注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
データシステムへの読み書き
クエリエディタを使用すると、ユーザーのデータソースをクエリできます。データソースの種類によっては、クエリエディタで異なるクエリを書くことができます。以下に、各タイプのクエリでHandlebarsを使用する際のセキュリティ考慮点、クエリパーシャルと条件付きクエリの紹介について述べます。
クエリのセキュリティ概要
Foundry のクエリは Foundry Synchronizer を使用し、すべての同期されたテーブルに対して読み取り専用の権限を強制します。また、個々のテーブルへのアクセスは、Foundry のデータセットレベルで付与されたアクセスを尊重します。
Foundry 以外のデータソースについては、クエリ内で Handlebars を使用すると、悪意のあるユーザーがテンプレートの内容を有害なコードに置き換えてインジェクション攻撃を行う可能性があります。したがって、これらのクエリは Handlebars の使用に対して追加のセキュリティルールが必要となります - ルールについては、以下の SQL クエリ および HTTP JSON クエリ のセクションで詳述しています。
また、ユーザー変数 (例:{{user.firstName}}) を参照する任意のテンプレートは、ログイン時にブラウザに渡された値を受け入れるのではなく、サーバからその値を取得します。
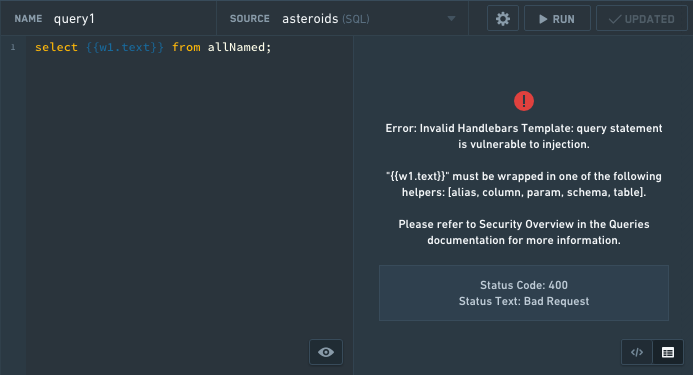
SQL のセキュリティエラーの例:
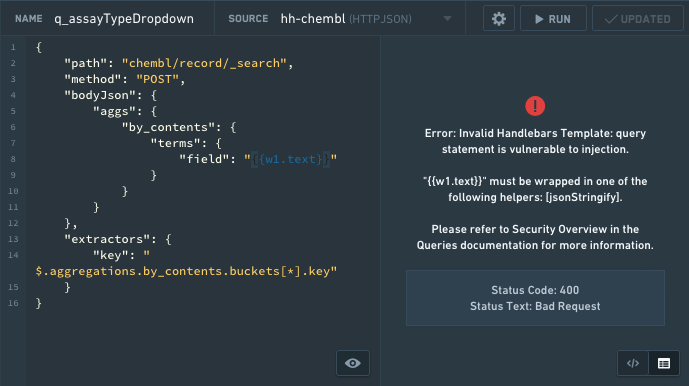
HTTP JSON のセキュリティエラーの例:
Foundry クエリ
Foundry Synchronizer
Foundry Synchronizer を使用するのが、Slate から Foundry のデータをクエリするための推奨方法です。この設定では、Foundry 内で Postgres インスタンスを提供し、Foundry Synchronizer を使用して SQL テーブルとして利用可能になった Foundry データセットから通常の SQL クエリを書くことでデータを取得できます。
SQL セキュリティヘルパーを使用する必要はありません。
Foundry Synchronizer は、Foundry Synchronizer のドキュメンテーション内の Synchronization UI セクションで言及されているように、Metadata View から、または Slate から直接制御できます。これは、データセットを追加し、Slate 内の Datasets タブから Foundry Synchronizer と対話することで行います。Datasets タブは、Foundry のデータソースが Slate に追加されると自動的に有効になります。UI を操作するには、Datasets パネルで Slate にデータセットを追加し、Sync to Postgres セクションを確認してください。
