSearchエンドポイントに移行し、f_getAllRowsFormat関数を以下のように更新してください:
var rawData= {{getAllRows.result.[0].results.rows}}
が
var rawData= _.map({{getAllRows.result.[0].hits}}, h => h.row)
q_getRowsの例
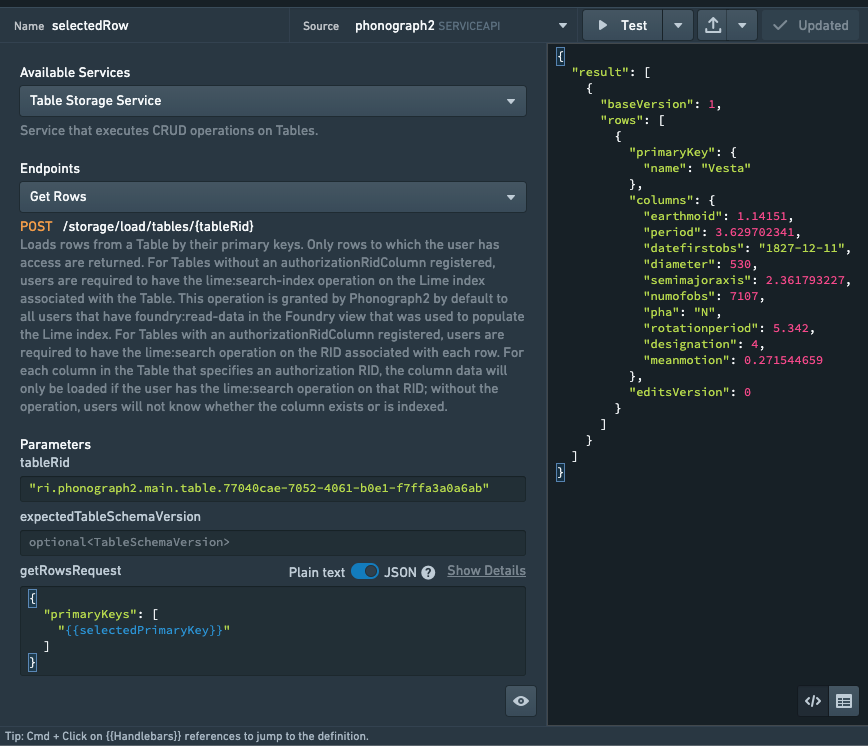
すべての行を一度に取得するだけでなく、Get Rowsエンドポイントを使用して主キーオブジェクトのリストを提供し、IDによる複数の行を取得することもできます。これは、ユーザーが新しい値を入力しているときに行がすでに存在するかどうかを確認する簡単な方法であり、変更をeditイベントかaddイベントか(以下で詳述)適用するかを判断するために必要です。
ウィジェットにクエリ結果を表示する
これらのgetエンドポイントの結果はオブジェクトの配列で、各オブジェクトは行を表し、ネストされたprimaryKeyオブジェクトとcolumnsオブジェクトの値はその行の列:値のペアを表します。Slateのウィジェット(チャートやテーブルなど)は、各配列が列を表し、配列のインデックスが特定の行の値を表す並行配列でデータを期待しています。このヘルパー関数はGetまたはSearchからの結果を入力として受け取り、テーブルや他のウィジェットにフィードするための並行配列を返します:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35// 元のデータを取得し、それぞれの行をマッピングします var rawData= _.map({{getAllRows.result.[0].hits}}, h => h.row) // 主キーを取得します var primaryKeys=Object.keys(rawData[0].primaryKey); // 列を取得します var columns=Object.keys(rawData[0].columns); // 解析したデータを格納するためのオブジェクトを作成します var parsedData={} // 初期化 // 主キーごとに空の配列を作成します for (var pkey of primaryKeys) { parsedData[pkey]=[] } // 列ごとに空の配列を作成します for (var column of columns) { parsedData[column]=[] } // 元のデータの各行に対して for (var row of rawData) { // 各主キーに対して for (var pkey of primaryKeys) { // 主キーの値を解析したデータに追加します parsedData[pkey].push(row.primaryKey[pkey]) } // 各列に対して for (var column of columns) { // 列の値を解析したデータに追加します parsedData[column].push(row.columns[column]) } } // 解析したデータを返します return parsedData;
null値を考慮する
データ内のnull値は、Phonographにインデックスされません。その結果、null値を含む列がある行はPhonographに存在しないことになります。Phonographの結果を行と列に変換する際には、これらの欠損値を考慮する必要があります。以下は、すべての行のすべての列を検出する例です。この例は、最初の行でnull値に関する問題を回避するために、上記の例と組み合わせることができます。
検索サービス vs ストレージサービスの更新読み取り
検索サービスのエンドポイントは、関連するPhonographテーブルの検索インデックスを使用します。この検索インデックスは、ストレージサービスのPost Eventエンドポイントと同期的に更新されないため、変更が書き込まれてからその変更がSearchエンドポイントへのクエリに反映されるまでにわずかな遅延があります。簡単なパターンとしては、Toastウィジェットを使用してタイマーを作成する方法があります:
q_postEvent.success->w_successToast.openw_successToastのタイムアウトは5000(5秒)に設定w_successToast.close->q_getAllRows
変更された行を取得していることを確認するために、トーストの期間を調整する必要があるかもしれません。また、getAllRowsクエリにsortブロックを追加してください。デフォルトのソートは行ドキュメントの最終更新タイムスタンプによるもので、これにより編集された行はすべての結果の後ろに「移動」します。
あるいは、データの表示とPhonographへのデータの保存を分離するアプリケーションのパターンを定義します。これは、現在のビューを追跡するためのステート変数を使用し、ユーザーによってトリガーされたときにそのデータを定期的に保存することで行うことができます。ただし、すべての行を取得するためのクエリを自動的に再実行することはありません。このパターンはユーザー体験を向上させます(更新が即時に表示されます)が、より複雑な設計が必要です。
Table Storage Serviceへの任意のリクエスト、つまり、primaryKey値のリストによる行の取得を含むものは、すべての編集を含むことが保証されています。したがって、q_postEvent.success -> q_getRowByPrimaryKey.runのようなイベントを連鎖させることは安全です。
この場合、primaryKey検索で取得される特定の行に書き込まれた任意の変更は、結果に含まれることが保証されます。
データの編集
Table Storage ServiceのPost Eventエンドポイントは、3種類のイベントを処理します:rowAdded、rowDeleted、およびrowModified。
これら3つのイベントすべてのクエリでは、primaryKeyオブジェクトとpayloadオブジェクトを持つtableEditedEventPostRequestが必要です。以下に示すように:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15{ "primaryKey": { "<primary_key_col>": "<primary_key_value>", // プライマリーキーの列と値 "<second_primary_key_col>": "<second_value>" // 手動編集インデックスを作成するときに複数の列を指定した場合のみ }, "payload": { "type": "rowModified", // "rowAdded" または "rowDeleted" "rowModified": { // "rowAdded" または "rowDeleted" "columns": { "<col_a>": "<new_value>", // a列の新しい値 "<col_b>": "<new_value2>" // b列の新しい値 } } } }
rowDeleted イベントは空の rowDeleted オブジェクトを持っています - 行を削除するために列を渡す必要はありません。
一般的なベストプラクティスとして、tableEditedEventPostRequest の構築には関数を使用します。これらは、求められるワークフローと実装により、多くの異なる形をとることができます。
関数 f_createTableEditEvent の例:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27// 選択された行を取得します var selectedRow={{q_getAllRows.result.rows.[w_rowsTable.selectedRowsKeys.[0]]}}; // 更新する列を設定します var updatedCols=selectedRow.columns; // リサーチノートを更新します updatedCols.research_notes={{w_notesInput.text}} // テーブル編集イベントのポストリクエストを作成します var tableEditedEventPostRequest = { // 主キーを設定します "primaryKey":{ "name": selectedRow.primaryKey.name, }, // ペイロードを設定します "payload": { // 行が変更されたタイプを設定します "type": "rowModified", // 変更された行を設定します "rowModified": { // 更新された列を設定します "columns": updatedCols, } } } // テーブル編集イベントのポストリクエストを返します return tableEditedEventPostRequest;