適用して同期 ボタンをクリックします。
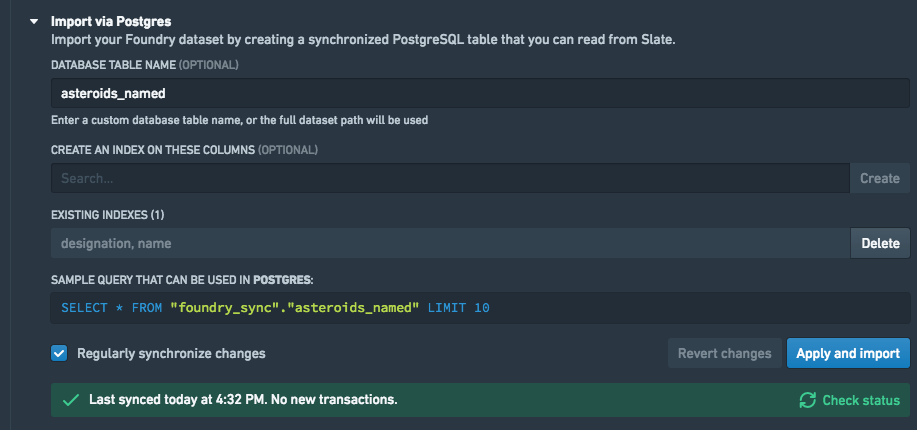
同期が完了すると、Datasets タブ内の Postgres パネルに、Slate のクエリタブに貼り付けるための SQL クエリの例が表示されます。リミットは、意図せずに多くのデータをクエリすることを防ぐために含まれています。これは Slate の実際のクエリで削除することができます。インデックスの作成やテーブル名のカスタマイズなどの操作について UI を通じて Foundry Synchronizer と対話する方法の詳細は、Synchronization UI のドキュメンテーションを参照してください。
Phonograph クエリ
オブジェクトタイプをバックアップする phonograph テーブルをクエリする場合、オブジェクトセットを使用してオブジェクトをフィルター処理し、集約、ソートを行うことを検討してください。
Phonographは、Foundry データを Phonograph サービスに同期し、Foundry データセットへのクエリや変更の書き込みを行うための ElasticSearch を利用した API と対話するデータソースタイプです。
Slate からこのサービスを使用する詳細な手順については、Slate から Foundry へのデータの書き戻しを参照してください。
SQL クエリ
セキュリティの考慮点
SQL クエリ内のすべての Handlebars テンプレート(Foundry データソースを使用するものを除く)は、SQL セキュリティヘルパーまたは Handlebars Built-In Helpers ↗ で囲む必要があります。各 SQL セキュリティヘルパーをいつどのように使用するかの詳細は、SQL Helpersを参照してください。
ヘルパーは schema、table、行、alias、param の 5つがあります。
schema,table:schemaとtableヘルパーは非常に似た動作をします。名前と許可された名前のリストが与えられると、ヘルパーは名前が許可された名前のリストと対応する情報スキーマテーブルに存在することを確認します。例えば、table ヘルパーは、テーブル名が許可された名前のリストとinformation_schema.tablesまたはあなたのデータベースの対応するスキーマテーブルに存在するかどうかを確認します。許可された名前のリストを指定することで、クエリがアクセスすべきでないスキーマ/テーブルにアクセスすることを防ぎます。許可された名前をテンプレート化することはできません、なぜならそれは検証の目的を無効にするからです。 SQL の組み込み関数 ↗を使用して、基本的な文字列や数学の操作などのデータ変換を行うことができます。
HTTP JSON クエリ
セキュリティの考慮事項
すべての HTTP JSON クエリは、以下の要件を満たす必要があります:
- すべての Handlebars テンプレートは jsonStringify ヘルパーで包む必要があります。
jsonStringifyヘルパーは、テンプレートの値が現在のスコープを逸脱できないことを保証します。例えば、ブロックを閉じてリクエストに余分なプロパティを追加することはできません。
プロパティをテンプレート化するための使用例は次のとおりです: ..はパスに使用できません。これにより、クエリパスが親スコープを指すことなく、アクセスすべきでない情報にアクセスしないことを保証します。
HTTP JSON クエリの書き方
HTTP JSON データソースのクエリは、以下のプロパティを含むオブジェクトです: path、method、bodyJson、extractors。
path: データソースへの URL パスqueryParams: (オプション)リクエストを作成するときに URL に追加するキーと値のペアのマップ(例: “query”: “something” は ?query=something をpathに追加します)。このマップが空でない場合、クエリパラメーターはpathで指定しないでください。method: リクエストを行うための HTTP メソッド。サポートしているメソッドは GET、POST、DELETE、PUT です。bodyJson: (オプション)API エンドポイントにデータとして送信される JSON (例えば、データの形式や集計方法)。データソースのエンドポイントが JSON を期待していない場合、このフィールドは必要ありません。extractors: クエリが返す結果。何を抽出するかを決定するために JSONPath ↗ を使用します。例えば、全体の結果を見るには"result": "$"を使用します。JSONPath の書き方については、以下の tester ↗ を参照してください。JSONPath の詳細については JSONPath examples ↗ を参照してください。headers: (オプション)リクエストに設定するヘッダーのマップ。認証ヘッダーが存在する場合、このリストの上に追加されます。
例えば: Elasticsearchについての詳細は、Query DSL documentation ↗をご覧ください。
サービスAPI
SERVICEAPIデータソースタイプは、パブリックAPIをSlate開発者向けに利用可能にしたFoundryサービスに特化したものです。利用可能なサービスはFoundryインスタンスにより異なる可能性がありますが、一般的にはBuild Service、Compass、またはCatalog Serviceが含まれます。