上記のシンプルな関数の例では、q_getAllRowsから取得したすべての行がw_rowsTableウィジェットに表示されます。選択キーとして表に行番号を表す列が追加され、w_rowsTableで行を選択することにより、その選択キーを使用してq_getAllRowsの生の結果から行を見つけることができます。行が選択された状態で、w_notesInputウィジェットにユーザーが入力した値をresearch_notes列の値に更新することができます。これは次の行で行われます:updatedCols.research_notes={{w_notesInput.text}})
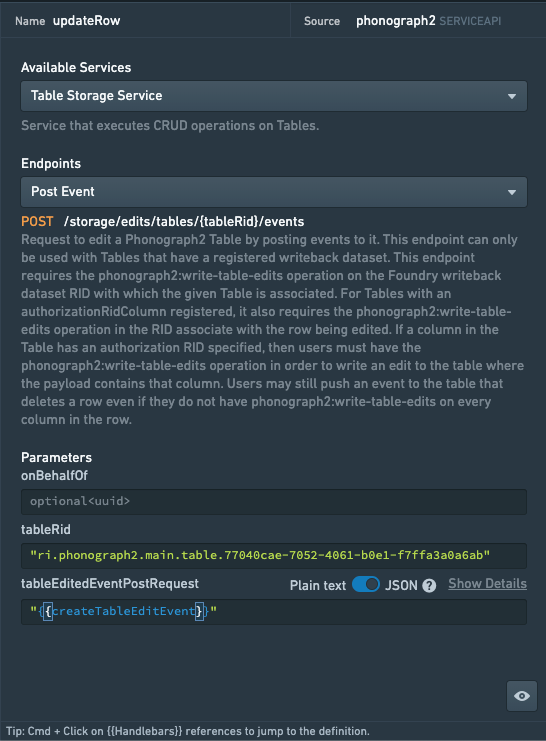
関数f_createTableEditEventの最終ステップは、updatedColsオブジェクトをtableEditedEventPostRequest変数に挿入し、それを関数の結果として返すことです。どれだけ複雑な作業が必要であっても、これが関数の出力となり、クエリに直接フィードすることができます。
関数が完成したら、関数の出力であるtableEditedEventPostRequestオブジェクトをupdateRowクエリの適切なパラメーター欄に挿入できます(下の画像を参照)。
クエリを手動実行に設定する
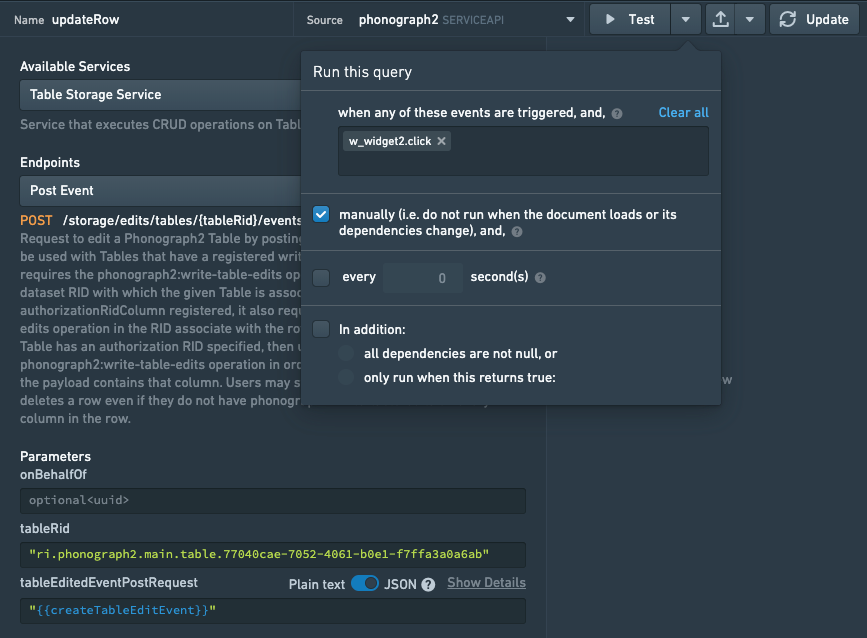
クエリに適切なパラメーターが設定されたので、テーブルに編集が加えられるべき時のみクエリが実行されるように、クエリを実行する条件を定義します。
クエリエディタでクエリを表示している間に、実行の隣にあるドロップダウンメニューを使用して手動実行にチェックを入れます。これにより、ページの再読み込み時や依存関係が変更された時にクエリが実行されるのを防ぎます。
次に、クエリがユーザーのアクションによって実行されるようにトリガーを設定します。これを行う最も簡単な方法は、ボタンウィジェットを追加し、button.clickeventでクエリをトリガーすることです。ただし、他にも多くの可能な解決策があります。ボタンウィジェットをSlateアプリケーションに追加し、クリックでクエリを実行するように設定します。このクエリを実行すると、Phonographのキャッシュのみが更新されることに注意してください(編集はFoundryの書き戻しデータセットにはすぐには反映されません)。
また、フォームの入力を検証し、フィードバックテキストをフォームと並べて表示する別の関数を作成することが、よくあるベストプラクティスです。これにより、ユーザーからの入力データに起因するデータ品質の問題を防ぐことができます。これを行う関数は次のようになります:
f_validateForm
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19var form { disableSubmit: false, // Submitを無効にするかどうか globalMessage: "", // 全体のメッセージ fields : { i_widget1: { value: {{i_widget1.text}}, // i_widget1の値 message: "" // i_widget1のメッセージ }, i_widget2: { value: {{i_widget2.text}}, // i_widget2の値 message: "" // i_widget2のメッセージ } // 他のフィールド... } // 値の検証、各ウィジェットのメッセージ生成、および全体の有効状態の決定のロジック // 値が無効と判断された場合、disableSubmitをtrueに切り替えます return form;
その後、ウィジェットの disable プロパティを "{{f_validateForm.disableSubmit}}" にリンクすることで、ボタンウィジェットを無効にすることができます。
新しい行を追加する
新しい行を追加する方法は、行の編集と同様です。上記の例で rowModified を rowAdded に置き換えるだけです。
ただし、既存の行と同じプライマリキーで新しい行を追加しようとすると失敗します。簡単なオプションは、行がすでに存在することをユーザーに簡単に警告するために、toast widget をトリガーすることです。
少しユーザーフレンドリーなオプションは、ユーザーが入力したプライマリキーを使用して Get Rows エンドポイントに対して q_validatePrimaryKey クエリを行い、行がすでに存在するかどうかを確認することです。もし存在する場合は、f_createTableEditEvent で rowModified イベントを生成します。存在しない場合は、rowAdded を使用します。
行を削除する
行を削除するには、削除する行のプライマリキーとともに rowDeleted イベントを送信するために Post Event エンドポイントを使用するだけです。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14{ // "primaryKey"は主キーの情報を持つオブジェクトです。 "primaryKey": { // "<primary_key_col>"は主キーのカラム名を表し、"<primary_key_value>"はその主キーの値を表します。 "<primary_key_col>": "<primary_key_value>" }, // "payload"はペイロード情報を持つオブジェクトです。 "payload": { // "type"はペイロードのタイプを表します。この場合、「rowDeleted」は行が削除されたことを表します。 "type": "rowDeleted", // "rowDeleted"は削除された行の情報を持つオブジェクトです。この場合、空のオブジェクトが指定されているため、具体的な情報はありません。 "rowDeleted": {} } }
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16{ "tableRids": [ "{{f_getTableId}}" // "f_getTableId"関数を使ってテーブルのIDを取得します ], "filter": { "type": "terms", // フィルタのタイプは"terms"です "terms": { "field": "first_name", // フィールドは"first_name"を指定します "terms": [ "agnese", // 検索するテームズは"agnese"です "ailee", // 検索するテームズは"ailee"です "woodman" // 検索するテームズは"woodman"です ] } } }
queryString フィルター処理
queryString フィルター処理のタイプは、自然言語検索と同等の検索を提供しようとします。AND や OR 演算子を含めることができ、また複数の単語を引用符で囲むことで正確な一致を行うことができます。例:\"multi word exact match\"
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11{ "tableRids": [ "{{f_getTableId}}" // テーブルIDを取得する関数 ], "filter": { "type": "queryString", // クエリストリングタイプのフィルタ "queryString": { "queryString": "jang" // 検索クエリ: "jang" } } }
範囲フィルター
範囲フィルターは、数値型および日付型の列に対する比較的なフィルター処理を提供します。 gt、gte、lt、lteをサポートします。
searchRequest
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13{ "tableRids": [ "{{f_getTableId}}" // "f_getTableId"関数から取得したテーブルのIDを指定します。 ], "filter": { "type": "range", // フィルターのタイプは"範囲"です。 "range": { "field": "start_date", // "start_date"フィールドを基準に範囲フィルターを適用します。 "lt": "2018-01-01", // "start_date"がこの日付より前のレコードのみを抽出します。 "format": "yyyy-MM-dd" // 日付のフォーマット指定です。 } } }
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23{ "tableRids": {{f_getTableId}}, // f_getTableId関数で取得したテーブルIDを指定します。 "filter": { // フィルタリング条件を定義します。 "type": "and", // 複数の条件をすべて満たす必要があることを指定します。 "and": [ // 満たすべき条件のリストです。 { "type": "queryString", // 検索クエリ文字列によるフィルタリングを指定します。 "queryString": { "queryString": "pixoboo" // 検索クエリ文字列として "pixoboo" を指定します。 } }, { "type": "terms", // 特定のフィールドの値によるフィルタリングを指定します。 "terms": { "field": "first_name", // フィルタリング対象のフィールドとして "first_name" を指定します。 "terms": [ "harcourt" // "first_name" フィールドの値が "harcourt" であるもののみフィルタリングします。 ] } } ] } }
Foundry に書き戻しする
私たちが書いた updateRow クエリは、Phonograph に保存されている asteroid_notes のコピーのみを更新します。データを Foundry で表示するためには、Foundry 内のデータセットのプレビューページで "Build" をクリックする必要があります。
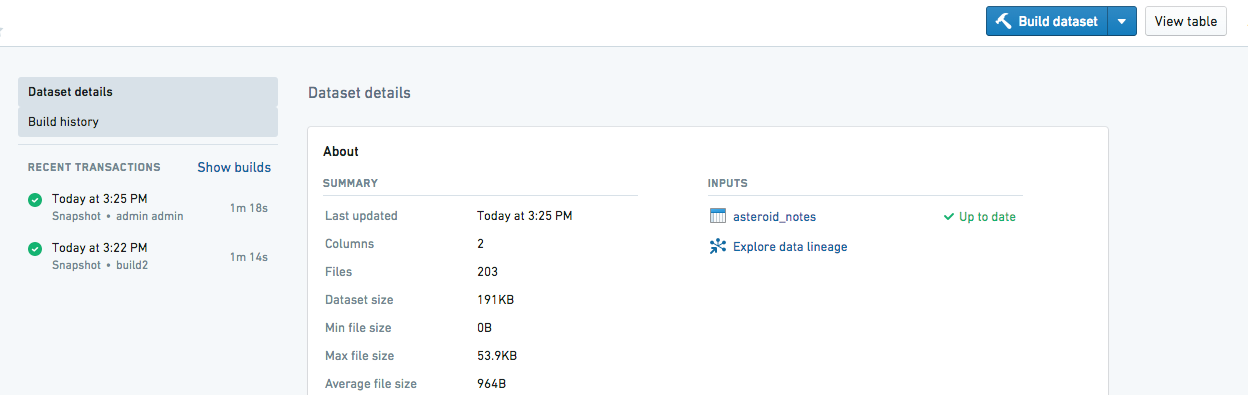
これが完了すると、私たちが行った research_notes の編集が asteroid_notes_edited に表示されます。
高度な設定
バルクエンドポイント
上述した Post Event エンドポイントに加えて、Table Service は Post Events for Table エンドポイントを提供しており、これは私たちが上で生成した tableEditedEventPostRequest の配列を期待します。イベントは種類を混在させることができます(rowModified、rowAdded、または rowDeleted)、ただし特定の primaryKey は配列内で 一度 しか表示できません。つまり、たとえば、単一のリクエスト内で同じ primaryKey に対する rowModified イベントと rowDeleted イベントを持つことはできません。
Post Events for Table リクエスト
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24[ // イベントリクエスト 1 { "primaryKey": { "primary_key_col": "primary_key_value", // 主キーカラム }, "payload": { "type": "rowModified", // "rowAdded" または "rowDeleted" "rowModified": { // 行が変更された場合の詳細情報、"rowAdded" または "rowDeleted" "columns": { "col_a": "value", // カラム A の値 } } } }, { "primaryKey": { "primary_key_col": "different_primary_key_value", // 別の主キーカラムの値 }, "payload": { "type": "rowDeleted", // "rowAdded" または "rowDeleted" "rowDeleted": {} // 行が削除された場合の詳細情報、ここでは空 } }, etc...
以下では、バルクエンドポイントとEventsフレームワークを使用して、変更を行う際の遅延に対処するための強力なソリューションを構築する方法について説明します。
遅延の管理
手動編集キャッシュの基本的なアーキテクチャにより、Post Eventの成功した呼び出し直後に編集が必ずしも主要インデックスに存在するわけではありません。現在、Get All RowsとGet Rowsの呼び出しを同期的に行う作業が進行中で、q_getAllRowsをq_postEditEventクエリの成功にトリガーするように設定すると、編集内容が必ず表示されるようになります。ただし、searchエンドポイントに依存している場合、検索インデックスが更新されるまでの数秒の遅延を考慮する必要があります。
最も簡単な方法は、編集クエリとすべての行を取得するクエリの間にtoastを挿入することです。q_postEditEvent.successイベントでトーストをトリガーし、その持続時間を3-4秒(msでの値は3000-4000)に設定します。その後、w_editSuccessToast.closedイベントでq_getAllRowsクエリをトリガーすると、インデックスが更新されるまでの時間を確保できます。
より複雑なワークフローでは、Slateアプリを表示するために使用される状態と編集インデックスの状態を分離する追加の作業を検討することがあります。これを行うためには、ページの読み込み時にSlate変数をq_getAllRowsクエリの結果で埋め、これがユーザーの"フロントエンドの状態"となります。すべての編集/削除/更新イベントは、バックエンドへのクエリを直接トリガーするのではなく、このフロントエンドの状態変数に変更を加えます。定期的にフロントエンドの変数の状態とクエリからのデータとを比較し、すべての変更を適用するためのバルククエリのペイロードを作成することができます。
また、トーストや「未保存の変更」カウンターなどの形でユーザーにフィードバックを提供したり、すべての変更を保存するための手動ボタンをクリックするようにしたいと思うかもしれません。この設定は、複雑で長期的なアプリケーション以外では重すぎるものです。ほとんどの場合、トーストのアプローチが十分であり、Get RowsとGet All Rowsエンドポイントの改善により、ほぼすべての場合においてこれが不要になるはずです。したがって、このオプションを検討している場合は、Palantirチームとさらに議論するのが最善の方法でしょう。
集計
searchエンドポイントは、インデックスされたデータ全体で統計を生成し、値をバケット化するための集計もサポートしています。
ElasticSearch 2.0 Aggregation ↗の構文の一部がサポートされています:value_count、max、geohash_grid、terms、top_hits、sum、cardinality、avg、nested、フィルター処理する、histogram、min。
Elasticsearchの制限により、一部の集計の結果は近似値になることに注意してください。任意の種類の集計を使用する前に、Elasticsearchのドキュメンテーションを参照し、それが正確な値か近似値かを理解してください。もしそれが近似値であるならば、それがユーザーのユースケースに対して許容可能かどうかを決定してから進めてください。
以下は、構文の簡単な例です。visitsフィールドの生バージョンを使用し、文字列フィールドで集計しているため、「Exact Match」を有効にする必要があることに注意してください。
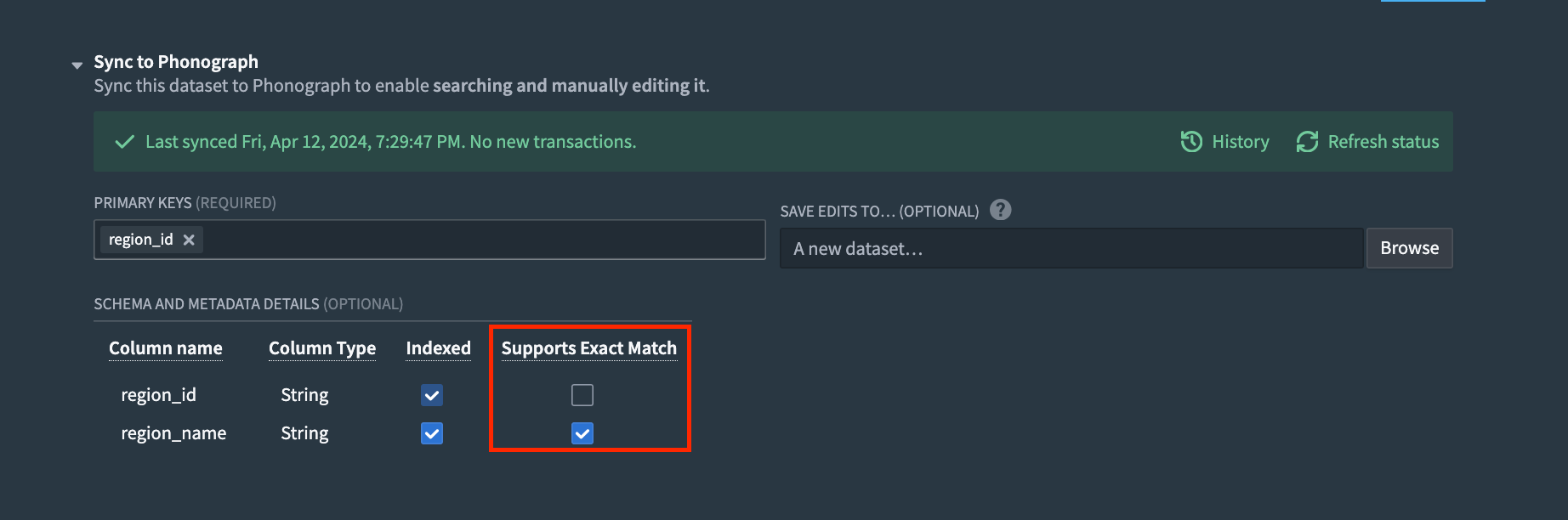
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16{ "tableRids": [ "{{f_getTableId}}" // テーブルIDを取得する関数 ], "filter": { "type": "matchAll", // すべての条件に一致するフィルタを使用 "matchAll": {} // 空のオブジェクトはすべてのレコードに一致することを示します }, "aggregations": { "visits": { "terms": { "field": "visits.raw" // 訪問数データを使用して集約を行う } } } }
上記のクエリは、クエリの filter セクションからすべての行を visits フィールドの値でバケットに分け、カウントを返します。集計値のみに興味がある場合は、 pageSize を 0 に設定して結果から個々のレコードヒットを削除し、ユーザーのアプリケーションのロード時間とメモリプレッシャーを軽減します。
返される形式は以下のようになります:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21"aggregations": { // 集約処理 "genders": { // 性別による集約 "doc_count_error_upper_bound": 0, // ドキュメント数のエラー上限 "sum_other_doc_count": 30, // その他のドキュメント数の合計 "buckets": [ // バケツ配列 { "key": "daily", // キーは"毎日" "doc_count": 148 // ドキュメント数は148 }, { "key": "often", // キーは"度々" "doc_count": 141 // ドキュメント数は141 }, { "key": "weekly", // キーは"週に一度" "doc_count": 129 // ドキュメント数は129 }, ... ] } }
各集約タイプは少し異なる返却構文を持つかもしれませんが、チャートやテーブルのようなSlateウィジェットでこのタイプのデータを扱う際には、Rows to Columns関数が役立つでしょう。