各サービスAPIが追加されると、そのAPIのドキュメンテーションがインラインで表示されます。ペイロードタイプの具体的な例は、request入力の隣にある_Show Details_トグルの後ろにしばしば見つけることができます。これらのエンドポイントは、プレーンなHTTPJSONデータソースタイプクエリとは異なる方法で保護されているため、ハンドルバー入力を{{jsonstringify}}する必要はありません。
あなたのアプリケーションのために開発したいFoundryの統合がある場合は、あなたのPalantir担当者に連絡してください。
クエリ部分
クエリ部分を使用すると、ドキュメント内の複数のクエリで再利用できるクエリコードを書くことができます。部分を作成するには、Queries Editorパネルで**+ New Partial**ボタンをクリックします。
部分をクエリに挿入するには、{{>partialName}}と書きます。例えば、columnFilterという名前の部分があり、その内容がWHERE column={{param w8.selectedValue}}であるとします。次に、SELECT * from table {{>columnFilter}}というコードで別のクエリを作成できます。これはクエリSELECT * from table WHERE column={{param w8.selectedValue}}にレンダリングされます。
部分に引数を渡すこともでき、その構文は{{>partialName arg1=value1 arg2=value2 arg3=value3}}となります。部分のコンテキスト内の引数の値は、特定のクエリで提供する値に置き換えられます。値は静的な値(文字列や数値など)やHandlebars参照(w8.selectedValueなど)が可能です。上記の例では、2つのクエリが全く同じで、ただフィルター処理が2つの異なる選択値によって行われていた場合、columnFilterをWHERE column={{param columnValue}}に再定義し、クエリをSELECT * from table {{>columnFilter columnValue=w8.selectedValue}}にすることで、SELECT * from table WHERE column={{param w8.selectedValue}}としてレンダリングされる、という前と同じ結果を得ることができます。
部分をネストすることもできます。これにより、コードの再利用内でのコードの再利用が可能となります。
部分はHandlebarsの概念であり、Slateの実装はHandlebarsの構文を使用しています。詳細については、Handlebars部分のドキュメンテーション↗をご覧ください。
条件付きクエリ
クエリ設定パネルでは、クエリの実行条件を制御することができます。クエリを条件付きで実行するための2つのオプションがあり、all dependencies are not nullを選択すると、クエリ内のすべてのハンドルバーレファレンスがnullでないことが、クエリが実行されるための条件となります。また、only run when this returns true:を選択すると、ハンドルバーコンディションを指定することができます。この条件は、関数への参照、ウィジェットのプロパティ、またはクエリが実行可能な時期を制御するためのロジックなど、任意のものにすることができます。クエリは、このハンドルバーレファレンスが真と評価された場合にのみ実行されます。それ以外の場合、クエリは実行されません。

例1: all dependencies are not null
以下のクエリは、w_visits_bar.selection.dataから少なくとも1つの値が必要です。

値が存在しない場合、Postgresへのリクエストは構文エラーで失敗します。

すべての依存関係がnullでない場合にのみ実行するという条件を追加すると、Postgresに送られる既知の不良リクエストが防止され、それ以外の場合は接続とリソースを消費します。
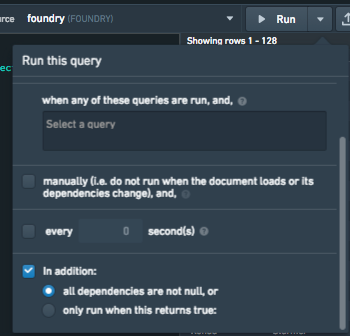
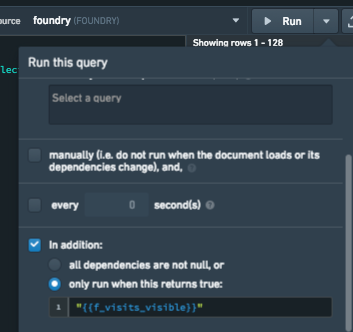
例2: only run when this returns true
以下のクエリは、タブ化されたコンテナ内のウィジェットを埋めるために使用されるデータを取得します。このウィジェットはページの読み込み時には表示されず、ページレベルのフィルターに依存しているとします。この特定のケースでは、ウィジェットが表示されているときにのみクエリを実行する条件を追加することを検討するかもしれません。これは、クエリ設定でonly run when this returns trueオプションを使用して行うことができます。

チュートリアル: Slateでデータを利用可能にする
可能な限りSlateのPlatformタブのObject Set Builderを使用してデータをロードすべきです。Object Set Builderを使用すると、オントロジーを簡単にクエリすることができ、下に示す例のような表形式のデータを返します。以下に説明するPostgresのワークフローは、旧来の使用法の参照として残されています。
新しいデータを同期するための以下の手順を進める前に、Foundry Training and Resources Projectが利用可能かどうかを確認してください。これは、左サイドバーのProjects & filesの下のProjectsビューを閲覧することで確認できます。
プロジェクトが利用可能であれば、以下の手順に従い、Foundry Reference ProjectのOntology Project: Aviationフォルダーからflightsおよびairportsデータセットを新しいアプリケーションに追加します。チュートリアルの残りの手順では、last-mile-flightsデータセットの代わりにflightsデータセットを使用します。
Foundry Reference Project内のflightsおよびairportsデータセットにはすでに同期が設定されているはずです。これらのデータセットを使用する場合は、下記の関連する指示セクションをスキップできます。
Foundry Reference Projectの既存のflightsおよびairportsデータセットを使用していない場合、Foundryにアップロードしたlast-mile-flightsおよびairportsデータセットをSlateで使用できるようにする必要があります。Datasetsパネルを開き、+Addを選択してFoundryリソースセレクターを開きます。
All Files > Getting started dataを選択してlast-mile-flightsデータセットに移動するか、リソースセレクターの検索ボックスを使用します。データセットを見つけたら、Select last-mile-flightsオプションを選択してインポートの設定を始めます。
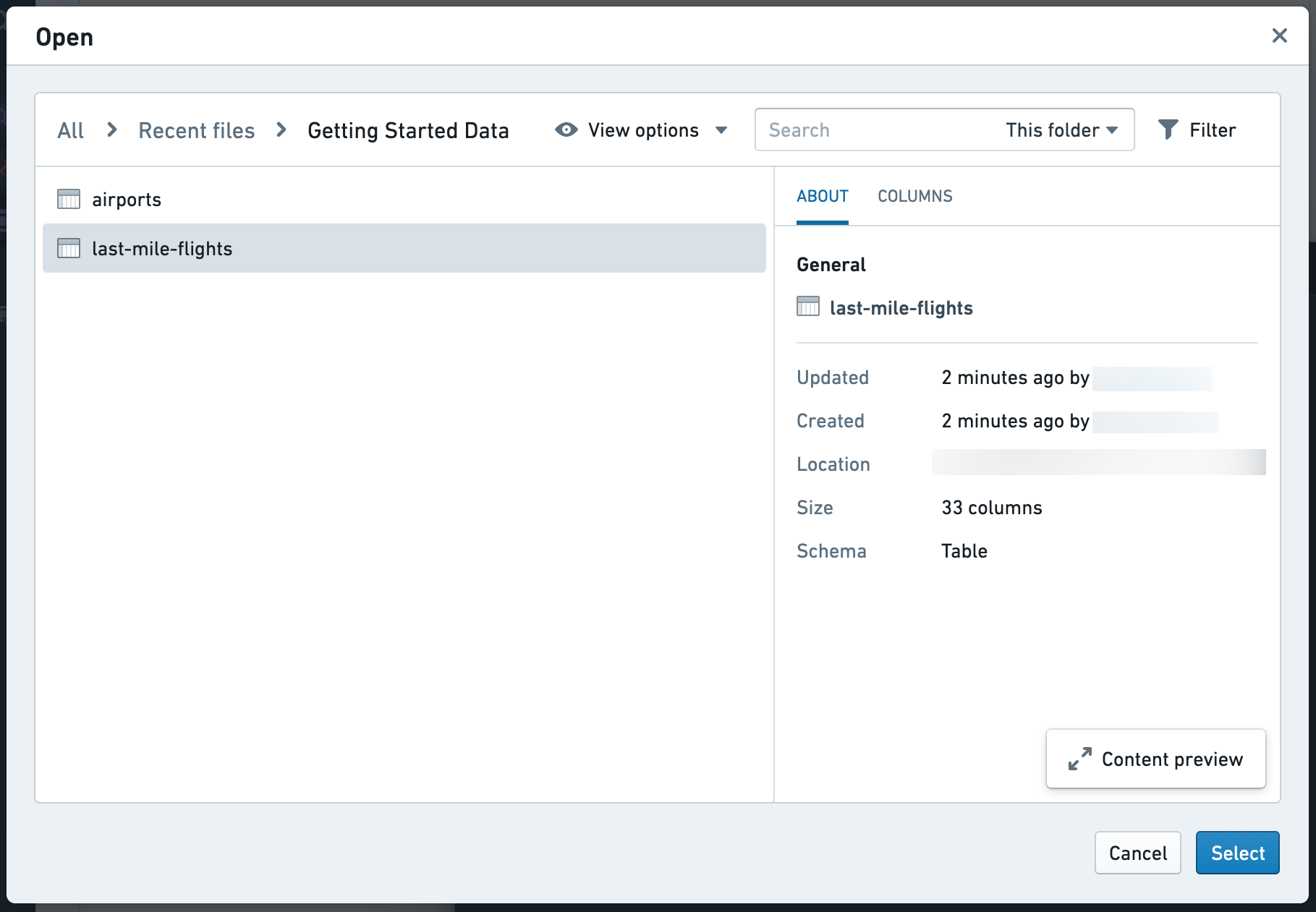
設定オプションを表示するには、Sync to Postgresの隣の矢印を選択します。
Postgresでのデフォルトのテーブル名には、ファイルパスと混合ケースのデータセット名が含まれます。特殊文字/、大文字、スペースを扱うために、Postgresはテーブル名を引用符で囲んだ識別子として扱います。これは、テーブルがクエリで参照されるたびに、ダブルクォートを含めなければPostgresが構文エラーをスローすることを意味します。設定にPostgresql table nameを含めることをお勧めします。これは、スネークケース、小文字、_であり、ダブルクォートの使用を避けるためのものです。
データアクセスパターンがまだ定義されておらず、last-mile-flightsデータセットは比較的小さいため、テーブルにインデックスを作成することはありません。これらは後から追加することができます。Apply and syncを選択して同期を開始します。Check Statusボタンを使用して同期の状況を確認できます。
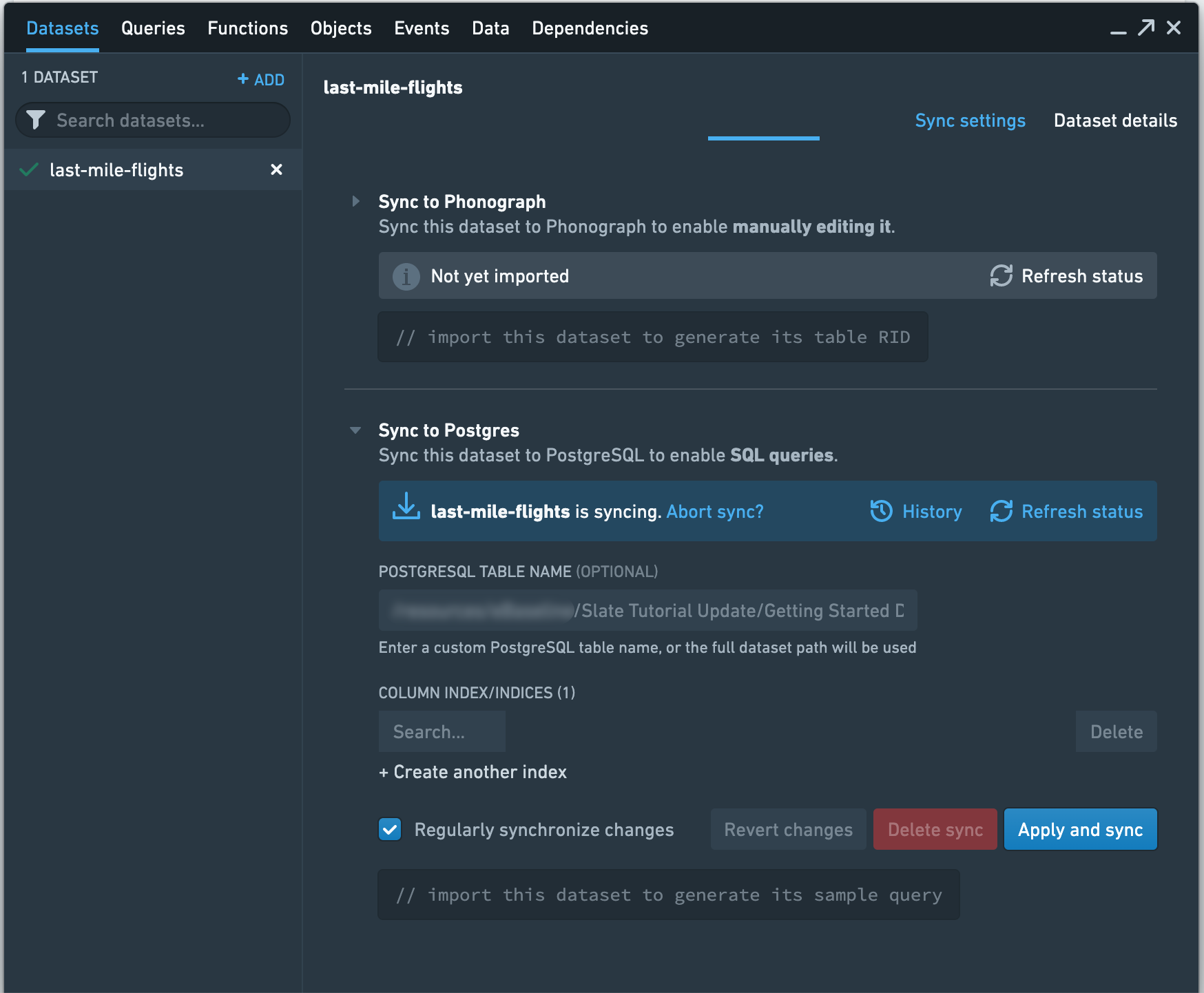
同期が完了すると、Slateで使用するためのサンプルクエリが表示されます。ただし、データセット名に追加される番号は異なる可能性があります: